Group Preference Optimization (GPO): A Revolutionary Approach to Aligning Language Models with User Preferences
Language models have become an indispensable tool in various domains, ranging from creative writing to chatbots and semantic search. These models can generate text that aligns with user requirements, but catering to the diverse preferences of different user groups poses a significant challenge. To address this issue, researchers at the University of California, Los Angeles (UCLA) have introduced Group Preference Optimization (GPO), a machine learning-based alignment framework that steers language models to the preferences of individual groups in a few-shot manner. In this article, we will explore the concept of GPO, its key components, and its potential applications.
The Need for Group Preference Optimization
With the increasing use of large language models (LLMs), it has become crucial to align the generated content with the preferences of user groups. Different demographics, cultural norms, and societal backgrounds require tailored text generations that resonate with their specific preferences. However, achieving this alignment is not a straightforward task. Existing alignment algorithms often come with high costs and a dependency on extensive group-specific preference data and computational resources.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Introducing Group Preference Optimization (GPO)
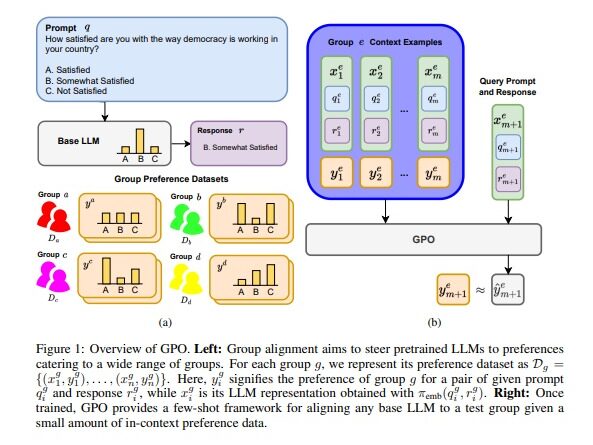
GPO is a novel framework developed by researchers at UCLA to efficiently align LLMs with the preferences of individual groups. The primary objective of GPO is to enable LLM generations that cater to subjective judgments across diverse user demographics. Unlike traditional methods, GPO tackles the challenges associated with alignment by leveraging few-shot learning and meta-learning techniques.
Few-Shot Learning and Meta-Learning
GPO incorporates an independent transformer module, which enhances the base LLM. This module is trained to predict the preferences of specific user groups for LLM-generated content. By parameterizing the module as an in-context autoregressive transformer, GPO enables few-shot learning. This means that the module can adapt to group preferences with minimal data, making it highly efficient.
To train the independent transformer module, GPO utilizes meta-learning on multiple user groups. Meta-learning is a technique that allows models to learn how to learn. In the context of GPO, meta-learning enables the module to rapidly adapt to new preferences by leveraging its knowledge of diverse user groups.
Key Components of GPO
- Independent Transformer Module: The independent transformer module is the core component of GPO. It is responsible for predicting the preferences of user groups and facilitating few-shot learning.
- Meta-Learning: GPO employs meta-learning to train the independent transformer module on multiple user groups. This enables rapid adaptation to new preferences and enhances the efficiency of the alignment process.
Empirical Validation and Performance
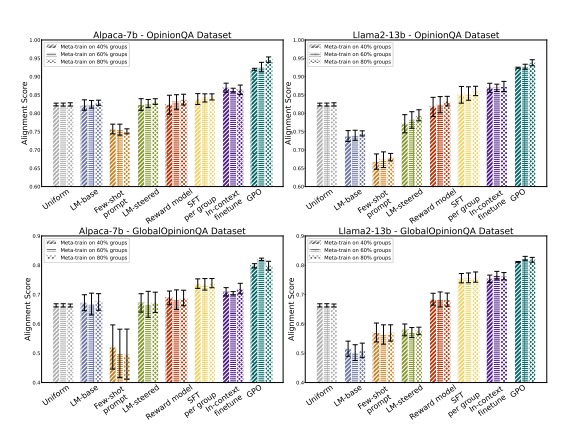
The effectiveness of GPO was evaluated through rigorous empirical validation using LLMs of varying sizes. Three human opinion adaptation tasks were considered: aligning with the preferences of US demographic groups, global countries, and individual users. GPO’s performance was compared with existing strategies such as in-context steering and fine-tuning methods.
The results of the evaluation demonstrated that GPO achieves more accurate alignment with group preferences while requiring fewer group-specific preferences and reduced training and inference computing resources. This highlights the efficiency and effectiveness of GPO in comparison to existing approaches.
Potential Applications of GPO
GPO presents a promising solution for efficiently aligning LLMs with the preferences of diverse user groups. Its ability to adapt to new preferences with minimal data makes it particularly applicable to real-world scenarios where nuanced subjective judgments are essential. Here are some potential applications of GPO:
- Content Generation: GPO can be leveraged to generate content that aligns with the preferences of different user groups. This can be useful in areas such as marketing, where targeted messaging is crucial.
- Chatbots and Virtual Assistants: Chatbots and virtual assistants powered by LLMs can benefit from GPO to tailor their responses to the preferences of individual users. This can enhance user satisfaction and engagement.
- Semantic Search: GPO can be utilized in semantic search systems to align search results with the preferences of specific user groups. This can improve the relevance and personalization of search experiences.
Conclusion
Group Preference Optimization (GPO) is a groundbreaking framework introduced by UCLA researchers that addresses the challenge of aligning language models with the preferences of individual user groups. By leveraging few-shot learning and meta-learning techniques, GPO enables efficient adaptation to diverse preferences with minimal data. The empirical validation of GPO showcases its superiority over existing strategies in terms of accuracy, resource requirements, and performance. With its potential applications in content generation, chatbots, virtual assistants, and semantic search, GPO opens up new possibilities for tailoring text generations to meet the diverse preferences of user groups.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰