NeuScraper: Revolutionizing Web Scraping for Enhanced Large Language Model Pretraining
Have you ever wondered how large language models like GPT-3 are trained? These models require vast amounts of data to learn from, but finding clean and usable training data on the web can be like searching for treasure amidst chaos. The traditional methods of web scraping, using rule-based and heuristic approaches, often result in noisy and low-quality data. However, a groundbreaking solution has emerged to address this challenge – NeuScraper.
The Need for Clean Data in Large Language Model Pretraining
Large Language Models (LLMs) have become the backbone of many natural language processing (NLP) applications, ranging from chatbots and virtual assistants to language translation and sentiment analysis. These models are trained on massive datasets to learn patterns and generate coherent and contextually relevant text. However, the quality of the training data plays a crucial role in the performance of these models.
The web is a rich source of data for training LLMs, but it is also cluttered with extraneous content such as advertisements, pop-ups, and irrelevant hyperlinks. Traditional web scraping tools struggle to differentiate between the core content and the noise, resulting in the collection of noisy and irrelevant data. This dilutes the quality of the training sets and hampers the performance of LLMs.
Introducing NeuScraper: A Neural Network-Based Solution
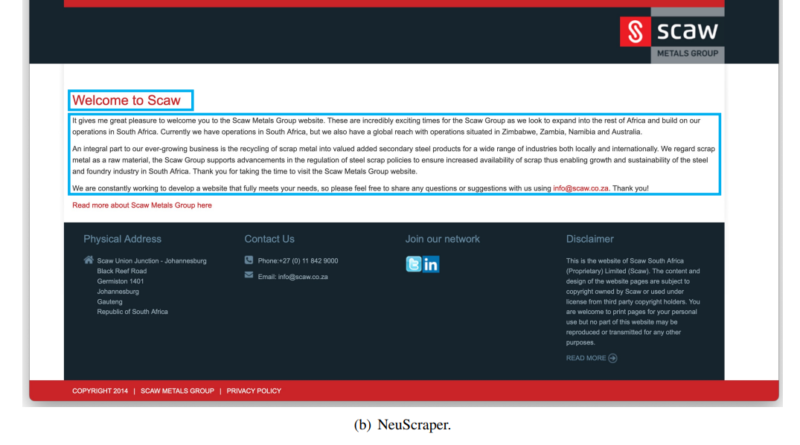
NeuScraper is an innovative web scraping solution developed by researchers from Northeastern University, Tsinghua University, China Beijing National Research Center for Information Science and Technology, and Carnegie Mellon University. It offers a neural network-based approach to extracting clean and valuable data for LLM pertaining.
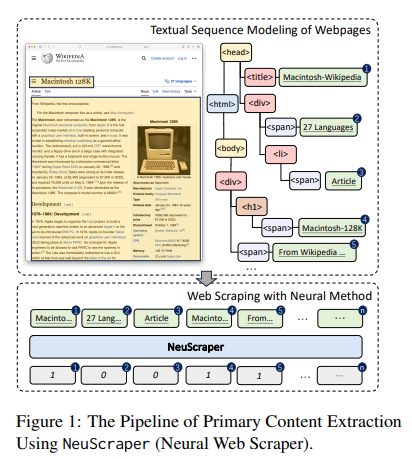


Unlike rule-based and heuristic approaches, NeuScraper leverages the power of neural networks to analyze both the structure and content of webpages. This allows NeuScraper to accurately identify and classify the primary content blocks, separating them from the noise and distractions. By analyzing features such as linguistic cues, structural elements, and visual patterns, NeuScraper can extract high-quality data with unprecedented precision.
The Architecture of NeuScraper
NeuScraper’s architecture revolves around the concept of dissecting webpages into blocks and analyzing them using a shallow neural model. This model is specifically trained to understand the layout and structure of webpages, enabling it to identify and classify the primary content blocks accurately.
The neural model in NeuScraper takes into account various features extracted from the blocks, including linguistic cues like word frequency and semantic similarity, structural cues like headings and paragraphs, and visual cues like font size and color. All these features work in tandem to provide a holistic view of the webpage’s content, allowing NeuScraper to extract the most relevant and valuable data.
Unprecedented Performance Improvement
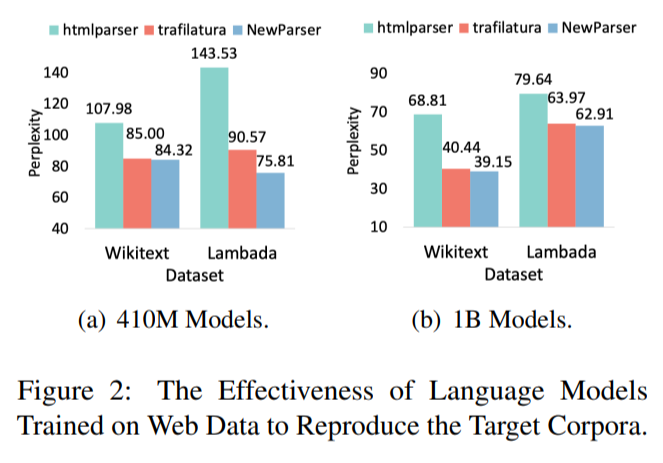
One of the most remarkable aspects of NeuScraper is its performance improvement over existing scraping technologies. In comparative evaluations, NeuScraper demonstrated a staggering 20% improvement in data quality, showcasing its ability to clean and filter noise from the scraped data. This breakthrough paves the way for more accurate and reliable large language model pretraining.
With the enhanced efficiency of NeuScraper, researchers and developers can tap into the vast resources available on the web more effectively. By curating high-quality datasets for LLM pretraining, NeuScraper opens up new possibilities for advancements in NLP and related fields.
The Future of Web Scraping and LLM Pretraining
NeuScraper represents a significant leap forward in the field of web scraping for LLM pretraining. Its neural network-based approach revolutionizes the extraction of clean and valuable data from the web. By addressing the challenges of noise and irrelevance, NeuScraper empowers researchers and developers to train large language models with higher accuracy and performance.
The implications of NeuScraper’s advent are manifold. It not only enhances the capabilities of existing large language models but also enables the development of more sophisticated and contextually aware models. Moreover, NeuScraper’s innovative approach to web scraping can be extended to other domains, such as data mining, information retrieval, and content curation.
In conclusion, NeuScraper is pioneering the future of web scraping for enhanced large language model pretraining. With its neural network-based approach, NeuScraper offers a game-changing solution to the challenges of extracting clean and valuable data from the web. As the field of NLP continues to evolve, NeuScraper will undoubtedly play a crucial role in driving advancements and pushing the boundaries of what is possible with large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰