DiffusionGPT: LLM-Driven Text-to-Image Generation System
In recent years, there has been significant progress in the field of image generation, thanks to advancements in diffusion models. These models have paved the way for the development of top-tier models available on open-source platforms. However, challenges still persist in text-to-image systems, especially when it comes to managing diverse inputs and being limited to single-model outcomes. Researchers from ByteDance and Sun Yat-Sen University have recognized these challenges and introduced a groundbreaking solution called DiffusionGPT: LLM-Driven Text-to-Image Generation System.
The Need for DiffusionGPT
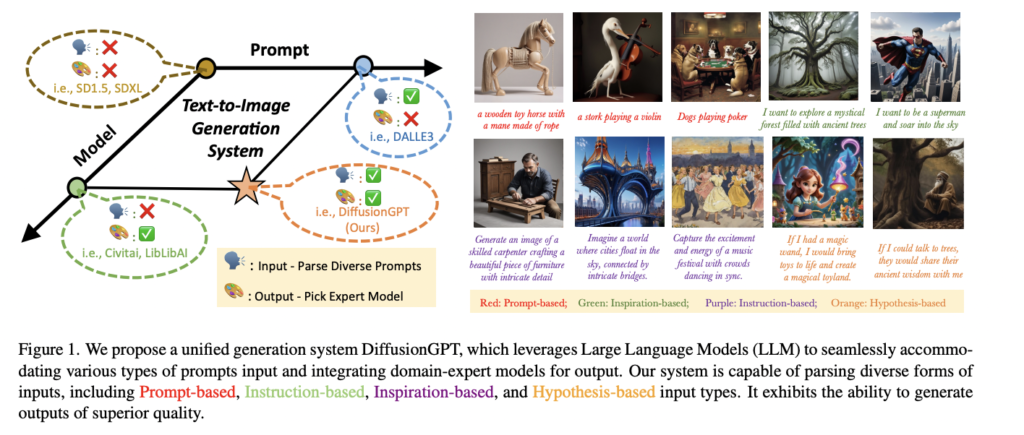
While diffusion models like DALLE-2 and Imagen have revolutionized image editing and stylization, their non-open source nature has hindered widespread adoption. Open-source alternatives such as Stable Diffusion (SD) and its latest iteration, SDXL, have gained popularity. However, these models still face limitations and prompt constraints that require additional approaches like SD1.5+Lora and prompt engineering. Despite these efforts, optimal performance has not yet been achieved. A unified framework that overcomes prompt constraints and leverages domain-expert models is essential for unlocking the full potential of text-to-image generation.
Introducing DiffusionGPT
Researchers from ByteDance and Sun Yat-Sen University propose DiffusionGPT, a novel approach that utilizes a Large Language Model (LLM) to create a comprehensive text-to-image generation system. This system integrates various generative models based on prior knowledge and human feedback, providing a unified framework for surpassing prompt limitations. The LLM plays a crucial role in parsing the prompt and guiding the system to select the most suitable generative model for generating the desired output.
To ensure a user-informed solution, Advantage Databases enhance the system with valuable human feedback, aligning the model selection process with human preferences. This comprehensive framework empowers users to generate high-quality images by seamlessly combining different generative models.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Understanding the Workflow
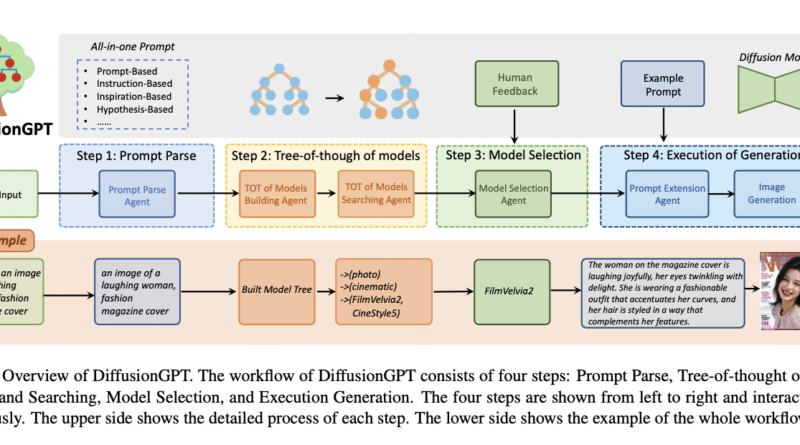
DiffusionGPT follows a four-step workflow:
- Prompt Parse: In this stage, salient information is extracted from diverse prompts, providing a foundation for subsequent processes.
- Tree-of-Thought of Models Build and Search: A hierarchical model tree is constructed for efficient searching. This allows the system to explore and select the most appropriate generative model based on the parsed prompt.
- Model Selection with Human Feedback: Leveraging Advantage Databases, the system incorporates human feedback to refine the model selection process. This ensures that the chosen generative model aligns with user preferences.
- Execution of Generation: The chosen generative model undergoes the execution process, resulting in the generation of high-quality images. A Prompt Extension Agent further enhances the prompt quality, leading to improved outputs.
Experimental Setup and Results
In their experimental setup, the researchers employed ChatGPT as the LLM controller, integrating it into the LangChain framework to provide precise guidance. DiffusionGPT was then tested against baseline models such as SD1.5 and SDXL across various prompt types.
The results were impressive. DiffusionGPT showcased superior performance, addressing semantic limitations and enhancing image aesthetics. It outperformed SD1.5 in both image-reward and aesthetic scores by 0.35% and 0.44%, respectively. These results highlight the effectiveness of DiffusionGPT in generating high-quality images that meet user expectations.
Conclusion
The introduction of DiffusionGPT by researchers from ByteDance and Sun Yat-Sen University marks a significant advancement in the field of text-to-image generation. By leveraging LLMs and a comprehensive framework, DiffusionGPT adeptly interprets input prompts and selects the most suitable generative model. This adaptable and training-free solution demonstrates exceptional performance across diverse prompts and domains. Furthermore, the incorporation of human feedback through Advantage Databases makes DiffusionGPT an efficient and easily integrable plug-and-play solution that fosters community development in the field.
With DiffusionGPT, the future of text-to-image generation looks promising. Researchers and developers can now unlock the full potential of generative models and create captivating images that surpass expectations. As advancements continue, it is exciting to envision the endless possibilities that DiffusionGPT and similar innovations will bring to the world of image generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰