FastSwitch: Revolutionizing Complex LLM Workloads with Advanced Token Generation and Priority-Based Resource Optimization
Large Language Models (LLMs) are at the heart of modern AI systems, enabling applications such as language translation, virtual assistants, code generation, and more. Despite their transformative impact, LLMs face significant challenges when deployed in high-demand, multi-user environments. Resource constraints, high computational costs, and latency issues often hinder their scalability and efficiency. Addressing these challenges requires innovations that ensure fairness, optimize resource allocation, and reduce latency.
Enter FastSwitch, a revolutionary fairness-aware serving system designed to handle complex LLM workloads. Developed by researchers from Purdue University, Shanghai Qi Zhi Institute, and Tsinghua University, FastSwitch introduces novel mechanisms to enhance token generation efficiency and manage resources more effectively. This system promises to redefine how LLMs operate under high-stress, multi-user scenarios, delivering superior performance and user experience.
Challenges in Current LLM Workload Management
LLMs rely heavily on GPUs with high-bandwidth memory to manage the substantial computational demands of large-scale tasks. However, deploying LLMs at scale introduces critical challenges:
1. Resource Allocation and Fairness
Existing systems prioritize throughput at the expense of fairness, leading to significant variations in latency among users. Multi-user environments require dynamic resource allocation that balances fairness and efficiency.
2. Context-Switching Overheads
Preemptive scheduling mechanisms, which adjust request priorities in real-time, often cause inefficiencies like:
- GPU idleness due to frequent context switching.
- Inefficient I/O utilization, which degrades performance metrics such as Time to First Token (TTFT) and Time Between Tokens (TBT).
3. Memory Management Limitations
Traditional paging-based memory management, such as the approach used in vLLM, struggles with:
- Fragmented memory allocation.
- Redundant data transfers during multi-turn conversations.
- Suboptimal bandwidth utilization, which increases latency.
These challenges emphasize the need for an innovative solution that minimizes overhead, optimizes resource utilization, and maintains fairness in LLM serving systems.
What is FastSwitch?
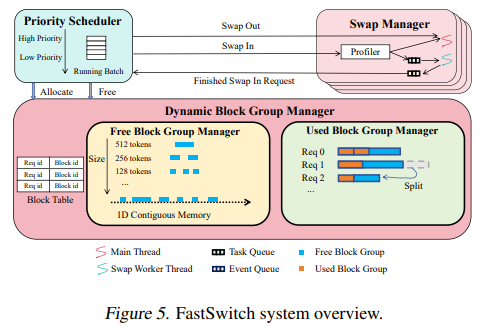
FastSwitch is a fairness-aware LLM serving system that introduces three core optimizations to overcome the limitations of existing solutions:
- Dynamic Block Group Manager: Optimizes memory allocation by grouping contiguous blocks to increase transfer granularity and reduce latency.
- Multithreading Swap Manager: Enhances token generation efficiency through asynchronous swapping, mitigating GPU idle time.
- KV Cache Reuse Mechanism: Reduces preemption latency by reusing partially valid cache data, minimizing redundant data transfers.
These components work together to ensure seamless operation, improve fairness, and enhance performance under high-demand conditions.
Core Features of FastSwitch
1. Dynamic Block Group Manager
This innovation addresses the inefficiencies of fragmented memory allocation. By grouping contiguous memory blocks, the dynamic block group manager:
- Increases transfer granularity, improving I/O bandwidth utilization.
- Reduces context-switching latency by up to 3.11x compared to existing systems.
2. Multithreading Swap Manager
The multithreading swap manager enables asynchronous operations, which:
- Enhance token generation efficiency by reducing GPU idle time.
- Achieve a 21.8% improvement in P99 latency through fine-grained synchronization and conflict mitigation during overlapping processes.
3. KV Cache Reuse Mechanism
This mechanism preserves partially valid cache data in CPU memory, avoiding redundant KV cache transfers. Benefits include:
- 53% reduction in swap-out blocks, significantly lowering preemption latency.
- Efficient reuse of cached data, enabling smoother transitions during context switches.
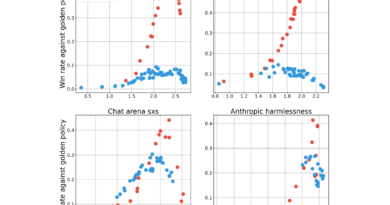
Performance Benchmarks
The researchers evaluated FastSwitch using the LLaMA-8B and Qwen-32B models on GPUs like NVIDIA A10 and A100. Key findings include:
1. Latency Reduction
- TTFT: Achieved speedups of 4.3-5.8x at the P95 percentile.
- TBT: Reduced latency by 3.6-11.2x at the P99.9 percentile.
2. Improved Throughput
FastSwitch enhanced throughput by up to 1.44x, demonstrating its ability to handle complex workloads efficiently.
3. Enhanced Resource Utilization
- Improved I/O bandwidth utilization by 1.3x.
- Reduced GPU idle time by 1.42x, ensuring optimal hardware usage.



How FastSwitch Compares to Existing Solutions
| Feature | FastSwitch | vLLM | Traditional Systems |
|---|---|---|---|
| Memory Allocation | Dynamic block grouping for efficiency | Fixed block size (16 tokens) | Fragmented and static allocation |
| Latency | Up to 11.2x reduction in TBT | Moderate improvement | High due to context-switching |
| Token Generation | Multithreaded, asynchronous swapping | Single-threaded | Limited by GPU idleness |
| Fairness | Priority-based, fairness-aware | Basic priority handling | Neglects fairness |
| KV Cache Management | Efficient reuse, 53% fewer swap-outs | Redundant transfers | Inefficient cache utilization |
FastSwitch clearly outperforms existing solutions by combining fairness, efficiency, and scalability.
Applications of FastSwitch
FastSwitch’s innovative architecture makes it ideal for a variety of applications:
1. High-Throughput AI Services
- Virtual assistants and chatbots.
- Real-time language translation systems.
2. Multi-User Environments
- Collaborative tools requiring low latency and fairness among users.
- Large-scale deployments in industries like customer service and healthcare.
3. Research and Development
- Testing and training of LLMs in environments with fluctuating workloads.
- Exploratory analysis requiring high-priority query handling.
Key Takeaways
FastSwitch introduces transformative innovations to address the inefficiencies of LLM serving systems. Key takeaways include:
- Dynamic Block Group Manager: Increased I/O bandwidth utilization, reducing latency by up to 3.11x.
- Multithreading Swap Manager: Enhanced token generation efficiency with a 21.8% improvement at P99 latency.
- KV Cache Reuse Mechanism: Reduced swap-out volume by 53%, significantly lowering preemption latency.
- Scalability: Robust performance across diverse models and workloads, showcasing its versatility.
Conclusion
FastSwitch represents a significant advancement in handling complex LLM workloads. By addressing inefficiencies in memory management, token generation, and context switching, it delivers unparalleled performance and scalability. Its ability to balance fairness and efficiency makes it an essential tool for modern AI applications, ensuring high-quality service delivery in demanding, multi-user environments.
As LLMs continue to shape the future of AI, solutions like FastSwitch will play a pivotal role in enabling their widespread adoption and utility. With its innovative design and transformative impact, FastSwitch sets a new standard for resource management and performance optimization in LLM deployments.
Check out the Paper. All credit for this research goes to the researchers of this project.
Do you have an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3800+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on LLMs 😁
If you like our work, you will love our Newsletter 📰