Google AI Introduces Titans: A Revolutionary Machine Learning Architecture Redefining Memory and Attention for Long-Term Contexts
In the ever-evolving field of machine learning, sequence modeling plays a pivotal role across diverse applications such as natural language processing (NLP), video understanding, and time-series forecasting. Transformers, with their groundbreaking attention-based architecture, have been instrumental in advancing sequence modeling. However, despite their success, Transformers face significant limitations in processing long-term dependencies due to the quadratic complexity of their attention mechanisms, which grows with the input length. This computational bottleneck restricts their applicability in tasks requiring large-scale context windows.
To address these challenges, Google AI Research has introduced Titans, a next-generation machine learning architecture that redefines long-term memory management and attention mechanisms. By introducing a dual-memory system, Titans bridges the gap between short-term dependency modeling and long-term historical context retention, enabling efficient processing of sequences that extend well beyond two million tokens.
The Challenges of Sequence Modeling
1. Scalability Issues with Transformers
Transformers rely on attention mechanisms that act as associative memory blocks, storing and retrieving key-value pairs. While highly effective, this mechanism suffers from quadratic time and memory complexity. This limitation becomes a critical barrier in real-world applications where large context windows are essential.
For example:
- NLP: Long-form content generation and multi-document summarization.
- Video Understanding: Processing frames spanning lengthy video sequences.
- Time-Series Forecasting: Modeling patterns across extended temporal datasets.
2. Current Approaches and Their Limitations
Several strategies have been developed to tackle these challenges:
- Linear Recurrent Models: Efficient training and inference but limited in their ability to model complex dependencies.
- Optimized Transformers: Sparse attention matrices and kernel-based approaches improve efficiency but still fall short in extremely long contexts.
- Memory-Augmented Models: Persistent and contextual memory designs, while promising, often face fixed-size constraints or memory overflow issues.
These methods address specific pain points but fail to provide a holistic solution for long-term sequence modeling.
Titans: A Revolutionary Architecture By Google
Google AI Research’s Titans introduces a novel neural long-term memory module that complements traditional attention mechanisms. The innovation lies in its ability to dynamically learn how to memorize during test time, functioning as a meta in-context learner. This dual-memory system ensures precise dependency modeling while simultaneously storing and retrieving persistent information for long-term use.
Key Features of Titans
1. Dual-Memory System
Titans employs a complementary memory architecture:
- Short-Term Memory (Attention Mechanism): Optimized for handling local dependencies and precise modeling within limited contexts.
- Long-Term Memory (Neural Memory Module): Designed for persistent storage of historical data, enabling the model to retain and utilize information from extensive sequences.
2. Modular Design
The Titans architecture is built around three core components:
- Core Module: Utilizes attention mechanisms with a restricted window size for primary data processing.
- Long-Term Memory Branch: Implements neural memory to store historical context.
- Persistent Memory Component: Incorporates learnable, data-independent parameters for enhanced memory retention.
3. Advanced Optimization Techniques
Titans leverages a range of technical optimizations:
- Residual Connections: Enhance stability during training.
- SiLU Activation Functions: Improve non-linear transformations.
- ℓ2-Norm Normalization: Standardizes queries and keys for consistent performance.
- 1D Depthwise-Separable Convolutions: Increase computational efficiency after query, key, and value projections.
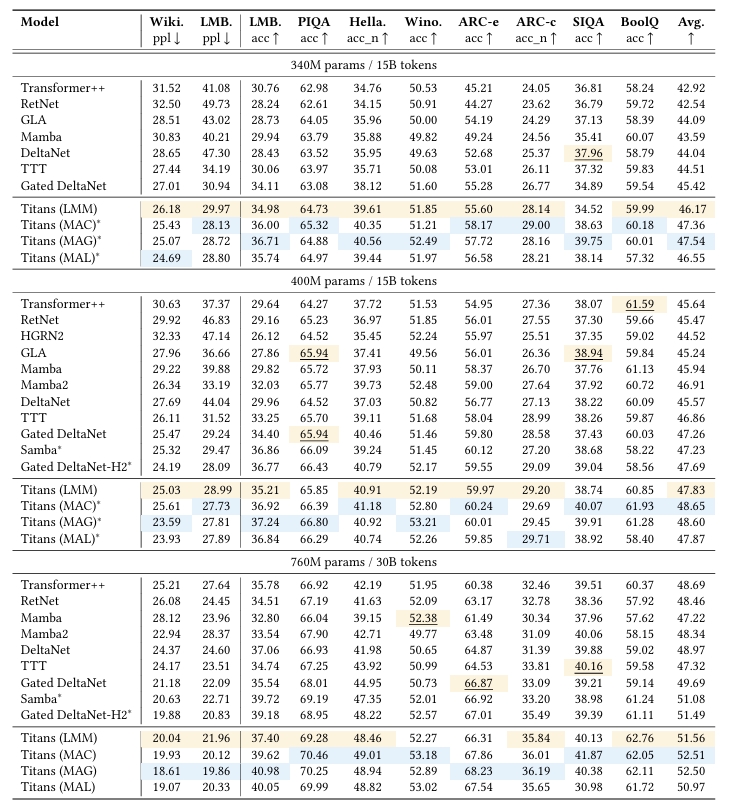
Performance Benchmarks
Titans have been rigorously evaluated across a variety of tasks, showcasing superior performance in handling long-term dependencies.
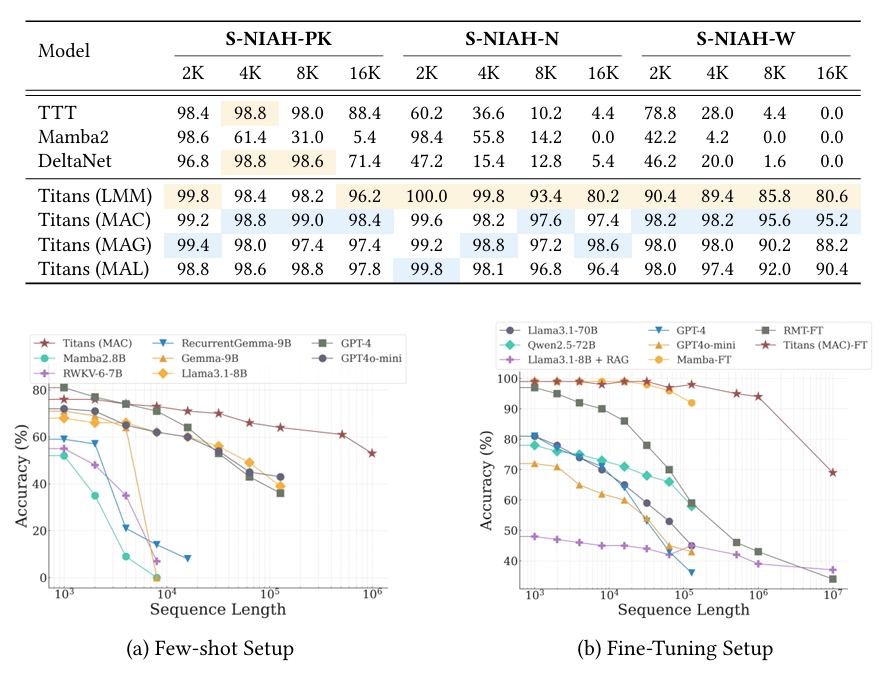
1. Needle-in-a-Haystack (NIAH) Tasks
Titans outperform traditional models in identifying specific patterns within extensive sequences.
- Sequence lengths: 2K to 16K tokens.
- Titans’ neural memory module provides significant advantages in efficiency and accuracy.
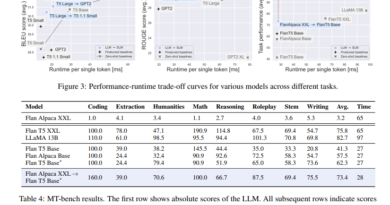
2. Comparison with Existing Models
Across its three variants—MAC, MAG, and MAL—Titans consistently surpasses hybrid models like Samba and Gated DeltaNet-H2.
- MAC and MAG Variants: Excel in processing longer dependencies.
- MAL Variant: Demonstrates competitive performance but is better suited for tasks with limited context requirements.
Applications of Titans
1. Natural Language Processing (NLP)
Titans opens new possibilities for:
- Long-Form Text Generation: Producing coherent and contextually relevant content over extended sequences.
- Multi-Document Summarization: Combining insights from multiple documents into a concise summary.
2. Video Understanding
The ability to handle sequences exceeding two million tokens makes Titans ideal for video analytics, such as identifying patterns across thousands of frames.
3. Time-Series Analysis
Titans’ dual-memory system excels in modeling recurring patterns and anomalies in long-term time-series datasets, enhancing applications like financial forecasting and climate modeling.
4. Scientific Research
The architecture’s efficiency and scalability make it a valuable tool for processing large-scale datasets in fields such as genomics and astrophysics.
Technical Advantages
1. Efficient Memory Management
Titans integrate mechanisms for memory erasure and deep non-linear memory management, ensuring optimal utilization of computational resources.
2. Adaptability
The model dynamically adjusts its memory strategies based on the complexity of the task, making it highly versatile across domains.
3. Scalability
Titans’ ability to process sequences beyond two million tokens represents a significant leap in scalability, outperforming most existing architectures.
How Titans Stand Out
| Feature | Titans | Traditional Models |
|---|---|---|
| Memory Integration | Dual-memory (short-term + long-term) | Short-term memory only |
| Sequence Length Capacity | Over 2 million tokens | Limited to tens of thousands |
| Dynamic Memory Adaptation | Yes | No |
| Scalability | High | Moderate |
Future Directions
Google AI Research aims to extend Titans’ capabilities with:
- Expanded Context Windows: Further increasing sequence lengths for more complex tasks.
- Domain-Specific Fine-Tuning: Optimizing Titans for specific industries like healthcare and finance.
- Enhanced Efficiency: Reducing training and inference times without compromising accuracy.
Conclusion
Google AI Research’s Titans represents a monumental advancement in machine learning architectures. By combining attention mechanisms with a novel neural memory module, Titans addresses the limitations of traditional sequence modeling approaches. Its ability to dynamically learn how to memorize during test time, process extensive sequences, and manage long-term dependencies sets a new standard in the field.
As industries continue to demand more robust and scalable solutions for complex tasks, Titans paves the way for a future where machine learning systems can seamlessly adapt to the challenges of real-world applications. With its innovative architecture and promising performance benchmarks, Titans is poised to redefine the possibilities of long-term memory and attention in AI.
Check out the Paper. All credit for this research goes to the researchers of this project.
Do you have an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3800+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Agents 😁
If you like our work, you will love our Newsletter 📰