BitNet b1.58: Pioneering the Future of Efficient Large Language Models
The field of artificial intelligence (AI) has witnessed a remarkable advancement with the development of Large Language Models (LLMs). These models have revolutionized our ability to process, understand, and generate human-like text. However, as LLMs grow in size and complexity, they pose challenges in terms of computational resources and environmental impact. The pursuit of efficient LLMs without compromising performance has become a primary focus for researchers and developers in the AI community.
The Challenge of Computational Resources
Traditional LLMs demand significant computational resources during both the training and operational phases. The processing power and memory required result in high costs and a notable environmental footprint. This has prompted researchers to explore alternative architectures that promise comparable effectiveness with reduced resource usage.
One approach that has been explored in the past is post-training quantization. This involves reducing the precision of weights within a model to lessen the computational load. While this method has been successful in some industrial applications, it often comes at the cost of compromising efficiency for model performance.
Introducing BitNet b1.58
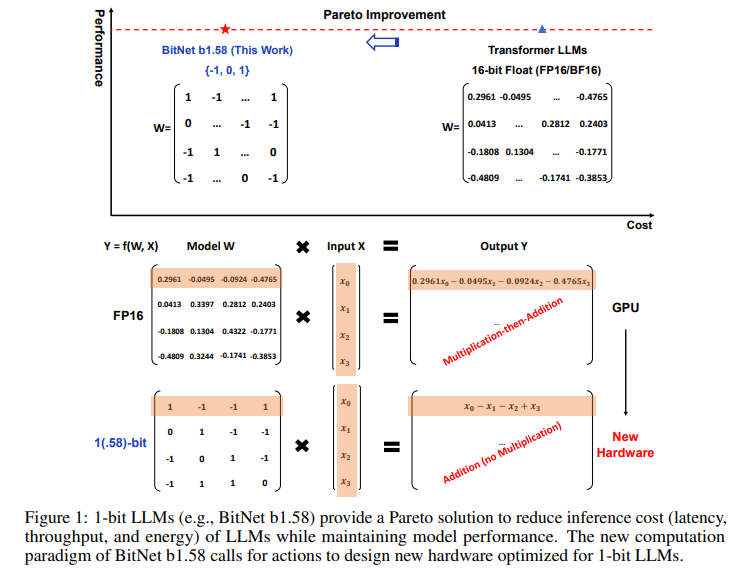
BitNet b1.58, developed by a collaborative research team from Microsoft Research and the University of Chinese Academy of Sciences, presents a novel solution to the challenge of efficient LLMs. It employs a groundbreaking approach utilizing 1-bit ternary parameters for every model weight. This shift from traditional 16-bit floating values to a 1.58-bit representation strikes an optimal balance between efficiency and performance.
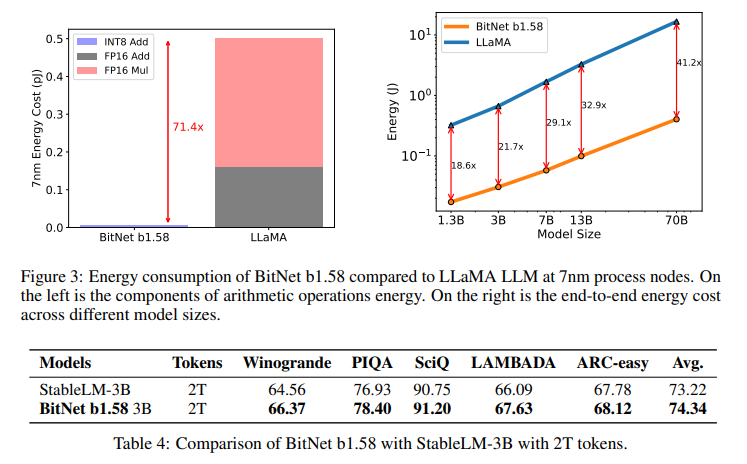
By adopting ternary {-1, 0, 1} parameters, BitNet b1.58 significantly reduces the demand for computational resources. This is achieved through intricate quantization functions and optimizations that maintain high-performance levels comparable to those of full-precision LLMs. The model showcases remarkable reductions in latency, memory usage, throughput, and energy consumption, making it a pioneering solution in the field of efficient LLMs .
Balancing Efficiency and Performance
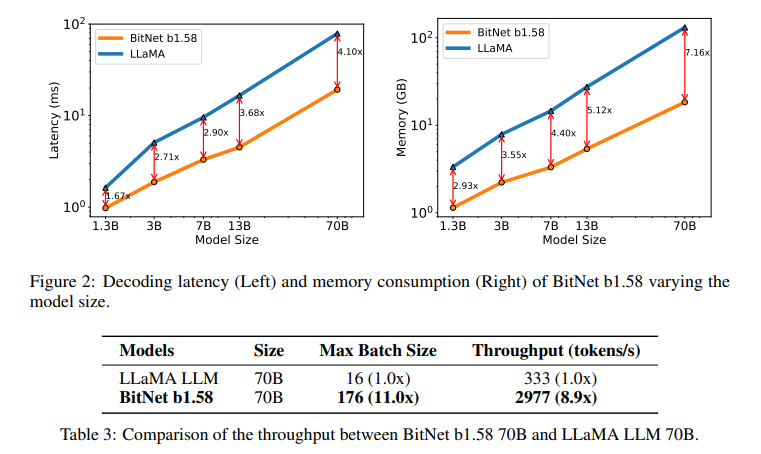
The performance of BitNet b1.58 demonstrates that it is possible to achieve high efficiency without compromising the quality of outcomes. Comparative studies have shown that BitNet b1.58 matches and occasionally exceeds the performance of conventional LLMs across various tasks. This is achieved with significantly faster processing speeds and lower resource consumption, showcasing the model’s potential to redefine the landscape of LLM development.
The innovation behind BitNet b1.58 challenges the conventional norms of precision in LLMs. While traditional models rely on high precision for optimal performance, BitNet b1.58 demonstrates that a reduced bit representation can achieve comparable outcomes with significant efficiency gains. This opens up possibilities for developing large-scale language models that are more accessible and sustainable in terms of computational resources and environmental impact.
Integrating BitNet b1.58 into Current and Future Computing Paradigms
The introduction of BitNet b1.58 has implications beyond individual model performance. It sets the stage for integrating 1-bit LLMs into existing and future computing paradigms. By reducing resource demands, BitNet b1.58 enables the deployment of LLMs in environments with limited computational capabilities. This opens up opportunities for new applications in areas such as edge computing, where efficient AI models are crucial for real-time decision-making.
Furthermore, the efficient design of BitNet b1.58 aligns with the growing importance of sustainability in AI research and development. As the demand for AI models continues to rise, finding ways to minimize resource consumption becomes essential. BitNet b1.58 offers a glimpse into a future where AI models can achieve remarkable performance while minimizing their environmental impact.
Conclusion
BitNet b1.58 represents a significant milestone in the development of efficient large language models. By pioneering the use of 1-bit ternary parameters, it offers a promising solution to the challenge of balancing efficiency and performance. The model’s ability to achieve comparable outcomes with reduced resource consumption opens up new possibilities for the deployment of LLMs in various computing environments.
As AI continues to play a crucial role in our lives, the development of efficient LLMs becomes increasingly important. BitNet b1.58 sets the stage for future advancements in the field, redefining the landscape of large language model development and paving the way for more accessible and sustainable AI technologies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰