AlphaMonarch-7B: The Ultimate Non-Merge 7B Model on the Open LLM Leaderboard
In the field of artificial intelligence, creating a model that can seamlessly hold conversations and tackle complex problems has always been a challenge. Striking a balance between conversational fluency and reasoning prowess is essential, as models that excel in one aspect may lack in the other. However, a breakthrough has been made with the development of AlphaMonarch-7B, one of the best-performing non-merge 7B models on the Open LLM Leaderboard.
The Quest for Balance
Artificial intelligence has made significant advancements in recent years, allowing models to carry out conversations that closely resemble human interactions. However, when it comes to complex reasoning tasks, these models often fall short. This has led to the realization that there is a need for a model that can strike a better balance between conversational abilities and reasoning capabilities.
Introducing AlphaMonarch-7B
AlphaMonarch-7B is part of a new family of models that aims to achieve this desired balance. It has been specifically designed to excel in both conversation and problem-solving. Through a unique fine-tuning process known as DPO (Domain Pre-training Optimization), AlphaMonarch-7B enhances its ability to reason without compromising its conversational skills.
Leveraging Unique Data and Fine-Tuning
To achieve its exceptional performance, AlphaMonarch-7B leverages a unique dataset and the DPO fine-tuning process. The dataset provides the model with a diverse range of conversational and reasoning scenarios, allowing it to learn from a wide array of examples. The DPO fine-tuning process further refines the model’s abilities by optimizing its performance on specific benchmarks.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
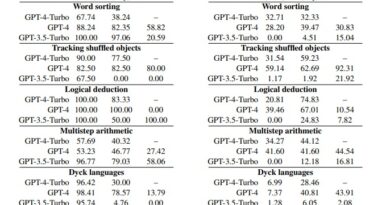
Impressive Performance on Benchmarks
AlphaMonarch-7B’s capabilities are evident through its remarkable performance on various benchmarks, including the Open LLM Leaderboard, Nous, EQ-bench, and MT-Bench. While it performs well across all these benchmarks, it particularly shines on MT-Bench, showcasing its ability to handle multi-turn questions effectively. This demonstrates its superior conversational skills while maintaining strong reasoning abilities.
The Open LLM Leaderboard
The Open LLM Leaderboard is an important platform that tracks, ranks, and evaluates open language model models and chatbots. It provides a standardized evaluation framework to assess the performance of different models. AlphaMonarch-7B’s outstanding performance on this leaderboard further solidifies its position as one of the best-performing non-merge 7B models.
A Versatile Tool for AI Applications
The development of AlphaMonarch-7B represents a significant step forward in the field of artificial intelligence. By addressing the shortcomings of previous models, it offers a more balanced solution that combines conversational fluency with reasoning power. This opens up new possibilities for a range of applications, from virtual assistants that are more natural and helpful to powerful tools for solving complex problems.
Conclusion
AlphaMonarch-7B is undeniably one of the best-performing non-merge 7B models on the Open LLM Leaderboard. Its unique fine-tuning process and balanced approach to conversation and reasoning make it a versatile tool in the field of artificial intelligence. With its exceptional performance on various benchmarks, AlphaMonarch-7B is set to make a significant impact in the quest for AI systems that can converse and reason at high levels.
Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰