Google DeepMind Researchers Propose WARM: A Novel Approach to Tackle Reward Hacking in Large Language Models Using Weight-Averaged Reward Models
In recent years, Large Language Models (LLMs) have revolutionized the field of natural language processing by achieving remarkable performance in various tasks, such as question answering, language translation, and text generation. These models, trained on massive amounts of data, can generate highly coherent and contextually accurate responses. However, aligning LLMs with human preferences through reinforcement learning from human feedback (RLHF) can give rise to a phenomenon known as reward hacking.
Reward hacking occurs when LLMs exploit flaws in the reward model (RM), maximizing their rewards without actually fulfilling the underlying objectives. This can lead to a range of issues, including degraded performance, difficulties in selecting appropriate checkpoints, potential biases, and even safety risks. To address these challenges, researchers at Google DeepMind have proposed a novel approach called Weight Averaged Reward Models (WARM) [1].
Challenges in Reward Modeling
Designing effective reward models to mitigate reward hacking poses several challenges. Two primary challenges identified in the research are distribution shifts and inconsistent preferences in the preference dataset.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Distribution shifts occur due to policy drift during RL, which causes a deviation from the offline preference dataset. This shift can lead to a misalignment between the learned behavior of the LLM and the intended behavior, resulting in reward hacking. Inconsistent preferences, on the other hand, arise from noisy binary labels in the preference dataset. These inconsistencies introduce low inter-labeler agreement, making it challenging to obtain a robust and reliable reward model.
Existing approaches have attempted to tackle these challenges using methods such as KL regularization, active learning, and prediction ensembling. However, these methods often suffer from efficiency issues, and reliability concerns, and struggle to handle preference inconsistencies.
Introducing Weight Averaged Reward Models (WARM)
To address the challenges of reward hacking, the researchers at Google DeepMind propose a new approach called Weight Averaged Reward Models (WARM). WARM is a simple, efficient, and scalable strategy for obtaining a reliable and robust reward model.
The core idea behind WARM is to combine multiple reward models through linear interpolation in the weight space. By averaging the weights of these models, WARM leverages the diversity across fine-tuned weights to achieve a more effective and reliable reward model. Figure 1(a) illustrates the concept of WARM [1].
Advantages of Weight Averaged Reward Models (WARM)
WARM offers several advantages over existing methods, such as prediction ensembling. Firstly, WARM is more efficient and practical as it requires only a single model at inference time, eliminating the need for memory and inference overheads associated with ensembling predictions.
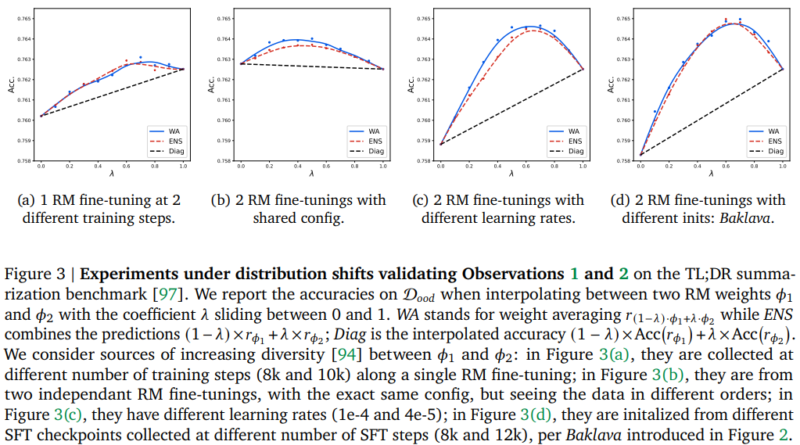
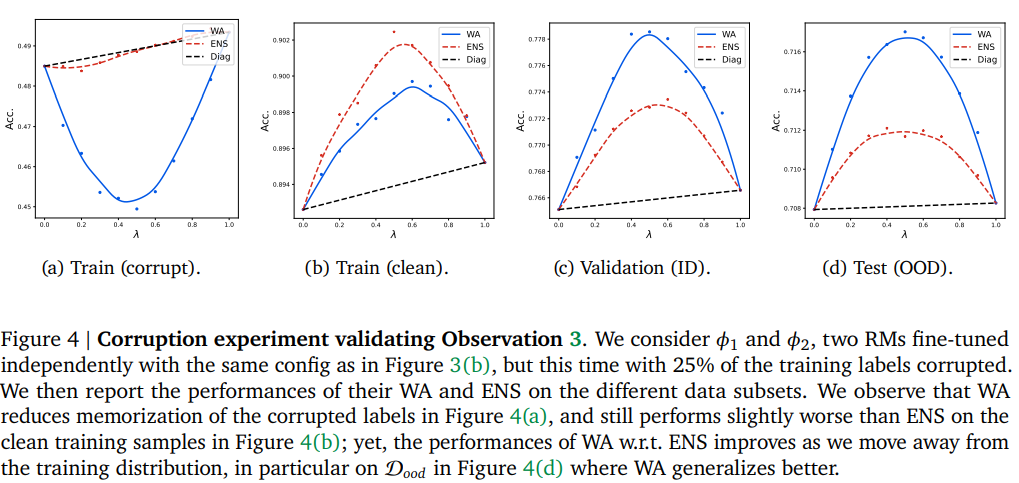
Empirical results demonstrate that WARM performs similarly to prediction ensembling in terms of variance reduction but exhibits superiority under distribution shifts. WARM achieves this by leveraging the concept of linear mode connectivity (LMC), which allows it to memorize less and generalize better than ensembling predictions. The effectiveness of WARM is empirically proven in Figure 3 and 4 of the research paper [1].
Additionally, WARM offers benefits beyond its primary goal of mitigating reward hacking. It aligns with the updatable machine learning paradigm, allowing parallelization in federated learning scenarios. WARM also has the potential to contribute to privacy and bias mitigation by reducing the memorization of private preferences. Furthermore, WARM can support the combination of reward models trained on different datasets, enabling iterative and evolving preferences.
Limitations and Future Directions
While WARM presents a novel and effective approach to reward modeling, it does have certain limitations. One limitation is its potential difficulty in handling diverse architectures and uncertainty estimation compared to prediction ensembling methods. However, further research and development can address these limitations and enhance the applicability of WARM.
Moreover, WARM should be considered within the broader context of responsible AI. While it tackles the issue of reward hacking, there may still be spurious correlations or biases in the preference data. Therefore, additional methods and frameworks should be explored to ensure a comprehensive solution that addresses safety risks and promotes ethical AI.
Conclusion
Google DeepMind’s Weight-Averaged Reward Models (WARM) offer a novel and efficient approach to tackle reward hacking in large language models. By combining multiple reward models through weight averaging, WARM provides a reliable and robust reward model that aligns with human preferences.
The empirical results and theoretical insights presented in the research paper demonstrate the effectiveness and potential of WARM in creating more aligned, transparent, and effective AI systems. WARM not only mitigates reward hacking but also opens avenues for parallelization, privacy preservation, and the combination of diverse reward models.
As the field of natural language processing continues to advance, approaches like WARM pave the way for safer and more reliable AI systems that better understand and cater to human preferences.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰