Revolutionizing Information Retrieval: How the FollowIR Dataset Enhances Models’ Ability to Understand and Follow Complex Instructions
Information Retrieval (IR) is a crucial aspect of modern technology that enables users to extract relevant information from vast datasets. Over the years, IR systems have made significant advancements, enhancing search capabilities and semantic understanding. However, there is still a persistent challenge in the interaction between users and retrieval systems. Existing models often overlook the potential of utilizing detailed user instructions to refine search outcomes, limiting their ability to understand and follow complex instructions.
To address this limitation, a team of researchers from Johns Hopkins University, Allen Institute for AI, University of Glasgow, and Yale University have introduced the “FollowIR” dataset and benchmark. This novel approach aims to enhance IR models’ capacity to interpret and follow detailed user instructions, harnessing the power of large language models (LLMs) in understanding complex search intents.
Introducing the FollowIR Dataset
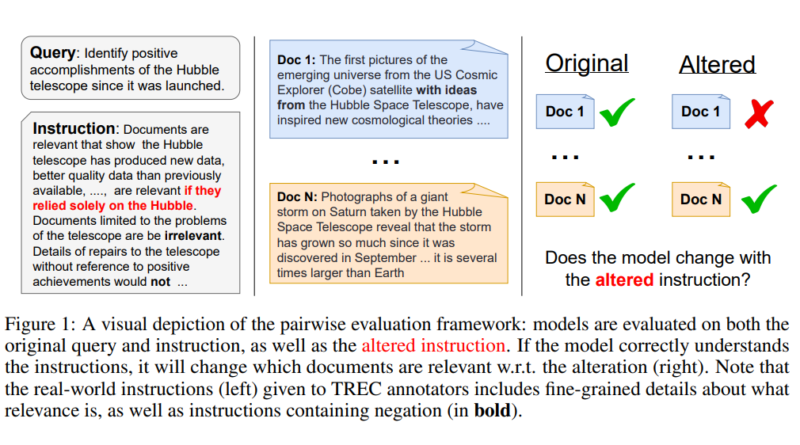
The FollowIR dataset integrates three TREC (Text REtrieval Conference) collections: TREC News 2021, TREC Robust 2004, and TREC Common Core 2017. These collections provide a rich source of instructions for IR models to learn from. Expert annotators refine TREC instructions, focusing on documents initially marked relevant, effectively narrowing down the pool of relevant documents for select queries from TREC Robust 2004 and TREC News 2021.
Evaluating Instruction-Following Ability
The evaluation of instruction-following in IR models is conducted using standard retrieval metrics and a novel metric called p-MRR (rank-wise shifts between queries). This comprehensive evaluation approach takes document ranking into account and provides a score range. The results are averaged per query and across the dataset, with data presented in 400-word segments, adhering to the MTEB (Multiple Text Evaluation Benchmark) framework for distribution.
Several models were evaluated in this benchmark, including BM25, BGE-base, E5-base-v2, TART-Contriever, and INSTRUCTOR-XL. These models were segmented into categories based on their training, including no instructions, instructions in IR, API models, and instruction-tuned LLMs. The results showed that large models and those tuned for instruction adherence exhibited notable success in following instructions. However, API models, which heavily rely on keyword-based queries, struggled with instruction following. This highlights the importance of incorporating detailed user instructions for better search outcomes.
Advantages of Instruction-Tuned LLMs
Among the evaluated models, instruction-tuned LLMs, particularly the FOLLOWIR-7B model, demonstrated significant improvement in standard retrieval metrics and instruction adherence. These models were specifically designed and trained to understand complex user instructions. The success of instruction-tuned LLMs highlights their potential in revolutionizing information retrieval, enabling more precise and context-aware search capabilities.
Overcoming Challenges in Detailed Instruction Comprehension
The evaluation also uncovered a trend of challenges in instruction comprehension, particularly for models optimized for keyword search. These models struggled with understanding and following detailed directives, indicating a gap in their ability to handle complex instructions. While the evaluation focused on the FollowIR dataset, the consistent findings across various datasets suggest a broader challenge in instruction comprehension within the field of IR.
Implications and Future Directions
The introduction of the FollowIR dataset and benchmark represents a significant step towards enhancing the instruction-following ability of IR models. The evaluation results emphasize the need for models to incorporate detailed user instructions to improve search outcomes. Instruction-tuned LLMs, such as the FOLLOWIR-7B model, showcase the potential for significant advancements in standard retrieval metrics and instruction adherence.
While the FollowIR dataset and benchmark offer valuable insights, there are limitations to consider. Challenges include reranking versus full retrieval approaches and potential annotation errors. However, this research lays the foundation for developing advanced IR models capable of adapting to complex user instructions through natural language.
In conclusion, the FollowIR dataset revolutionizes information retrieval by enhancing models’ ability to understand and follow complex instructions. By leveraging detailed user instructions and training models to interpret them, IR systems can provide more accurate and context-aware search results. The FollowIR benchmark not only highlights the success of instruction-tuned LLMs but also sheds light on the challenges faced by models optimized for keyword search. This research opens up new possibilities for the development of advanced IR models that can better serve users’ needs in the era of complex information landscapes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰