THRONE: Advancing the Evaluation of Hallucinations in Vision-Language Models
Artificial Intelligence (AI) systems have made significant advancements in recent years, particularly in vision-language models (VLVMs). These models integrate text and visual inputs to generate responses, enabling them to perform tasks like image captioning, visual question answering, and more. However, as these models become more complex, a new challenge arises – hallucinations.
Hallucinations in VLVMs refer to the generation of coherent but factually incorrect responses. These hallucinations pose a significant risk, especially in critical applications like medical diagnostics or autonomous driving, where the accuracy of AI systems is paramount.
The Challenge of Hallucinations in Vision-Language Models
Hallucinations in VLVMs typically manifest as plausible yet incorrect details generated about an image. For example, a VLVM might generate a caption for an image of a dog as “a black cat sitting on a chair.” While the response appears coherent, it is factually incorrect.
Existing benchmarks for evaluating hallucinations in VLVMs focus on specific query formats, such as yes/no questions about specific objects or attributes within an image. These benchmarks often fail to measure more complex, open-ended hallucinations that can occur in real-world applications. This limitation creates a gap in understanding and mitigating the broader spectrum of hallucinations that VLVMs can produce.
Introducing THRONE: Evaluating Type I Hallucinations
To address the challenge of hallucination evaluation in VLVMs, researchers from the University of Oxford and AWS AI Labs have introduced a new framework called THRONE (Text-from-image Hallucination Recognition with Object-probes for open-ended Evaluation). THRONE aims to assess Type I hallucinations, which occur in response to open-ended prompts requiring detailed image descriptions
Unlike previous methods, THRONE utilizes publicly available language models to evaluate hallucinations in free-form responses generated by various VLVMs. This approach offers a more comprehensive and rigorous evaluation of hallucinations in VLVMs.
Metrics and Evaluation of Hallucinations
THRONE leverages multiple metrics to quantitatively measure hallucinations across different VLVMs. The framework employs precision and recall metrics alongside a class-wise F0.5 score. The emphasis on precision twice as much as recall is crucial in scenarios where false positives (incorrect but plausible responses) are more detrimental than false negatives.
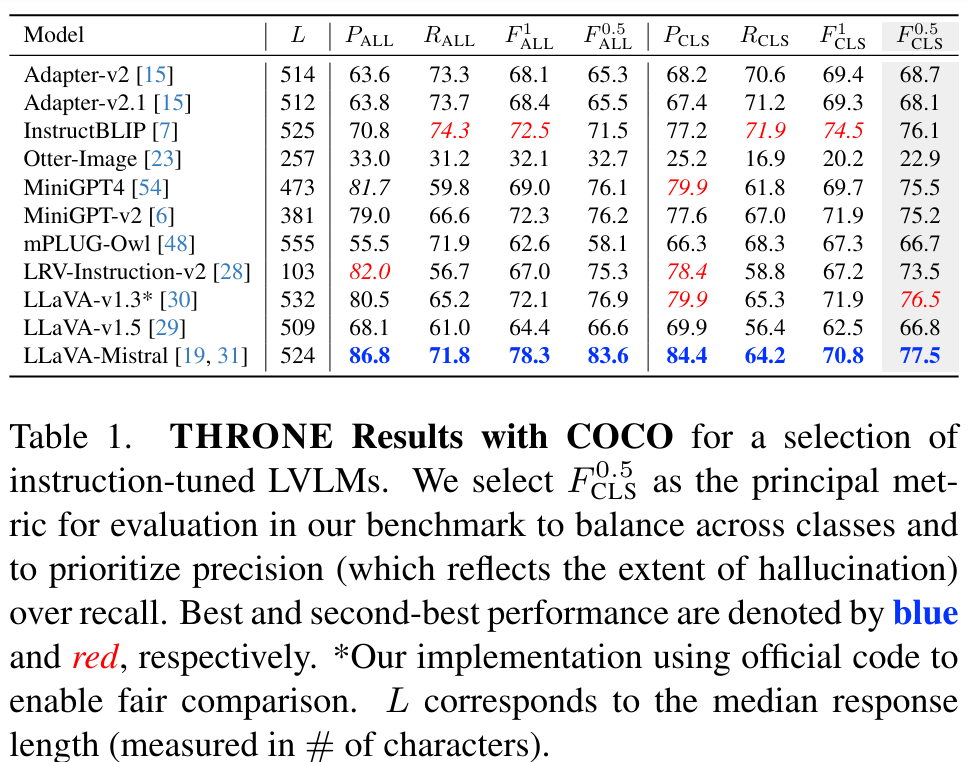
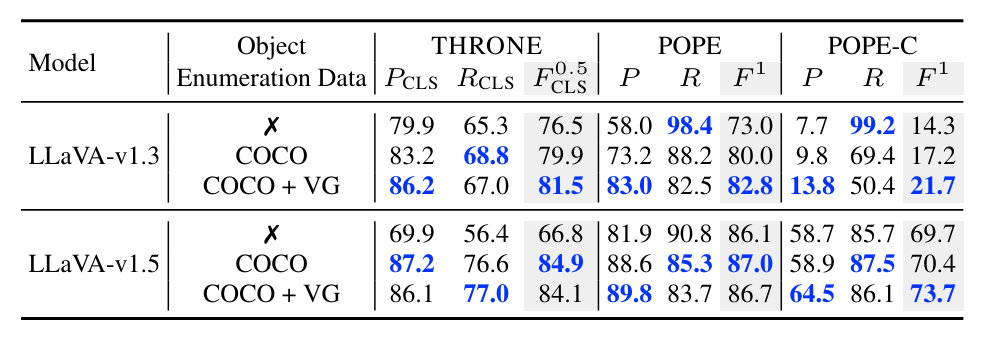
An evaluation of THRONE’s effectiveness has provided valuable insights into the prevalence and characteristics of hallucinations in current VLVMs. The findings indicate that many VLVMs still struggle with a high rate of hallucinations. For instance, the framework detected that some evaluated models produced responses with around 20% of the mentioned objects being hallucinations. These results highlight the persistent challenge of reducing hallucinations and improving the reliability of VLVM outputs.
The Significance of THRONE and Future Research
The introduction of the THRONE framework represents a significant step forward in evaluating hallucinations in vision-language models, particularly addressing Type I hallucinations in free-form responses. Unlike existing benchmarks that struggle to measure more nuanced errors, THRONE utilizes a novel combination of publicly available language models and robust metrics.
However, despite these advances, the high rate of detected hallucinations, around 20% in some models, highlights the ongoing challenges in improving the accuracy and reliability of VLVMs. Further research is necessary to enhance the performance of VLVMs and mitigate hallucinations in critical applications where precision is paramount.
In conclusion, the evaluation of hallucinations in vision-language models is an emerging field of research with significant implications for the reliability of AI systems. The THRONE framework addresses the challenge of hallucination evaluation by introducing a comprehensive approach to assessing Type I hallucinations in free-form responses. With further advancements and research, the accuracy of VLVMs can be improved, ensuring their reliability in crucial applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰