Revolutionizing Text Retrieval: Introducing Snowflake’s Optimized Arctic-Embed Models
In the expanding field of natural language processing, text embedding models have emerged as a fundamental technology. These models transform textual information into numerical representations, enabling machines to understand, interpret, and manipulate human language. With applications ranging from search engines to chatbots, text embedding models have significantly enhanced efficiency and effectiveness in various domains.
However, one of the challenges in this field is to improve the retrieval accuracy of embedding models without significantly increasing computational costs. Existing models often struggle to strike a balance between performance and resource demands, requiring substantial computational power for marginal gains in accuracy.
To address this challenge, researchers from Snowflake Inc. have introduced Arctic-Embed models, setting a new standard for text embedding efficiency and accuracy. These models leverage a data-centric training strategy that optimizes retrieval performance without excessively increasing model size or complexity. By employing techniques such as in-batch negatives and a sophisticated data filtering system, Arctic-Embed models achieve superior retrieval accuracy compared to existing solutions, demonstrating their practicality in real-world applications.
The Landscape of Text Embedding Models
Before delving into the specifics of Arctic-Embed, let’s explore the existing landscape of text embedding models.
E5 Model: Known for its efficiency in web-crawled datasets, the E5 model has been widely adopted due to its ability to handle large-scale text corpora efficiently.
GTE Model: The GTE model enhances text embedding applicability through multi-stage contrastive learning, enabling better representation of textual information.
Jina Framework: Specializing in long document processing, the Jina framework provides a comprehensive solution for handling lengthy texts, making it suitable for tasks such as document retrieval.
BERT and its Variants: BERT, along with its variants like MiniLM and Nomic BERT, has revolutionized the field of text embedding. These models optimize for specific tasks, such as efficiency and long-context data handling.
InfoNCE Loss: The InfoNCE loss has played a pivotal role in improving model training for better similarity tasks, leading to enhanced representation learning.
FAISS Library: The FAISS library facilitates efficient document retrieval, streamlining embedding-based search processes.
While these models have contributed significantly to the advancement of text embedding, there is still room for improvement in terms of retrieval accuracy and computational efficiency.
Introducing Arctic-Embed: A Breakthrough in Text Retrieval
Snowflake Inc.’s Arctic-Embed models aim to address the limitations of existing text embedding models. By adopting a data-centric training strategy, these models optimize retrieval performance while keeping model size and complexity in check.
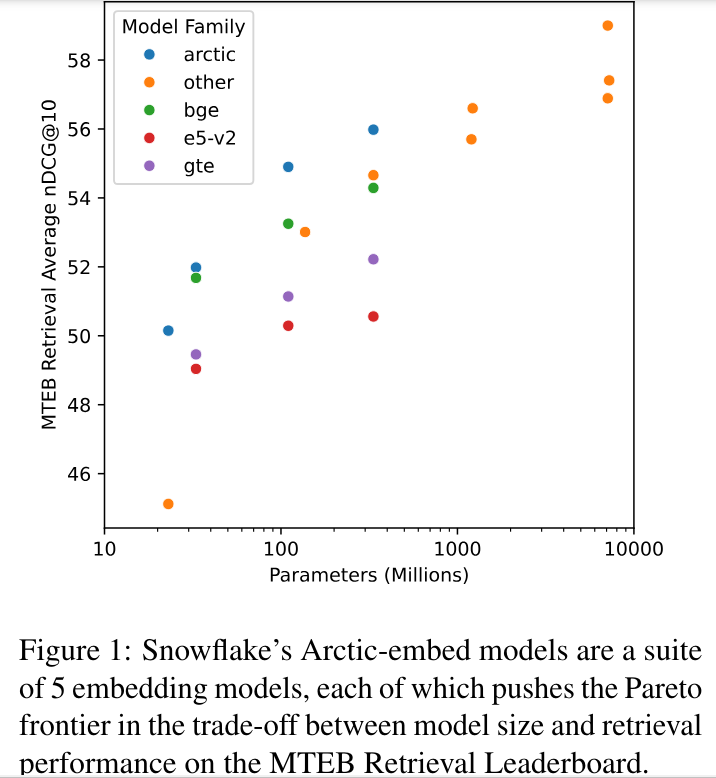
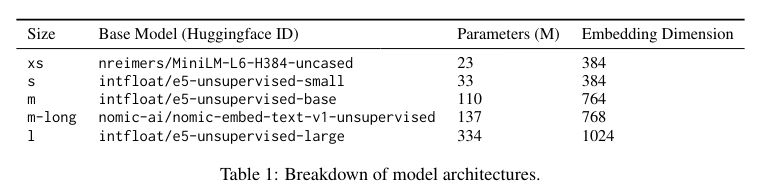
The methodology behind Arctic-Embed models involves training with datasets such as MSMARCO and BEIR, which are renowned for their comprehensive coverage and benchmarking relevance in the field. The models within the Arctic-Embed suite range from small-scale variants with 22 million parameters to the largest model with 334 million parameters. Each model is tuned to optimize performance metrics like nDCG@10 on the MTEB Retrieval leaderboard.
Arctic-Embed models leverage a combination of pre-trained language model backbones and fine-tuning strategies, including hard negative mining and optimized batch processing, to enhance retrieval accuracy. By incorporating techniques like in-batch negatives, which involve sampling negative examples within the same batch during training, and a sophisticated data filtering system, these models achieve superior retrieval accuracy compared to existing solutions.
The outstanding results achieved by Arctic-Embed models on the MTEB Retrieval leaderboard speak to their efficacy. Specifically, the nDCG@10 scores for the various models within the suite range impressively, with the largest model reaching a peak score of 88.13. These benchmark performances signify a substantial advancement over prior models, underlining the effectiveness of the novel methodologies employed in Arctic-Embed.
The Practical Benefits of Arctic-Embed
The introduction of Snowflake Inc.’s Arctic-Embed models represents a significant leap forward in text embedding technology. These models offer superior retrieval accuracy while efficiently utilizing computational resources. By focusing on optimized data filtering and training methodologies, Arctic-Embed models strike a balance between performance and resource demands, making them highly practical for real-world applications.
The benefits of Arctic-Embed can be summarized as follows:
- Enhanced Retrieval Accuracy: Arctic-Embed models achieve superior retrieval accuracy compared to existing solutions, enabling more precise and relevant search results.
- Efficient Resource Utilization: By optimizing the training strategy and incorporating techniques like in-batch negatives, Arctic-Embed models achieve high retrieval accuracy without excessively increasing computational costs.
- Real-World Applicability: The practicality of Arctic-Embed models is evident in their benchmark performances on the MTEB Retrieval leaderboard. These models are designed to handle complex retrieval tasks with enhanced accuracy, making them suitable for a wide range of applications.
Setting a New Standard in Text Embedding
The introduction of Arctic-Embed models by Snowflake Inc. sets a new standard in the field of text embedding. With their focus on optimization, efficiency, and retrieval accuracy, these models guide future innovations in the domain. By making high-performance text processing more accessible and effective, Arctic-Embed models have the potential to transform various industries, ranging from information retrieval to natural language understanding.
In conclusion, Snowflake Inc.’s Arctic-Embed models represent a breakthrough in enhancing text retrieval with optimized embedding models. These models achieve superior retrieval accuracy by leveraging a data-centric training strategy and incorporating techniques such as in-batch negatives and data filtering. With their outstanding benchmark performances and practical benefits, Arctic-Embed models set a new standard in text embedding technology, paving the way for future advancements in the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰