Meta AI Introduces Chameleon: A New Frontier in Multimodal Machine Learning
Multimodal machine learning, which involves understanding and generating information from multiple modalities such as text and images, has gained significant attention in recent years. Researchers are constantly striving to develop models that can effectively fuse information across modalities and generate comprehensive multimodal documents. Meta AI, a leading organization in artificial intelligence research, has recently introduced a groundbreaking family of early-fusion token-based foundation models called Chameleon. Chameleon sets a new bar for multimodal machine learning by enabling seamless integration of different types of content within a single document.
The Limitations of Traditional Multimodal Models
Traditional multimodal models tend to segregate different modalities by employing specific encoders or decoders for each. This approach hampers their ability to effectively fuse information across modalities and generate coherent multimodal documents. For instance, when generating a document with interleaved textual and image sequences, traditional models struggle to reason and generate content seamlessly. This limitation arises due to the lack of a unified architecture that treats both modalities equally.
Chameleon: A Unified Approach to Multimodal Machine Learning
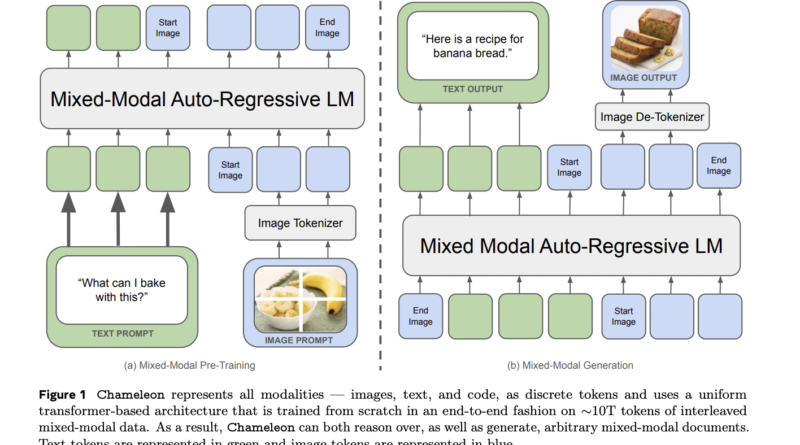
To address the limitations of traditional models, Meta AI researchers have developed Chameleon, a mixed-modal foundation model that revolutionizes multimodal machine learning. Unlike traditional models, Chameleon adopts a unified architecture that treats both textual and image modalities equally. It achieves this by tokenizing images in a manner similar to text, a technique known as early fusion.
Architectural Enhancements and Training Techniques
Early fusion in Chameleon allows for seamless reasoning across modalities, but it also poses optimization challenges. To overcome these challenges, Meta AI researchers propose several architectural enhancements and training techniques. The researchers adapt the transformer architecture, a widely used architecture for natural language processing tasks, and employ finetuning strategies to improve the model’s stability and scalability.
Image Tokenization
One significant aspect of Chameleon is the development of a novel image tokenizer. This tokenizer encodes images into tokens, similar to how text is tokenized. The researchers have focused on licensed images and have doubled the number of face-containing images during pre-training. While the image tokenizer performs well in general, it struggles with text-heavy image reconstruction.
BPE Tokenizer
In addition to the image tokenizer, the researchers trained a BPE (Byte Pair Encoding) tokenizer with a large vocabulary, including image tokens. This tokenizer was trained using the sentencepiece library over a subset of training data. The BPE tokenizer allows Chameleon to effectively handle the tokenization of both textual and image content, facilitating seamless fusion and generation of multimodal documents.
Addressing Stability Issues
During training, Chameleon addresses stability issues by incorporating techniques such as QK-Norm, dropout, and z-loss regularization. These techniques ensure that the model learns robust representations and avoids overfitting or underfitting. The researchers also employ successful training on Meta’s RSC (Recurrent Synthetic Corpus) to further enhance model performance.
Evaluation and Performance
This model has been extensively evaluated on various tasks to assess its performance compared to state-of-the-art models. The model’s text-only capabilities have been tested against existing models, achieving competitive performance across a range of tasks such as commonsense reasoning and mathematical problem solving. It outperforms models like LLaMa-2 on many tasks, thanks to its better pre-training and inclusion of code data.
In image-to-text tasks such as image captioning and visual question answering (VQA), Chameleon excels by matching or surpassing larger models like Flamingo-80B and IDEFICS-80B, even with fewer shots. Although Llava-1.5 slightly outperforms Chameleon in VQA-v2, the model’s performance is still commendable. Moreover, Chameleon’s versatility and efficiency make it competitive across different tasks, requiring fewer training examples and smaller model sizes.
The Impact of Chameleon
Chameleon’s early-fusion approach and its ability to seamlessly integrate textual and image modalities set a new bar for multimodal machine learning. The model’s unified architecture allows for joint reasoning over modalities, surpassing late-fusion models like Flamingo and IDEFICS in tasks such as image captioning and VQA. Chameleon’s groundbreaking techniques for stable training address previous scalability challenges, unlocking new possibilities for multimodal interactions.
In conclusion, Meta AI’s Chameleon model represents a significant advancement in multimodal machine learning. By introducing early fusion and adopting a unified architecture, Chameleon enables seamless integration of textual and image modalities, facilitating comprehensive multimodal document modeling. The model’s architectural enhancements and training techniques ensure stability and scalability, while its outstanding performance across various tasks demonstrates its superiority over existing models. Chameleon paves the way for more advanced and efficient multimodal machine learning systems, with potential applications in fields such as natural language understanding, computer vision, and human-computer interaction.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰