FUSELLM: Pioneering the Fusion of Diverse Large Language Models for Enhanced Capabilities
Language models have revolutionized natural language processing tasks, enabling advancements in areas such as machine translation, text generation, and sentiment analysis. However, developing these models from scratch is a resource-intensive process, requiring extensive computational power and energy consumption. In response to these challenges, researchers from Sun Yat-sen University and Tencent AI Lab have introduced a groundbreaking approach called FUSELLM, which aims to fuse diverse large language models (LLMs) to enhance their capabilities while reducing resource expenditure.
The Need for Knowledge Fusion in LLMs
Large language models like GPT-3 and LLaMA have proven to be highly effective in various language processing tasks. However, the creation of these models from the ground up involves significant costs and computational resources. As a result, researchers have started exploring alternative approaches to leverage the strengths of existing models and minimize resource requirements.
Knowledge fusion in LLMs is a pioneering concept that aims to combine the capabilities of different models and create a more powerful and efficient language model. By merging the knowledge and strengths of multiple LLMs, this approach offers a cost-effective solution and enables a more versatile tool adaptable to various applications.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Challenges in Merging Diverse LLMs
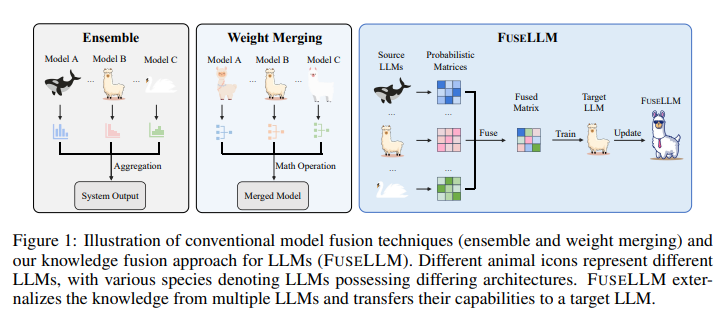
Merging diverse LLMs presents several challenges due to variations in their architecture and parameter spaces. Simply blending their weights is not a feasible solution, necessitating a more nuanced approach to knowledge fusion. Traditional methods such as ensemble strategies and weight merging face practical limitations when applied to LLMs.
Ensemble methods, which aggregate outputs from multiple models, encounter difficulties with LLMs due to their high memory and time requirements. On the other hand, weight merging often fails to yield optimal results when applied to models with significant differences in their parameter spaces. These limitations highlight the need for innovative techniques to effectively combine the capabilities of diverse LLMs.
Introducing FUSELLM: A Novel Approach to Knowledge Fusion
The researchers from Sun Yat-sen University and Tencent AI Lab have introduced a groundbreaking concept called FUSELLM for knowledge fusion in LLMs. This approach leverages the generative distributions of source LLMs, externalizing their knowledge and strengths, and transferring them to a target LLM through lightweight continual training.
The core of the FUSELLM approach lies in aligning and fusing the probabilistic distributions generated by the source LLMs. This process involves developing new strategies for aligning tokenizations and exploring methods for fusing probability distributions. The aim is to minimize the divergence between the probabilistic distributions of the target and source LLMs, ensuring effective knowledge transfer and fusion.
Implementing FUSELLM: Aligning Tokenizations and Fusing Probability Distributions
Implementing the FUSELLM methodology requires a detailed alignment of tokenizations across different LLMs. This step is crucial for the effective fusion of knowledge, as it ensures proper mapping of probabilistic distribution matrices. The fusion process involves evaluating the quality of different LLMs and assigning varying levels of importance to their respective distribution matrices based on their prediction quality.
This nuanced approach allows the fused model to take advantage of the collective knowledge while preserving the unique strengths of each source LLM. By fusing the probabilistic distributions of diverse LLMs, FUSELLM maximizes the strengths and capabilities of the resulting model.
Evaluating the Performance of FUSELLM
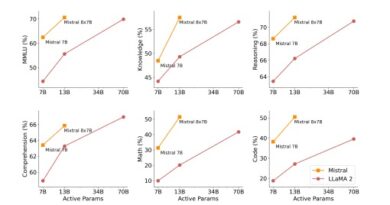
To assess the effectiveness of FUSELLM, the researchers conducted rigorous testing using three popular open-source LLMs with distinct architectures: Llama-2, MPT, and OpenLLaMA. The evaluation encompassed various benchmarks, including reasoning, commonsense, and code generation tasks.
The results of the evaluation were remarkable, with the fused model consistently outperforming each source LLM and the baseline in most tasks. The study demonstrated significant improvements in various capabilities, highlighting the effectiveness of FUSELLM in integrating the collective strengths of individual LLMs.
Key Insights and Future Directions
The research on FUSELLM offers several key insights into the fusion of diverse large language models. By combining the capabilities of different LLMs, this approach introduces a pioneering solution to the challenges of resource-intensive model training. It not only reduces computational requirements but also harnesses the collective strengths of various models, leading to enhanced capabilities in natural language processing tasks.
The findings from this research pave the way for future advancements in language modeling and natural language processing. By exploring innovative approaches to knowledge fusion, researchers can continue to improve the efficiency and effectiveness of large language models. As the field progresses, we can expect further breakthroughs in language understanding and generation, benefiting a wide range of applications.
In conclusion, the FUSELLM approach developed by researchers from Sun Yat-sen University and Tencent AI Lab represents a significant milestone in the fusion of diverse large language models. By leveraging the strengths of different models and minimizing resource expenditure, FUSELLM opens up new possibilities for enhanced capabilities in natural language processing. As the field continues to evolve, we can expect further advancements in the fusion of language models, enabling more sophisticated and versatile language processing applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰