Addressing Safety and Reliability in AI with Simplified Transformers
Transformers have emerged as a powerful tool in the field of artificial intelligence, revolutionizing systems that understand and generate human language. However, as these models become more complex and larger in size, they also become increasingly difficult to understand and control. This complexity can lead to unexpected behaviors and pose challenges in terms of safety and reliability.
To address these issues, researchers from Anthropic have proposed a novel mathematical framework that simplifies the understanding of transformers. By focusing on smaller, less complex models, the framework provides a clearer perspective on how transformers process information and enables the identification of algorithmic patterns that can be applied to larger, more complex systems.
The Challenge of Complexity in Transformer Models
As transformer models grow in complexity, their outputs become more unpredictable, sometimes leading to unexpected and even harmful results. The open-ended design of transformers allows for flexible and powerful applications, but it also introduces a broad scope for unintended behaviors. This has raised concerns about the safety and reliability of deploying transformer models in real-world scenarios.
Efforts have been made to address the challenge of complexity and unpredictability in transformers through mechanistic interpretability. This approach involves breaking down the intricate operations of transformers into more comprehensible components, essentially reverse-engineering the complex mechanisms to facilitate analysis and understanding. While traditional methods have achieved some success in interpreting simpler models, transformers, with their deep and intricate architecture, present a more formidable challenge.
Proposing a Mathematical Framework for Simplification

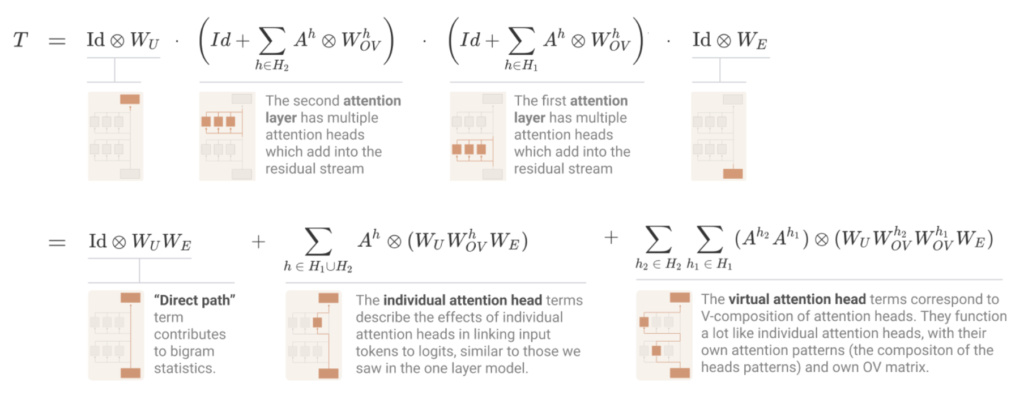
To simplify the understanding of transformers, researchers from Anthropic have introduced a mathematical framework that focuses on smaller, less complex models. This framework reinterprets the operations of transformers in a mathematically equivalent way, making them easier to manage and understand. Specifically, the framework examines transformers with no more than two layers and focuses solely on attention blocks, excluding other common components like multi-layer perceptrons (MLPs) for clarity and simplicity.
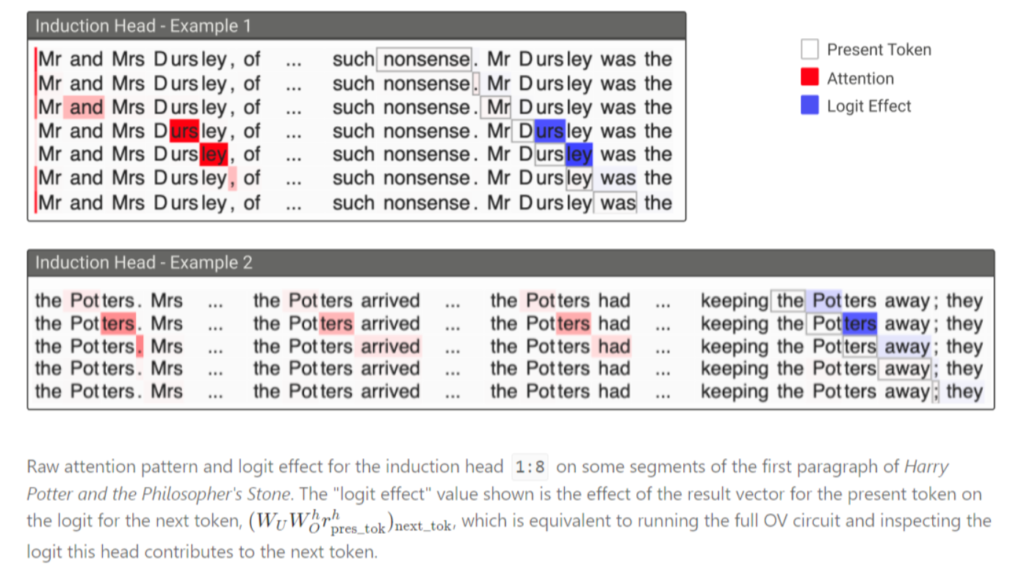
By studying these smaller models, the research team has gained a clearer understanding of how transformers process information. One key finding is the role of specific attention heads, referred to as ‘induction heads’, in facilitating in-context learning. These induction heads exhibit significant capabilities only in models with at least two attention layers. This insight into the workings of transformers opens up new possibilities for understanding and improving larger, more complex systems.
Empirical Insights and Quantifiable Results
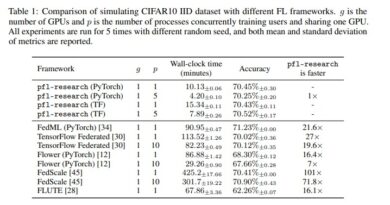
The research conducted by Anthropic has provided empirical insights into the functionality of transformer models. For instance, it was found that zero-layer transformers primarily model bigram statistics directly accessible from the weights. On the other hand, one and two-layer attention-only transformers exhibit more complex behaviors through the composition of attention heads. Two-layer models, in particular, use these compositions to create sophisticated in-context learning algorithms, advancing our understanding of how transformers learn and adapt.
These empirical results offer quantifiable evidence of the capabilities and behaviors of transformer models. By examining and analyzing the outputs of smaller, simplified models, researchers can gain valuable insights that can be extrapolated to larger, more powerful systems. This understanding lays the groundwork for anticipating and mitigating challenges in transformer models, ultimately enhancing their reliability and performance.
Enhancing Interpretability and Model Safety
The proposed mathematical framework for simplifying transformer models has significant implications for the interpretability and safety of these models. By breaking down the complex operations of transformers into more manageable components, researchers can gain a deeper understanding of how these models function. This understanding, in turn, enables the identification of potential issues and the development of strategies to address them.
Improving the interpretability of transformer models is crucial for ensuring their safety and reliability. By having a clearer understanding of the inner workings of transformers, researchers and developers can detect and mitigate potential risks and unintended behaviors. This not only enhances the trustworthiness of transformer models but also promotes their responsible deployment in real-world applications.
Future Directions and Advancements
The research conducted by Anthropic represents a significant step towards simplifying transformer models and enhancing their interpretability. However, there are still many avenues for future exploration and advancements in this field.
One potential direction is the application of this mathematical framework to larger, more complex transformer models. By extending the framework to higher-layered models and incorporating additional components such as multi-layer perceptrons, researchers can gain a more comprehensive understanding of the behavior and capabilities of transformers at scale.
Furthermore, the insights gained from studying smaller models can inform the development of more efficient and effective training methods for transformer models. By leveraging the algorithmic patterns identified in simpler models, researchers can potentially optimize the learning and adaptation processes of larger models, leading to improved performance and generalization.
Conclusion
The proposed mathematical framework for simplifying transformer models is a significant contribution to the field of artificial intelligence. By focusing on smaller, less complex models, researchers have gained valuable insights into the inner workings of transformers and identified algorithmic patterns that can be applied to larger systems. This research opens up new possibilities for enhancing the interpretability, safety, and reliability of transformer models, ensuring that they continue to evolve innovatively and securely. With ongoing advancements and further research, transformer models have the potential to drive even greater progress in the field of artificial intelligence.
Explore 3600+ latest AI tools at AI Toolhouse . Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools
If you like our work, you will love our Newsletter