Boost AI with NVIDIA TensorRT
In the world of artificial intelligence (AI), deep learning models have shown remarkable capabilities in tasks such as image recognition, natural language processing, and generative AI. However, as these models grow in size and complexity, there is a pressing need to optimize them for faster inference on GPUs. To address this challenge, NVIDIA AI has released the TensorRT Model Optimizer, a comprehensive library that quantizes and compresses deep learning models for optimized inference on GPUs.
The Need for Model Optimization
Generative AI models, in particular, require significant processing power to generate creative outputs such as images, text, or videos. These models perform complex calculations to consider various factors like lighting, texture, and object placement, resulting in hefty processing demands. Running these models at scale can be expensive and time-consuming. Therefore, it is essential to optimize the models to improve their inference speed and reduce memory footprints.
Introducing the TensorRT Model Optimizer
The NVIDIA TensorRT Model Optimizer is a unified library of state-of-the-art model optimization techniques, including quantization and sparsity. It aims to accelerate the inference speed of deep learning models while maintaining high accuracy.
Post-training Quantization (PTQ)
One of the optimization techniques offered by the TensorRT Model Optimizer is post-training quantization (PTQ). PTQ reduces the memory usage and enables faster computations by converting the model’s data to lower precision formats. However, achieving accurate quantization without compromising accuracy remains a challenge. To address this, the TensorRT Model Optimizer provides advanced calibration algorithms for PTQ, including INT8 SmoothQuant and INT4 AWQ. These calibration algorithms ensure that the quantized model maintains accuracy comparable to the original model.
Quantization Aware Training (QAT)
To enable 4-bit floating-point inference without lowering accuracy, the TensorRT Model Optimizer incorporates Quantization Aware Training (QAT) integrated with leading training frameworks. QAT works by determining scaling factors during training and incorporating simulated quantization loss into the fine-tuning process. This approach allows for efficient inference with reduced memory requirements and faster computations.
Post-training Sparsity
Another optimization technique offered by the TensorRT Model Optimizer is post-training sparsity. Sparsity techniques remove unnecessary connections within the model, streamlining calculations and further accelerating inference. These techniques provide additional speedups while preserving model quality.
Evaluating the TensorRT Model Optimizer
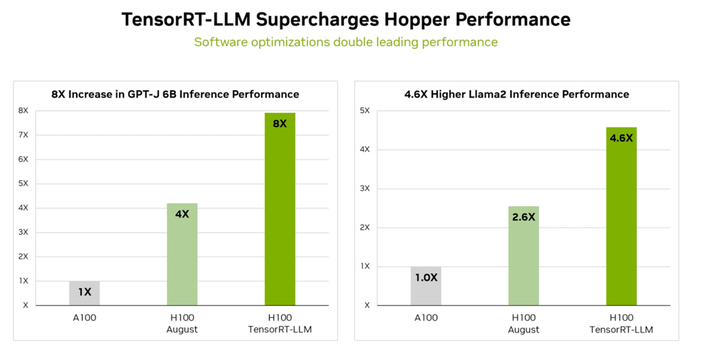
The TensorRT Model Optimizer has been extensively evaluated, both qualitatively and quantitatively, on various benchmark models to ensure its efficiency for a wide range of tasks. In one benchmark test, the INT4 AWQ technique achieved a 3.71 times speedup compared to FP16 on a Llama 3 model. Furthermore, tests comparing FP8 and INT4 to FP16 on different GPUs demonstrated speedups of 1.45x on RTX 6000 Ada and 1.35x on a L40S without FP8 MHA. INT4 performed similarly, with a 1.43x speedup on the RTX 6000 Ada and a 1.25x speedup on the L40S without FP8 MHA. These results showcase the significant performance improvements achieved by leveraging the TensorRT Model Optimizer.
When it comes to image generation, the TensorRT Model Optimizer excels in producing high-quality images with minimal loss in accuracy. Utilizing NVIDIA INT8 and FP8, the optimizer can generate images with quality almost equivalent to the FP16 baseline while speeding up inference by 35 to 45 percent .
Conclusion
The NVIDIA TensorRT Model Optimizer addresses the need for accelerated inference speed in deep learning models, particularly in the field of generative AI. By leveraging advanced optimization techniques such as post-training quantization and sparsity, it allows developers to reduce model complexity and accelerate inference while preserving model accuracy. The integration of Quantization Aware Training (QAT) further enables 4-bit floating-point inference without compromising accuracy. The TensorRT Model Optimizer has demonstrated significant performance improvements, as evidenced by benchmarking data and MLPerf Inference v4.0 results.
In conclusion, the TensorRT Model Optimizer from NVIDIA AI equips developers with powerful tools to optimize their deep learning models for efficient and accelerated inference on GPUs. As AI applications continue to evolve and demand faster processing speeds, the TensorRT Model Optimizer plays a crucial role in unlocking the full potential of generative AI and other complex deep learning tasks.
References
- https://developer.nvidia.com/blog/accelerate-generative-ai-inference-performance-with-nvidia-tensorrt-model-optimizer-now-publicly-available/
- https://github.com/NVIDIA/TensorRT-Model-Optimizer
- https://developer.nvidia.com/tensorrt
- https://docs.nvidia.com/deeplearning/tensorrt/
- https://www.linkedin.com/posts/songhanmit_explore-nvidia-tensorrt-model-optimizer-with-activity-7194104648767602689-o3kd
- https://nvidia.github.io/TensorRT-Model-Optimizer/getting_started/1_overview.html
- https://docs.nvidia.com/tensorrt/index.html
- https://www.tensorflow.org/lite
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰