Generating Private Synthetic Data: Google AI’s New ML Methods
In today’s data-driven world, privacy has become a major concern when it comes to training machine learning models. As these models rely on large datasets, there is a growing need to protect the privacy of individuals whose data contributes to these models. To address this challenge, Google AI researchers have proposed new machine learning methods for generating differentially private synthetic data. This article will explore the innovative approach taken by Google AI and the potential impact it can have on privacy-preserving machine learning.
The Importance of Differentially Private Synthetic Data
Before we delve into the new methods proposed by Google AI, let’s first understand the significance of differentially private synthetic data. Differentially private synthetic data is artificially created data that reflects the key characteristics of the original dataset while preserving user privacy. By generating synthetic data, organizations can train predictive models without compromising sensitive information. This is particularly important when dealing with high-dimensional datasets that are used for various tasks.
The Current Landscape of Privacy-Preserving Data Generation
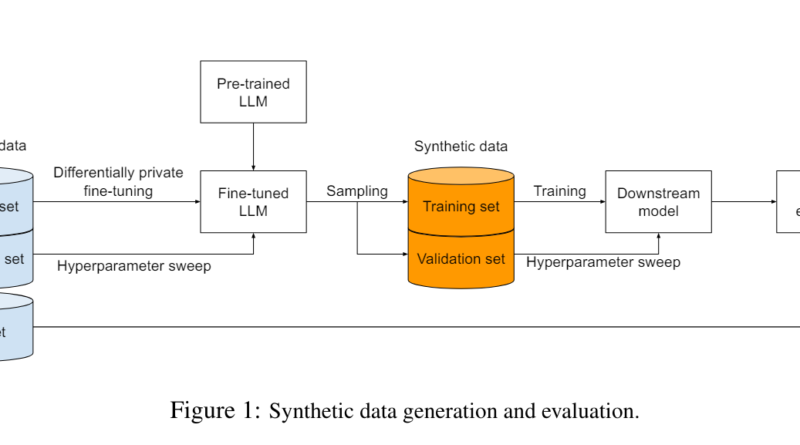
Traditionally, privacy-preserving data generation has involved training models directly with differentially private machine learning (DP-ML) algorithms. While this approach provides strong privacy guarantees, it can be computationally demanding, especially when working with large datasets. Previous models, such as the one described in “Harnessing large-language models to generate private synthetic text” by Google AI, have used large-language models (LLMs) combined with differentially private stochastic gradient descent (DP-SGD) to generate private synthetic data. These models involve fine-tuning an LLM trained on public data using DP-SGD on a sensitive dataset, ensuring that the generated synthetic data does not reveal any specific information about the individuals in the sensitive dataset.
Google AI’s Enhanced Approach to Differentially Private Synthetic Data Generation
Building upon previous research, Google AI researchers have introduced an enhanced approach to generating differentially private synthetic data. This approach leverages parameter-efficient fine-tuning techniques, such as LoRa (Low-Rank Adaptation) and prompt fine-tuning, to improve the quality of synthetic data while reducing computational overhead.
LoRa Fine-Tuning
One of the techniques used in Google AI’s approach is LoRa fine-tuning. In this method, each parameter, denoted by W, in the model is replaced with W + LR, where L and R are low-rank matrices. During the fine-tuning process, only L and R are trained, effectively modifying a smaller number of parameters. This approach reduces computational overhead and potentially improves the quality of the synthetic data.
Prompt Fine-Tuning
Prompt fine-tuning is another technique used in Google AI’s approach. It involves inserting a “prompt tensor” at the start of the network and only training its weights. By modifying only the input prompt used by the LLM, the fine-tuning process is restricted to a subset of the model’s parameters. This further reduces computational requirements while maintaining the quality of the synthetic data.
Empirical Results and Performance
Empirical results from Google AI’s research have shown promising outcomes. LoRa fine-tuning, which modifies roughly 20 million parameters, outperformed both full-parameter fine-tuning and prompt-based tuning, which only modifies about 41 thousand parameters. This suggests that there is an optimal number of parameters that balance the trade-off between computational efficiency and data quality.
Classifiers trained on synthetic data generated by LoRa fine-tuned LLMs demonstrated superior performance compared to classifiers trained on synthetic data from other fine-tuning methods. In some cases, the performance even surpassed classifiers trained directly on the original sensitive data using DP-SGD. This showcases the effectiveness of Google AI’s proposed method in generating high-quality synthetic data while preserving user privacy.
The Potential Impact of Google AI’s Approach
Google AI’s approach to generating differentially private synthetic data using parameter-efficient fine-tuning techniques has the potential to revolutionize privacy-preserving machine learning. By fine-tuning a smaller subset of parameters, this method reduces computational requirements and improves the quality of the synthetic data. This not only safeguards user privacy but also maintains high utility for training predictive models.
Organizations can leverage this approach to unlock the potential of sensitive data without compromising privacy. As privacy concerns continue to grow, the ability to generate differentially private synthetic data becomes increasingly valuable. Google AI’s method offers a practical solution that balances the need for privacy and the need for accurate predictive models.
Conclusion
Google AI’s new machine learning methods for generating differentially private synthetic data represent a significant advancement in privacy-preserving machine learning. By leveraging parameter-efficient fine-tuning techniques, such as LoRa and prompt fine-tuning, Google AI aims to provide high-quality synthetic data while protecting user privacy. The empirical results demonstrate the effectiveness of this approach and its potential for broader applications in privacy-preserving machine learning.
As the field of machine learning continues to evolve, it is crucial to prioritize privacy. With innovative approaches like the one proposed by Google AI, organizations can unlock the full potential of sensitive data while upholding user privacy. This paves the way for a future where privacy and machine learning can coexist harmoniously.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰