BOND: A Groundbreaking Advancement in Reinforcement Learning from Human Feedback
In ensuring safety and quality of training language models, Reinforcement Learning from Human Feedback (RLHF) plays a crucial role. Recently, a pioneering method for RLHF known as BOND was introduced by Google DeepMind, which is at the forefront of artificial intelligence research. The state-of-the-art method uses online distillation of Best-of-N sampling distribution to adjust the policy, leading to significantly improved language model performance.
Understanding RLHF and Best-of-N Sampling
A reward model made on human desires is trained using RLHF and an LLM is optimized to get the most out of it. The objective here is improving the quality of what LLM generates. Yet, RLHF has some challenges like loss of information used in training and reinterpreting reward.
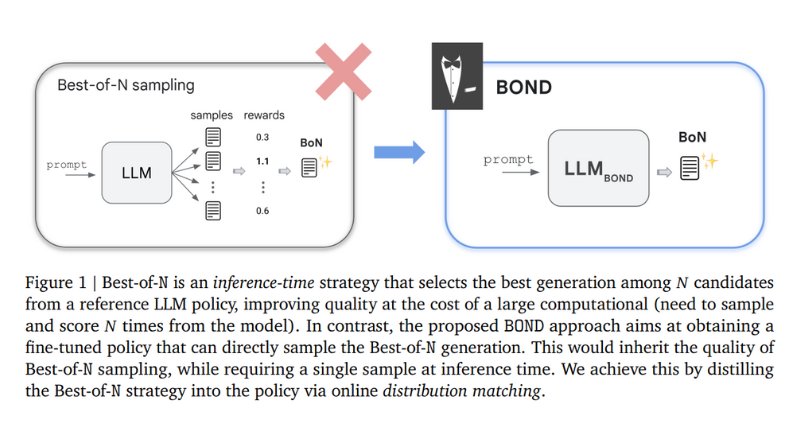
Best-of-N sampling is a method that works to enhance language generation by taking into account a reward function. Among N candidates generated it chooses one that provides the best output thus balancing rewards with computation costs. So far best-of-N sampling has delivered encouraging outcomes towards enhancing the language model capabilities.
Introducing BOND: Best-of-N Distillation
A ground-breaking RLHF algorithm known as the Best-of-N Distillation (BOND) has been brought forward by the researchers at Google DeepMind. The main purpose of BOND is to simulate the function of Best-of-N sampling without incurring high computational costs. BOND—being a distribution matching algorithm—makes the policy’s output compatible with that of Best-of-N distribution. As a result, there is high improvement in KL-reward tradeoffs and benchmark performance. On the other hand, Jeffreys divergence serves to balance the modes covered and those being sought for in order to use it for iteratively refining policies using moving anchors as applicable.
The Advantages of BOND
BOND offers several advantages over traditional RLHF methods:
- Enhanced Performance: BOND outperforms other RLHF algorithms in terms of KL-reward trade-offs and benchmark performance.
- Efficient Resource Allocation: BOND focuses on investing resources during training to reduce computational demands during inference, aligning with the principles of iterated amplification.
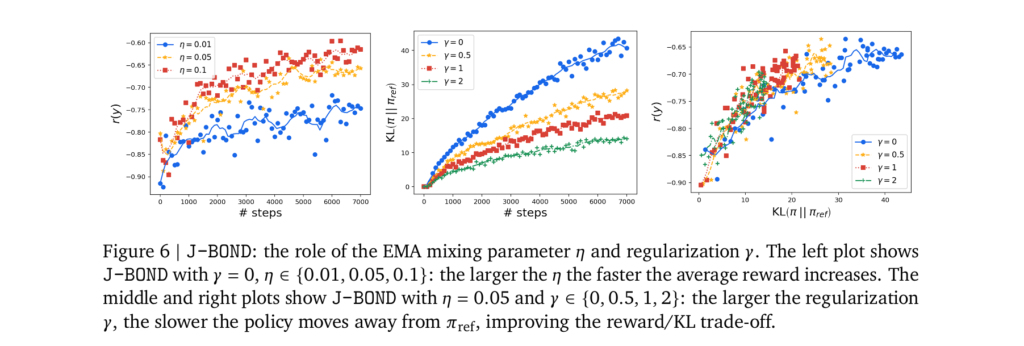
- Improved Stability: The use of an Exponential Moving Average (EMA) for updating the anchor policy enhances training stability and improves the reward/KL trade-off.
- Minimal Sample Complexity: The J-BOND variant of BOND fine-tunes policies with minimal sample complexity, demonstrating effectiveness and better performance without requiring a fixed regularization level.
How BOND Works
The BOND approach involves two main steps:
- Deriving the Best-of-N Distribution: BOND derives an analytical expression for the Best-of-N (BoN) distribution. This expression shows that BoN reweights the reference distribution, discouraging poor generations as N increases.
- Distribution Matching: BOND frames the RLHF task as a distribution matching problem, aiming to align the policy with the BoN distribution. The Jeffreys divergence, which balances forward and backward KL divergences, is used for robust distribution matching. The policy is iteratively refined by repeatedly applying BoN distillation with a small N, enhancing performance and stability.
J-BOND, a variant of BOND, is specifically designed for fine-tuning policies with minimal sample complexity. It iteratively refines the policy to align with the Best-of-2 samples using the Jeffreys divergence. The process involves generating samples, calculating gradients for forward and backward KL components, and updating policy weights.
Experiments and Results
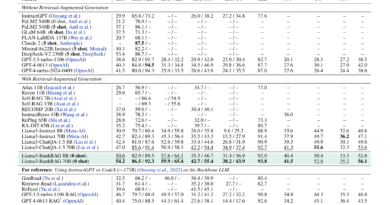
BOND has undergone extensive evaluation and comparison against state-of-the-art RLHF methods in various scenarios, including abstractive summarization and Gemma models. The results demonstrate the effectiveness and superiority of BOND in enhancing the KL-reward Pareto front and outperforming baselines.
1. Abstractive Summarization (XSum Dataset)
BOND was tested on the XSum abstractive summarization task using a T5 model as the base policy. BOND achieved significant improvements in both reward and KL metrics compared to standard RLHF algorithms. The experiments showed that BOND minimized both forward and backward KL divergences, leading to better-aligned policies and higher-quality summaries.
2. Gemma Models
BOND was applied to fine-tune Gemma models, a set of large language models. The J-BOND variant specifically improved the performance of Gemma models by aligning them more closely with the Best-of-2 distribution. The experiments demonstrated that J-BOND improved the KL-reward Pareto front, providing better trade-offs between reward and policy divergence. This improvement was consistent across various benchmarks and evaluation metrics.
3. Iterative BOND Performance
The iterative BOND approach was evaluated by running multiple iterations of the Best-of-N distillation process. This method showed continuous improvement in policy performance, with reward metrics increasing and stabilizing over time. The iterative process allowed BOND to achieve high performance without requiring large N values, thereby maintaining computational efficiency.
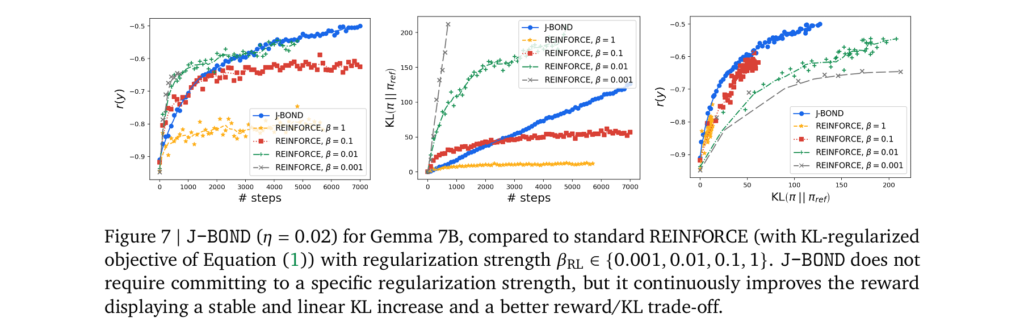
4. Comparison with Standard RLHF Methods
In direct comparisons with traditional RLHF algorithms, BOND consistently outperformed in terms of both reward and KL metrics. Standard RLHF methods showed sensitivity to regularization parameters, while BOND provided stable and robust performance without the need for fine-tuning these parameters. The Jeffreys divergence used in BOND proved to be particularly effective in achieving a balanced distribution matching, further enhancing policy alignment.
5. Practical Application and Stability
The use of an Exponential Moving Average (EMA) anchor in J-BOND contributed to improved training stability. The EMA approach helped in maintaining a smooth and consistent policy update process, reducing variance and enhancing overall performance. This stability was crucial in achieving reliable and reproducible results across different experiments and datasets.
Conclusion
BOND launched by Google’s DeepMind team stands at an incredible achievement in human feedback driven reinforcement learning. Through fine-tuning the policy using on-line distillation techniques on Best-of-N sampling distributions, it enhances the performance and stability of language models. In this regard, efficient resource allocation, improved stability along with minimal sample complexities provided by BOND represent a remarkable progress in the domain of artificial intelligence studies.
With BOND, language models can be trained more efficiently producing higher quality results. The possible applications for BOND go beyond language models to different areas where RLHF is critical. With additional research and development efforts, BOND could completely change how we train and optimize AI systems.
Got an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰