Reducing TTFT in LLMs with KV-Runahead: Apple’s Innovative Solution
Large language models (LLMs), such as the highly successful Generative Pre-trained Transformer (GPT) models, have revolutionized natural language processing tasks. These models have demonstrated exceptional performance across various language tasks, including text generation, translation, and sentiment analysis. However, challenges remain in optimizing the inference process of LLMs, particularly in reducing the time-to-first-token (TTFT) and the time-per-output token (TPOT).
In this article, we will explore Apple’s innovative solution called “KV-Runahead,” which proposes an efficient parallel LLM inference technique to minimize the time-to-first-token. We will delve into the details of KV-Runahead, its advantages over existing parallelization methods, and the experimental results that showcase its superior performance.
Understanding the Challenges in LLM Inference
Before diving into the details of KV-Runahead, it is essential to understand the challenges associated with LLM inference. LLM inference consists of two primary phases: the prompt phase and the extension phase.
In the prompt phase, initial tokens are generated based on the user context. This phase heavily relies on extensive user context and poses challenges in minimizing the time-to-first-token (TTFT). The prompt phase is crucial for providing quick responses to user queries.
The extension phase follows the prompt phase and involves using cached key-value (KV) embeddings to expedite subsequent token generation. The goal of the extension phase is to generate tokens rapidly and maintain fluent conversation with the user.
To minimize TTFT for long contexts, efficient KV-cache management and fast attention map computation are vital. Existing optimization approaches, like PagedAttention and CacheGen, have addressed some of these challenges. However, further improvements are necessary to enhance the scalability and load balancing of LLM inference.
Introducing KV-Runahead: An Efficient Parallel LLM Inference Technique
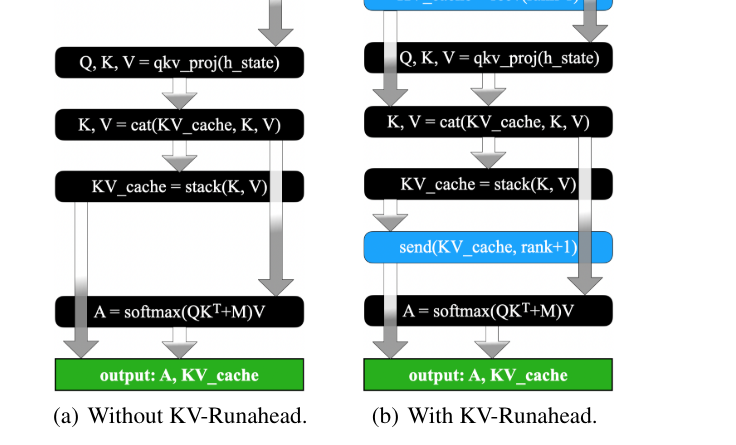
Apple researchers have proposed KV-Runahead, an innovative parallelization technique specifically designed for LLM inference to minimize the time-to-first-token. KV-Runahead leverages the existing KV cache mechanism and optimizes the process by distributing the KV-cache population across multiple processes. This distribution ensures context-level load balancing, leading to improved inference efficiency.
One key advantage of KV-Runahead is its utilization of causal attention computation inherent in the KV-cache. This approach effectively reduces computation and communication costs, resulting in lower TTFT compared to existing methods. Furthermore, the implementation of KV-Runahead requires minimal engineering effort, as it repurposes the KV-cache interface with minimal modifications.
To understand the benefits of KV-Runahead, let’s compare it with the Tensor/Sequence Parallel Inference (TSP) technique. While TSP evenly distributes computation across processes, KV-Runahead takes advantage of multiple processes to populate the KV-caches for the final process. This necessitates effective context partitioning for load balancing. Each process then executes layers, waiting for KV-cache from the preceding process via local communication instead of global synchronization.
Experimental Results and Performance Evaluation
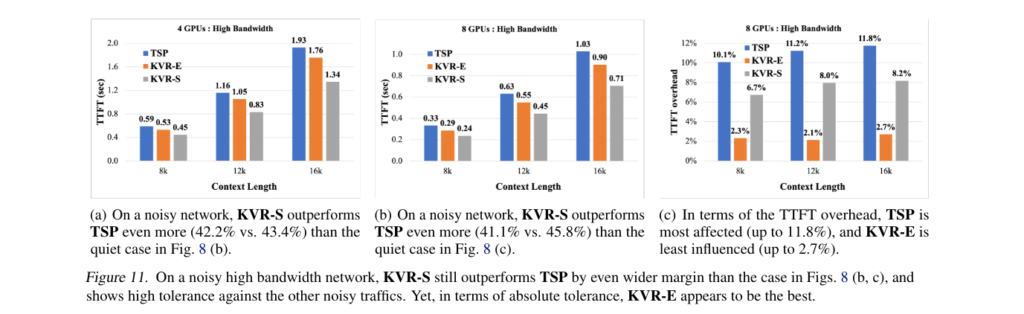
To evaluate the effectiveness of KV-Runahead, Apple researchers conducted experiments on a single node equipped with 8× NVidia A100 GPUs under both high (300GB/s) and low (10GB/s) bandwidth conditions. They compared KV-Runahead, utilizing FP16 for inference, against Tensor/Sequence Parallelization (TSP) and observed consistently superior performance in various scenarios.
Different variants of KV-Runahead, including KVR-E with even context partitioning, KVR-S with searched partitioning, and KVR-P with predicted partitioning, were evaluated for efficiency. The results showcased significant speedups, particularly with longer contexts and a larger number of GPUs. Surprisingly, even on low bandwidth networks, KV-Runahead outperformed TSP.
Moreover, it exhibited robustness against non-uniform network bandwidth, highlighting the benefits of its communication mechanism. These results demonstrate the remarkable potential of KV-Runahead in significantly reducing TTFT and improving LLM inference efficiency.
Conclusion
In this article, we explored Apple’s proposal for KV-Runahead, an efficient parallel LLM inference technique aimed at minimizing the time-to-first-token. We discussed the challenges associated with LLM inference and how KV-Runahead addresses these challenges through innovative parallelization and load-balancing techniques.
The experimental results showcased the superiority of KV-Runahead over existing parallelization methods, highlighting its potential to enhance the efficiency of large language models. With its minimal engineering effort and robustness against non-uniform network bandwidth, KV-Runahead holds promise for further advancements in LLM inference.
The continuous research and development in this field, as demonstrated by Apple’s KV-Runahead, pave the way for more efficient and powerful LLMs, enabling advancements in various natural language processing applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰