University of Maryland’s Automatic Text Privatization Framework Enhances Online Privacy
In today’s digital age, privacy is a growing concern for individuals who engage in online activities. With the rapid advancement of technology, it has become easier for others to track and identify individuals based on their online presence. To address this issue, researchers from the University of Maryland have developed an automatic text privatization framework that utilizes reinforcement learning to fine-tune a large language model. This framework aims to balance privacy protection, text coherence, and readability, offering a more advanced and practical solution for masking authorship in online conversations.
The Importance of Online Privacy

Online privacy is crucial for individuals to feel safe and comfortable when participating in virtual spaces. In the past, platforms like Reddit adopted the use of pseudonyms to allow users to post under fictitious names, providing a certain level of anonymity. However, research on stylometry, the study of language style, has shown that even anonymous posts can be linked to their authors based on writing patterns and stylistic elements. This raises concerns about the vulnerability of individuals, particularly those in marginalized groups, who may face repercussions if their true identities are revealed.
Authorship Obfuscation Techniques
To protect individuals’ privacy in online conversations, authorship obfuscation techniques have been developed. These techniques automatically rewrite text to obscure the identity of the original author, making it more difficult to track and link posts to specific individuals. However, conventional methods of obfuscation have often been limited and relied on basic, surface-level modifications, resulting in unnatural and odd writing styles.
Introducing the Automatic Text Privatization Framework
The researchers from the University of Maryland have introduced an automatic text privatization framework that goes beyond surface-level modifications. This framework fine-tunes a large language model using reinforcement learning to produce rewrites that strike a balance between privacy protection, text coherence, and readability. By leveraging a sizable language model and refining it through reinforcement learning, the framework ensures that the revised text maintains its meaning and naturalness while concealing the author’s identity.
Evaluating the Effectiveness
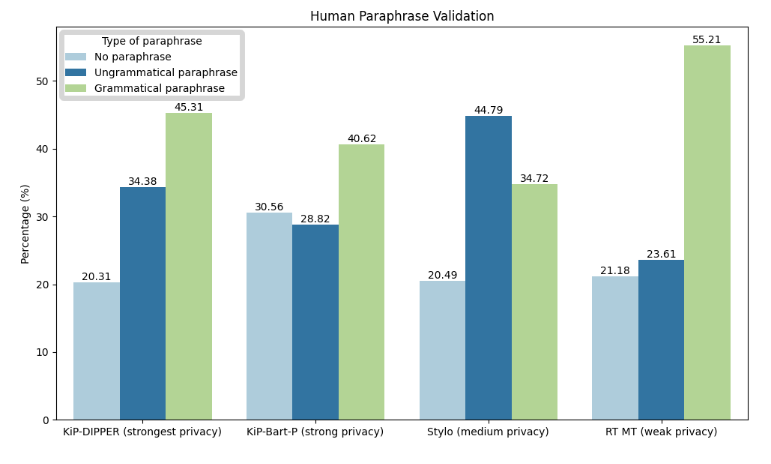
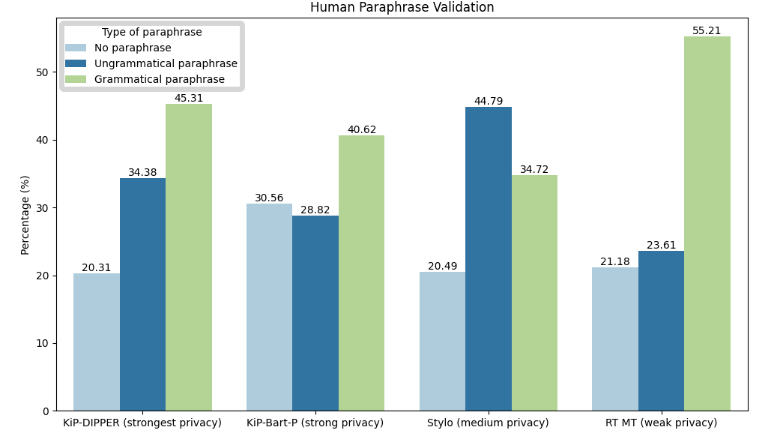
To evaluate the effectiveness of the automatic text privatization framework, the researchers conducted a thorough evaluation using a vast dataset of English posts from Reddit. The dataset included texts from 68,000 authors, varying in length and reflecting the typical content found on internet discussion boards. The study analyzed the performance of the obfuscation approach based on authorship detection strategies and the length of the author’s profile.
Both automatic measurements and human reviews were conducted to assess the text quality of the revised content. The results demonstrated that the automatic text privatization framework maintains good text quality, ensuring that readers can understand and relate to the revised text. Furthermore, the framework successfully evaded several automated authorship attacks, highlighting its reliability in safeguarding user privacy.
Advantages of the Framework
The automatic text privatization framework developed by the University of Maryland researchers offers several advantages over previous approaches. By fine-tuning a large language model using reinforcement learning, the framework achieves a more advanced and practical method of masking authorship. This ensures that individuals can engage in online conversations freely and safely without compromising the quality of their work or their privacy.
Future Implications
The introduction of this automatic text privatization framework opens up possibilities for enhanced privacy protection in various online platforms and communities. As the framework continues to evolve and improve, it could potentially be integrated into existing communication tools to provide users with an added layer of privacy. This could benefit numerous individuals, including those in sensitive situations or marginalized groups, allowing them to express themselves without fear of repercussions.
Conclusion
Privacy in online conversations is a crucial aspect of ensuring individuals’ safety and fostering open communication. The automatic text privatization framework developed by researchers from the University of Maryland offers a significant advancement in authorship obfuscation techniques. By fine-tuning a large language model through reinforcement learning, this framework achieves a balance between privacy protection, text coherence, and readability. Moving forward, the continued development and integration of such frameworks hold great potential in enhancing online privacy and fostering a safer virtual environment for all individuals.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰


