Mistral AI Introduces Mixtral 8x7B: A Sparse Mixture of Experts (SMoE) Language Model Transforming Machine Learning
Artificial Intelligence (AI) and Machine Learning (ML) have been making significant strides in recent years, revolutionizing various industries. One of the key advancements in this field is the development of language models that can understand and generate human-like text. Mistral AI, a leading research lab, has recently introduced a groundbreaking language model called Mixtral 8x7B. This model is based on the innovative Sparse Mixture of Experts (SMoE) framework and is transforming the field of machine learning. In this article, we will explore the features and capabilities of Mixtral 8x7B and its implications for the future of AI.
Understanding Mixtral 8x7B: A Sparse Mixture of Experts Language Model
Mixtral 8x7B is a language model developed by Mistral AI that utilizes the Sparse Mixture of Experts (SMoE) framework. This model represents a significant advancement in the field of machine learning and natural language processing. It is built upon the principles of a sparse network of a mixture of experts, enabling it to process and generate text with exceptional accuracy and efficiency [1].
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
The innovative architecture of Mixtral 8x7B consists of a feedforward block with eight different parameter groups. Each layer and token in the model is associated with two parameter groups, known as experts. These experts are dynamically selected by the router network to process tokens and combine their results additively. This approach allows Mixtral to efficiently utilize a portion of the total parameters for every token, increasing the model’s parameter space while maintaining cost and latency control [1].
Advantages of Mixtral 8x7B
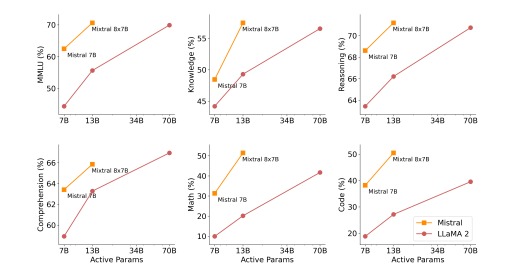
Mixtral 8x7B offers several advantages that set it apart from other language models. One of its key strengths is its effective use of parameters, enabling quicker inference times at small batch sizes and higher throughput at large batch sizes. This efficiency is a result of the SMoE framework, which optimizes the allocation of resources within the model. As a result, Mixtral outperforms other models, such as Llama 2 70B and GPT-3.5, in various benchmarks [1].
Moreover, Mixtral 8x7B has demonstrated superior performance in multilingual understanding, code production, mathematics, and other tasks. It can effectively process and generate text, regardless of the length and position of the data within the sequence. This versatility makes Mixtral a powerful tool for a wide range of applications [1].
Benchmarks and Evaluation
To ensure a fair and accurate assessment of Mixtral 8x7B, the Mistral AI team performed extensive benchmarks and evaluations. These evaluations covered various categories, such as math, code, reading comprehension, common sense thinking, world knowledge, and popular aggregated findings. The team compared Mixtral with Llama models and analyzed their performance on tasks spanning different domains [1].
In commonsense reasoning tasks like ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA, SIQA, OpenbookQA, and CommonsenseQA, Mixtral 8x7B performed exceptionally well in a 0-shot environment. World knowledge tasks, such as TriviaQA and NaturalQuestions, were assessed in a 5-shot format. Reading comprehension tasks, including BoolQ and QuAC, were evaluated in a 0-shot environment. Mixtral also demonstrated its capabilities in math tasks such as GSM8K and MATH, as well as code-related tasks like Humaneval and MBPP. The performance of popular consolidated findings for AGI Eval, BBH, and MMLU showcased Mixtral’s wide range of capabilities [1].
Mixtral 8x7B – Instruct: Optimized for Instructions
In addition to Mixtral 8x7B, Mistral AI has introduced Mixtral 8x7B – Instruct, a conversation model optimized for instructions. This model has undergone direct preference optimization and supervised fine-tuning to enhance its performance. In human review benchmarks, Mixtral-Instruct has outperformed other chat models, such as GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B. Benchmarks like BBQ and BOLD have also shown that Mixtral-Instruct exhibits fewer biases and a more balanced sentiment profile [1].
Licensing and Accessibility
To promote widespread accessibility and encourage a variety of applications, Mistral AI has licensed both Mixtral 8x7B and Mixtral 8x7B – Instruct under the Apache 2.0 license. This allows for both commercial and academic use of these models. Mistral AI has also made modifications to the vLLM project by adding Megablocks CUDA kernels for effective inference [1].
Conclusion: Transforming Machine Learning with Mixtral 8x7B
Mistral AI’s introduction of Mixtral 8x7B marks a significant advancement in the field of machine learning and natural language processing. This language model, based on the Sparse Mixture of Experts (SMoE) framework, offers exceptional performance and efficiency. Mixtral 8x7B outperforms other models in various benchmarks and tasks, demonstrating its versatility and capabilities. With its effective use of parameters and the addition of Mixtral 8x7B – Instruct for instruction-based conversations, Mistral AI is leading the way in transforming machine learning and AI applications [1].
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰