Tackling Memorization in NLP with Huawei’s Theoretical Framework
Transformers have revolutionized the field of natural language processing (NLP) by achieving state-of-the-art performance on various language-based tasks. These powerful models, such as GPT (Generative Pre-trained Transformer), have demonstrated remarkable capabilities, including text generation, translation, and question-answering. However, as models grow in size and complexity, researchers have observed a phenomenon known as “memorization” and its impact on the performance dynamics of transformer-based language models (LMs). In this article, we will delve into a theoretical framework proposed by Huawei researchers that focuses on understanding the memorization process and performance dynamics of these LMs.
The Challenge of Memorization in Transformer-based LMs
As transformer-based LMs become increasingly larger and more powerful, they often exhibit impressive performance improvements in terms of perplexity and accuracy. However, there are instances where larger models do not necessarily guarantee better performance. For example, the 2B model MiniCPM has shown comparable capabilities to larger language models like Llama2-7B, Mistral-7B, Gemma-7B, and Llama-13B. Additionally, the availability of high-quality training data does not always keep pace with the computational resources required for training larger models.
To address these challenges, researchers have explored different methods, including scaling laws, energy-based models, and Hopfield models, to understand and improve the performance dynamics of transformer-based LMs.
Scaling Laws: Performance with Scale
Scaling laws propose that the performance of models increases when there is a scale-up in both the model’s size and the volume of training data. These laws suggest that larger models have the capacity to capture more complex patterns and dependencies present in the data, thereby improving their performance.
Energy-Based Models: Modeling Neural Networks
Energy-based models have gained popularity as fundamental tools in various machine learning applications. These models aim to represent neural networks using parameterized probability density functions, which define a learnable energy function. By modeling the distribution of data in terms of energy, energy-based models provide a flexible framework for understanding the dynamics of transformer-based LMs.
Hopfield Models: Associative Memory
The classical Hopfield networks serve as an example of associative memory. Hopfield models have been extensively studied as a means to capture and recall patterns from memory. These models offer insights into how transformer-based LMs can potentially leverage associative memory mechanisms to improve performance and handle memorization challenges.
Huawei’s Theoretical Framework for Memorization and Performance Dynamics
Researchers from Huawei Technologies Co., Ltd. have proposed a theoretical framework that specifically focuses on the memorization process and performance dynamics of transformer-based LMs. Through a series of experiments using GPT-2 and vanilla Transformer models, they aimed to validate the theoretical results and provide important insights for guiding and improving model training.
Experimental Setup
In their experiments, the researchers trained a 12-layer transformer LM using the GPT-2 small tokenizer and architecture on the OpenWebText dataset. This dataset, similar to the WebText dataset used for original GPT-2 model training, contains a vast amount of text data. Three different models were trained, each utilizing a subset of the OpenWebText data: the first 1% (90M tokens), the first 0.1% (9M tokens), and a dataset consisting of only 2M tokens.
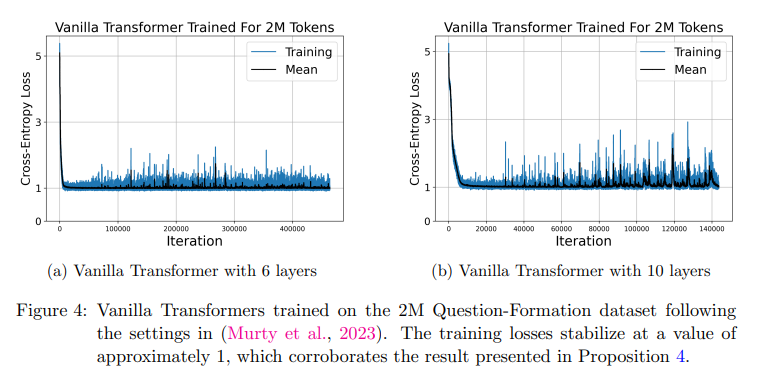
Additionally, the researchers trained vanilla Transformer models on a small amount of high-quality data. This dataset comprised pairs of English sentences in declarative formation, with a context-free vocabulary size of 68 words. The task for these models was to convert declarative sentences into questions.
Observations and Insights
The experiments conducted by the researchers revealed several important observations and insights regarding the memorization process and performance dynamics of transformer-based LMs.
- Overfitting with Limited Data: When training the models using only 0.1% (9M tokens) of the OpenWebText data, overfitting occurred, and the training loss disappeared over iterations. This phenomenon can be attributed to poorly separated training samples, leading the model energy to decrease to a sum of delta functions.
- Performance Scaling: The researchers observed that when the model size was approximately O(D^2) (where D represents the dimensionality of the model) and trained on 90M tokens, the model achieved similar training and validation loss compared to the setting with 9B tokens. This finding aligns with the scaling laws discussed earlier, suggesting that increasing the model size can indeed lead to improved performance.
- Stabilization of Training Loss: The vanilla Transformer models trained using a small amount of high-quality data exhibited stabilization of the training losses at a value of around 1, as predicted by the theoretical proposition. This stabilization indicates a convergence of the model’s learning process and suggests a correlation between training loss and model performance.
Global Energy Function for Transformer Models
As part of their theoretical framework, the researchers developed a global energy function for the layered structure of transformer models. They utilized the majorization-minimization technique to create this energy function, which captures the dynamics and interactions within the model.
Conclusion
In conclusion, Huawei researchers introduced a theoretical framework focused on understanding the memorization process and performance dynamics of transformer-based language models (LMs). Through experiments using GPT-2 and vanilla Transformer models, they validated the theoretical results and provided valuable insights into the optimal cross-entropy loss, which can guide and improve decision-making in model training. By unraveling the intricacies of memorization and performance dynamics, this research paves the way for advancing transformer-based models and addressing the challenges associated with larger models in the field of natural language processing.
While this theoretical framework sheds light on the memorization process and performance dynamics of transformer-based LMs, further research is needed to explore practical implications and potential enhancements for these models. With the rapid evolution of transformer-based architectures, this research contributes to our understanding of how these models learn, generalize, and perform in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰