AI Paper from China Introduces BGE-M3: A Breakthrough in Multilingual Text Embedding
Artificial Intelligence (AI) continues to revolutionize the way we process and understand human language. One of the latest advancements in this field comes from researchers in China who have introduced BGE-M3, a new member of the BGE model series. This breakthrough model offers multi-linguality, supports over 100 languages, and addresses several limitations of existing embedding models. In this article, we will explore the features and capabilities of BGE-M3, and understand why it is a significant step forward in the field of text embedding.
The Need for Multilingual Text Embedding
Language is a powerful tool for communication, and with the rise of global connectivity, the ability to process and understand multiple languages has become increasingly important. However, traditional embedding models have often been limited to a single language, making it challenging to handle multilingual data effectively. This restriction hampers the development of applications that require language-agnostic text processing, such as machine translation, sentiment analysis, and information retrieval.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Existing embedding models have made notable progress in the field but are limited in terms of language support, retrieval functionalities, and input granularities. For example, models like Contriever, GTR, and E5 have shown promise but are primarily trained for English and support only one retrieval functionality. This limitation prevents them from achieving optimal performance when dealing with diverse languages and varied retrieval tasks.
Introducing BGE-M3: Multi-Lingual, Multi-Functional, and Multi-Granular
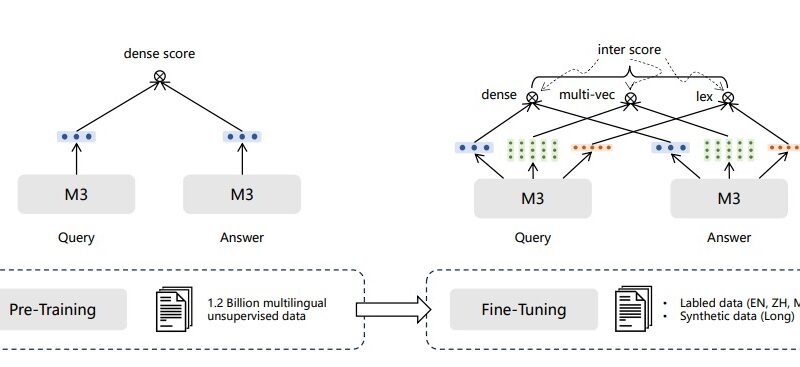
BGE-M3, developed by researchers from the University of Science and Technology of China in collaboration with BAAI (Beijing Academy of Artificial Intelligence), aims to overcome the limitations of existing text embedding models. The ‘M3’ in BGE-M3 stands for three key properties of the model: Multi-Lingual, Multi-Functional, and Multi-Granular.
Multi-Lingual Support
One of the fundamental features of BGE-M3 is its ability to support over 100 languages. This makes it a truly versatile model that can handle text data from different linguistic backgrounds. By incorporating diverse multi-lingual datasets from sources like Wikipedia and S2ORC, the model has been trained on a wide range of languages to ensure accurate representation and processing of text in various languages.
Multi-Functional Retrieval
Another significant advantage of BGE-M3 is its support for multiple retrieval functionalities. Traditional models are often limited to a specific retrieval task, such as dense retrieval or lexical retrieval. In contrast, BGE-M3 allows for dense, sparse, and multi-vector retrieval. This flexibility enables the model to handle a broader range of retrieval tasks, making it more suitable for real-world applications that require diverse retrieval functionalities.
Multi-Granular Handling
BGE-M3 is capable of processing input data with varied granularities, from short sentences to lengthy documents. It can handle sequences with up to 8192 tokens, making it suitable for processing large and complex text data. This ability to handle long input texts is a crucial improvement over existing models, which often struggle with longer sequences.
Self-Knowledge Distillation Approach
To develop BGE-M3, researchers used a novel self-knowledge distillation approach. This approach involves optimizing batching strategies for large input lengths and leveraging large-scale, diverse multi-lingual datasets. By combining relevance scores from different retrieval functionalities, they created a teacher signal that aids the model in efficiently performing multiple retrieval tasks. This distillation process enhances the model’s performance and enables it to outperform existing models in various languages.
Evaluating the Performance of BGE-M3
To assess the effectiveness of BGE-M3, researchers conducted several experiments. They evaluated the model’s performance with multilingual text, varied sequence length, and narrative question-answering responses. The evaluation metric used was nDCG@10 (normalized discounted cumulative gain), which measures the ranking quality of search results.
The experiments demonstrated that BGE-M3 outperformed existing models in more than 10 languages, while delivering comparable results in English. The model’s performance remained consistent with smaller input lengths but showcased improved results with longer texts. These findings highlight the model’s effectiveness in addressing the identified limitations of existing methods.
Conclusion: A Leap Forward in Text Embedding
BGE-M3 represents a significant advancement in the field of text embedding models. Its multi-lingual support, multi-functional retrieval capabilities, and ability to handle various input granularities make it a versatile solution for a wide range of applications. By addressing the limitations of existing models, BGE-M3 opens up new possibilities for multilingual text processing, information retrieval, and other AI-driven tasks.
The research paper introducing BGE-M3 has already garnered attention from the AI community and holds great promise for the future of natural language processing. As AI continues to evolve, breakthroughs like BGE-M3 pave the way for more accurate and comprehensive language understanding, contributing to the development of smarter and more efficient AI systems.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰