Enhancing Information Retrieval with Large Language Models Using the INTERS Dataset: A Breakthrough Approach
In the rapidly evolving field of artificial intelligence (AI), large language models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. However, applying these models to information retrieval (IR) tasks has remained a challenge due to the scarcity of IR-specific concepts in natural language. To address this limitation, a groundbreaking approach has been introduced by researchers from China, who have developed a novel dataset known as INTERS (INstruction Tuning datasEt foR Search) [1]. This dataset aims to enhance the search capabilities of LLMs, enabling them to excel in IR tasks.
The Need for Instruction Tuning
While LLMs have performed exceptionally well in generalizing to new tasks through instruction fine-tuning, there has been a gap in their application to IR tasks. The key to bridging this gap lies in instruction tuning, a method that involves fine-tuning pre-trained LLMs on formatted instances represented in natural language. Instruction tuning not only enhances the performance of LLMs on directly trained tasks but also enables them to generalize to new, unseen tasks.
The Introduction of the INTERS Dataset
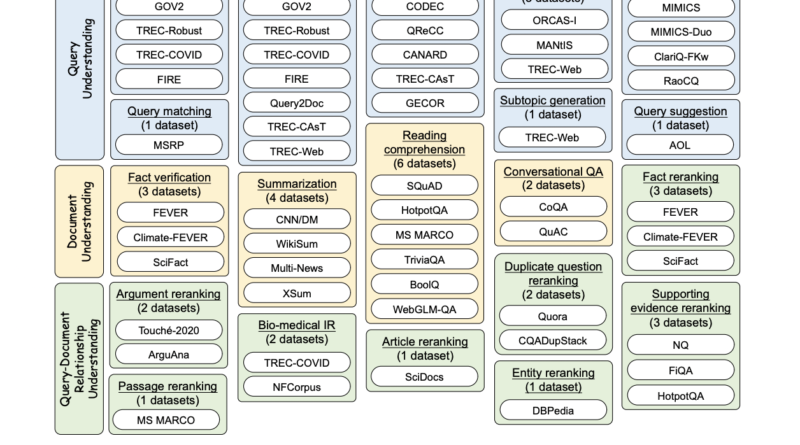
To elevate the search capabilities of LLMs, the researchers have meticulously designed the INTERS dataset. This dataset focuses on three crucial aspects prevalent in search-related tasks: query understanding, document understanding, and the intricate relationship between queries and documents [1]. With a comprehensive collection of 43 datasets covering 20 distinct search-related tasks, INTERS provides a valuable resource for training and evaluating LLMs in the context of IR.
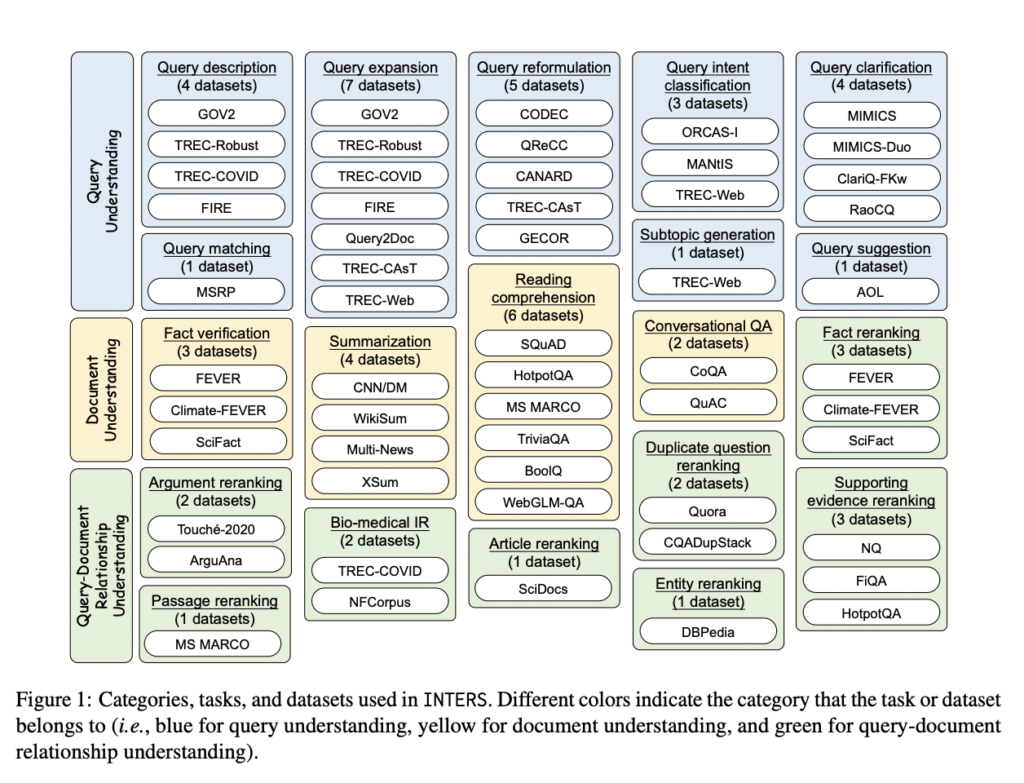


Task Categories and Datasets in INTERS
Developing a comprehensive instruction-tuning dataset for a wide range of tasks is resource-intensive. To overcome this challenge, the researchers have converted existing datasets from the IR research community into an instructional format. The categories of tasks in INTERS include:
- Query Understanding: This category addresses various aspects such as query description, expansion, reformulation, intent classification, clarification, matching, subtopic generation, and suggestion.
- Document Understanding: Encompassing tasks such as fact verification, summarization, reading comprehension, and conversational question-answering, this category focuses on understanding documents in the context of search.
- Query-Document Relationship Understanding: This category primarily focuses on the document reranking task, which involves assessing the relevance and ranking of documents in response to specific queries.
By covering a wide range of tasks and datasets, INTERS provides a comprehensive and instructive dataset for training LLMs.
Evaluating the Effectiveness of Instruction Tuning
To evaluate the effectiveness of instruction tuning on search tasks, the researchers have employed four LLMs of varying sizes: Falcon-RW-1B, Minima-2-3B, Mistral-7B, and LLaMA-2-7B [1]. Through in-domain evaluation, where all tasks and datasets are exposed during training, the researchers have validated the effectiveness of instruction tuning in enhancing the performance of LLMs on search tasks [1]. Furthermore, the researchers have investigated the generalizability of fine-tuned models to new, unseen tasks through group-level, task-level, and dataset-level generalizability analyses.
Impact of INTERS Settings on Model Performance
Several experiments have been conducted to understand the impact of different settings within INTERS on model performance [1]. Notably, the removal of task descriptions from the dataset has been shown to significantly affect model performance, highlighting the importance of clear task comprehension. The use of instructional templates in task comprehension has also been found to significantly improve model performance. Additionally, examining few-shot performance has been crucial, and the dataset’s effectiveness in facilitating few-shot learning has been demonstrated through testing datasets within models’ input length limits [1]. Furthermore, the researchers have explored the impact of training data volume on model performance, with experiments indicating that increasing the volume of instructional data generally enhances model performance.
Conclusion: Advancing the Field of LLMs in IR Tasks
In summary, the introduction of the INTERS dataset and the groundbreaking approach to enhancing information retrieval with LLMs through instruction tuning has opened new avenues in the field of AI. The comprehensive and instructive nature of INTERS, along with the extensive evaluation and analysis conducted by the researchers, has shed light on the structure of instructions, the impact of few-shot learning, and the significance of data volumes in instruction tuning. This work not only provides valuable insights into improving LLM performance in IR tasks but also serves as a catalyst for further research and optimization of instruction-based methods in the domain of LLMs.
The combination of powerful LLMs and the innovative approach introduced by this AI paper from China has the potential to revolutionize information retrieval, enabling more accurate and contextually relevant search results. The INTERS dataset represents a significant step forward in bridging the gap between LLMs and IR tasks, paving the way for future advancements in natural language processing and AI-driven search algorithms.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰