Meet MobileVLM: A Competent Multimodal Vision Language Model (MMVLM) Targeted to Run on Mobile Devices
In the rapidly advancing field of artificial intelligence, a revolutionary development called MobileVLM has emerged. MobileVLM, short for Mobile Vision Language Model, is a highly competent multimodal model designed specifically to run on mobile devices. This cutting-edge technology represents a significant breakthrough in integrating AI capabilities into everyday mobile technology.
Addressing Challenges in Vision and Language Integration
One of the primary challenges in the field of AI is effectively combining vision and language capabilities for tasks such as visual question answering and image captioning. MobileVLM aims to tackle these challenges by providing a seamless integration of language models with vision models, specifically optimized for mobile devices.
Traditionally, the integration of large language models with vision models has been hindered by the requirement for vast amounts of data. This proved to be a significant barrier for developing text-to-video generating models. However, MobileVLM addresses this limitation by leveraging regulated and open-source datasets, allowing for the construction of high-performance models without being constrained by data availability [1].
Architecture and Components of MobileVLM
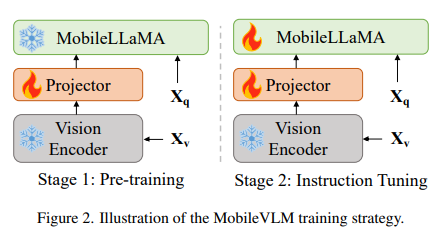
MobileVLM is built on an advanced architecture that combines innovative design principles with practical applications for efficient and reliable performance. The model consists of three main components:
- Visual Encoder: The visual encoder is responsible for processing images or visual inputs. It extracts relevant visual features and encodes them into a suitable format for further processing.
- Language Model for Edge Devices: This component is specifically designed to optimize language processing on mobile devices. It takes the output from the visual encoder and generates meaningful textual representations.
- Efficient Projector: The efficient projector is a crucial component that aligns the visual and textual features, ensuring a cohesive multimodal representation. It minimizes computational costs while preserving spatial information, thereby enhancing inference speed without compromising output quality.
The combination of these components enables MobileVLM to seamlessly integrate vision and language processing in a manner that is tailored to the computational and resource limitations of mobile devices.

Training MobileVLM: A Comprehensive Approach
The training process of MobileVLM involves three essential stages, ensuring the model’s efficiency and robustness in performance.
- Pre-training: The foundation models of MobileVLM are initially pre-trained on text-only datasets. This step lays the groundwork for language understanding and processing capabilities.
- Supervised Fine-tuning: The model is then fine-tuned using supervised learning on multi-turn dialogues between humans and advanced language models like ChatGPT. This stage enhances MobileVLM’s language generation and reasoning abilities.
- Vision Model Training: In the final stage, the vision models are trained using multimodal datasets that combine visual and textual information. This comprehensive training strategy ensures MobileVLM’s ability to process and understand both vision and language inputs effectively.
By employing this training approach, MobileVLM achieves exceptional performance on language understanding and common sense reasoning benchmarks. It competes favorably with existing language models and delivers impressive results, despite relying on reduced parameters and limited training data.

Advantages and Potential of MobileVLM
MobileVLM stands out for several reasons, making it an exciting development in the field of multimodal vision language models:
- Mobile-Optimized Performance: With its specifically designed components and efficient architecture, MobileVLM delivers excellent performance on mobile devices. It minimizes computational costs while maintaining high-quality results, ensuring a seamless user experience.
- Resource Efficiency: By leveraging open-source datasets and employing innovative training approaches, MobileVLM overcomes the limitations posed by data scarcity. It enables the development of high-performance models without the need for extensive training data.
- Integration into Everyday Technology: MobileVLM’s compatibility and optimization for mobile devices open up a wide range of possibilities for its application. From mobile apps and augmented reality to voice assistants, MobileVLM can enhance various aspects of everyday life and technology.
- Extensive Use Cases: The integration of vision and language processing allows for a diverse set of use cases, including visual question answering, image captioning, and real-time language translation on mobile devices. MobileVLM’s versatility makes it a valuable tool in multiple domains.
As the capabilities of AI continue to expand, MobileVLM represents a significant advancement in merging the potential of vision and language processing on mobile devices. Its optimized performance, resource efficiency, and extensive use cases position MobileVLM as a notable contender in the field of multimodal vision language models.
In conclusion, MobileVLM’s emergence as a competent multimodal vision language model targeted for mobile devices signifies a major step forward in unlocking the full potential of AI on smaller, resource-constrained platforms. Its architecture, training approach, and performance metrics showcase the efficacy and potential of this technology. As more researchers and developers explore the possibilities of MobileVLM, we anticipate further breakthroughs and innovative applications in the near future.