Intel’s Innovative Low-bit Quantized Open LLM Leaderboard: Evaluating Efficient AI Models
In the world of artificial intelligence (AI) and natural language processing (NLP), language models have revolutionized the way we interact with technology. These models, such as OpenAI’s GPT-3 and Google’s BERT, have the capability to understand and generate human-like text, enabling a plethora of applications ranging from chatbots to language translation systems. However, these models often come with a heavy computational cost, making them impractical for resource-constrained environments.
To address this challenge, Intel has recently released a Low-bit Quantized Open LLM Leaderboard, providing a platform for evaluating the performance of various quantized language models. This development is a significant breakthrough in the field of AI, as it allows researchers and developers to compare the efficiency and effectiveness of different quantization techniques, ultimately making AI more accessible to a wider range of applications.
The Need for Quantization in Language Models
Traditional language models, such as GPT-3, are resource-intensive, requiring substantial computational power and memory to operate effectively. This poses a significant challenge for deploying these models in scenarios where resources are limited, such as edge devices or low-power hardware. Quantization, a process that compresses models to require fewer computational resources without a significant loss in accuracy, addresses this challenge by making these models more lightweight and efficient.
Quantization techniques reduce the precision of numerical values in the model, typically by reducing the number of bits used to represent each value. For example, instead of using 32 bits to represent a floating-point number, a quantized model may use only 8 bits. This reduction in precision results in a smaller model size and lower computational requirements, making it feasible to deploy these models in resource-constrained environments.
Introducing the Low-bit Quantized Open LLM Leaderboard
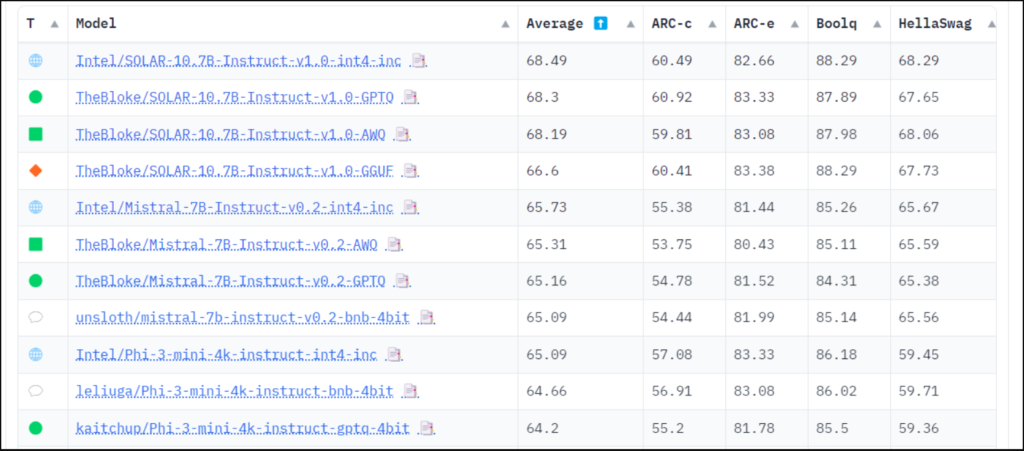
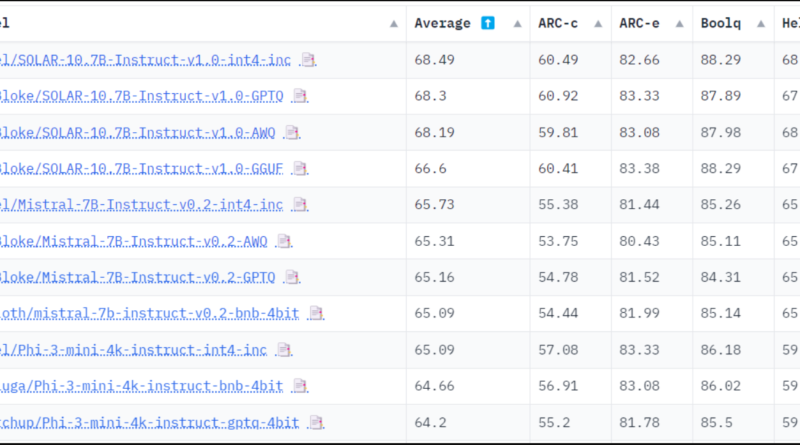
Intel’s Low-bit Quantized Open LLM Leaderboard, hosted on the Hugging Face platform, serves as a benchmark for evaluating the performance of quantized language models. This leaderboard provides a consistent and rigorous evaluation framework, allowing researchers and developers to compare the performance of various quantized models effectively.
The evaluation framework employed by the leaderboard utilizes the Eleuther AI-Language Model Evaluation Harness, a comprehensive testing system that puts models through a battery of tasks designed to assess different aspects of their performance. These tasks cover a wide range of domains, including general knowledge, reasoning, mathematics, science, and more.
Ten Key Benchmarks for Evaluating Language Models
The Low-bit Quantized Open LLM Leaderboard evaluates language models based on ten key benchmarks. These benchmarks aim to assess the models’ performance in zero-shot and few-shot scenarios, which means they evaluate how well the models perform on tasks without extensive fine-tuning or with minimal example-based learning.
1. General Knowledge and Reasoning
These benchmarks test the models’ ability to understand and reason about general knowledge topics, such as answering questions about historical events, scientific concepts, or famous personalities.
2. Mathematical Problem Solving
Models are evaluated on their proficiency in solving mathematical problems, ranging from basic arithmetic to complex algebraic equations.
3. Scientific Comprehension
These benchmarks assess the models’ understanding of scientific concepts and their ability to answer questions related to various scientific fields, including biology, chemistry, and physics.
4. Language Translation
Models are evaluated on their capability to translate text from one language to another accurately. This benchmark tests the models’ language generation and comprehension abilities.
5. Text Completion and Generation
This benchmark measures the models’ ability to generate coherent and contextually appropriate text based on given prompts. The evaluation focuses on the quality and relevance of the generated text.
6. Logical Reasoning
Models are tested on their ability to solve logical reasoning problems, including deductive and inductive reasoning, syllogisms, and puzzles.
7. Sentiment Analysis
This benchmark evaluates the models’ proficiency in understanding and classifying the sentiment expressed in a given text, such as identifying whether a text conveys a positive or negative sentiment.
8. Text Summarization
Models are assessed on their ability to generate concise summaries of longer texts, capturing the most important information while maintaining coherence and readability.
9. Question-Answering
This benchmark focuses on the models’ capacity to answer questions accurately and comprehensively based on given context or passages.
10. Dialogue Generation
Models are evaluated on their capability to engage in human-like conversations and generate meaningful responses in a dialogue setting.
The Impact of the Low-bit Quantized Open LLM Leaderboard
The release of the Low-bit Quantized Open LLM Leaderboard by Intel marks a significant milestone in the field of AI and NLP. By providing a platform for evaluating the performance of quantized language models, this leaderboard enables researchers and developers to make informed decisions when selecting models for specific applications.
The results from the leaderboard showcase the diverse range of performance across different models and tasks. It highlights the trade-offs inherent in current quantization techniques, where models optimized for certain types of reasoning or specific knowledge areas may struggle with other cognitive tasks. This insight is invaluable for guiding future model design and training approach improvements, ultimately leading to more efficient and effective language models.
Conclusion
Intel’s Low-bit Quantized Open LLM Leaderboard represents a significant advancement in the evaluation of language model performance. By creating a standardized framework for comparing quantized models, this leaderboard empowers researchers and developers to push the boundaries of AI accessibility and efficiency. As the field of AI continues to evolve, tools like the Low-bit Quantized Open LLM Leaderboard will play a vital role in driving innovation and making AI more accessible to a wider range of applications.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰