Deciphering the Impact of Scaling Factors on LLM Finetuning: Insights from Bilingual Translation and Summarization
The field of Natural Language Processing (NLP) has witnessed remarkable advancements in recent years, with Large Language Models (LLMs) leading the way. These LLMs, such as GPT-3 and T5, have demonstrated impressive capabilities in tasks like machine translation and summarization. However, harnessing the full potential of these models requires a deep understanding of the impact of scaling factors on LLM finetuning. In this article, we will explore the insights gained from bilingual translation and summarization tasks and shed light on the intricate relationship between scaling factors and the performance of LLMs.
The Challenge of LLM Finetuning
LLMs are pretrained on vast amounts of text data, enabling them to capture rich linguistic patterns and semantic representations. However, to make these models task-specific, they need to be fine-tuned using domain-specific data. The challenge lies in determining the optimal scaling factors that maximize the performance of LLMs in a given task.
Traditionally, two main approaches are employed for fine-tuning LLMs: full-model tuning (FMT) and parameter-efficient tuning (PET). FMT adjusts all the model’s parameters during finetuning, providing comprehensive adaptability but at the cost of efficiency. On the other hand, PET techniques, such as prompt tuning and Low Rank Adaptation (LoRA), only tweak a small subset of parameters, resulting in a more streamlined but less flexible approach.
Insights from Bilingual Translation
Bilingual machine translation serves as an excellent testbed for studying the impact of scaling factors on LLM finetuning. In a recent study conducted by researchers from Google DeepMind and Google Research, the effectiveness of different scaling factors was systematically analyzed.
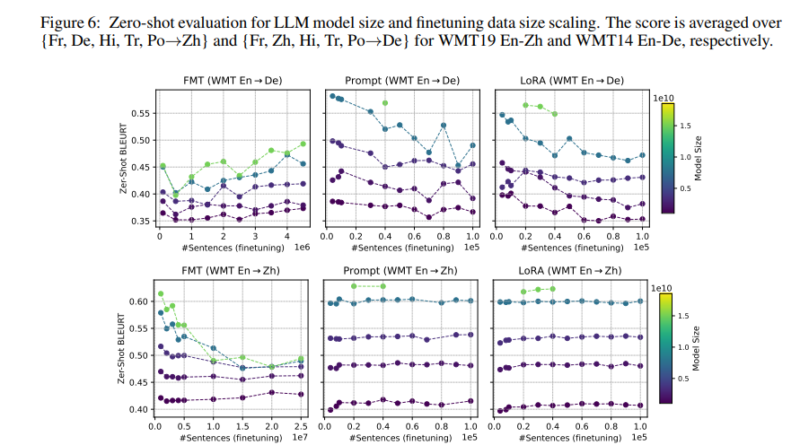
The study focused on bilingual LLMs ranging from 1 billion to 16 billion parameters, evaluating their performance in machine translation tasks. The findings revealed that scaling up the LLM model size had a more pronounced effect on finetuning performance compared to expanding the pretraining data or scaling up the PET parameters. Increasing the LLM model size from 1 billion to 16 billion parameters significantly enhanced the fine-tuning performance in bilingual translation tasks.
Interestingly, the study also highlighted the superior capabilities of PET techniques, such as prompt tuning and LoRA, in leveraging the pre-existing knowledge encoded within the LLMs. While PET techniques generally benefit less from parameter scaling than FMT, they exhibit remarkable performance in utilizing the inherent linguistic knowledge of the models.
Insights from Summarization Tasks
Summarization tasks provide another avenue for investigating the impact of scaling factors on LLM finetuning. The same research study conducted by Google DeepMind and Google Research examined the performance of bilingual LLMs in multilingual summarization tasks.
Similar to the findings in bilingual translation, scaling up the LLM model size had a significant impact on fine-tuning performance. Increasing the model size from 1 billion to 16 billion parameters led to substantial improvements in summarization tasks. This suggests that a larger model capacity allows for better representation of the underlying language patterns and results in more accurate summarization.
The study further delved into zero-shot generalization, which refers to the ability of fine-tuned models to perform well on tasks closely related to the fine-tuning objective without explicit training. The research showcased how fine-tuned models can enhance performance on related tasks, demonstrating the potential of LLMs to optimize models for specific applications and broaden their applicability.


Selecting Optimal Scaling Factors
The insights gained from the research on bilingual translation and summarization tasks offer valuable guidelines for selecting optimal scaling factors during LLM finetuning. Here are some key takeaways:
- Model Size: Increasing the LLM model size has a substantial impact on finetuning performance. Larger models tend to capture more nuanced language patterns and exhibit superior performance in a variety of tasks.
- Pretraining Data: While expanding the pretraining data can improve LLM performance, the study suggests that the impact of pretraining data size is less pronounced compared to the model size. Therefore, allocating resources towards increasing the model size may yield more significant benefits.
- PET Techniques: Parameter-efficient tuning techniques, such as prompt tuning and LoRA, can leverage the pre-existing knowledge encoded within the LLMs effectively. These techniques offer a streamlined approach to finetuning while still achieving impressive performance.
To optimize LLM finetuning, practitioners need to carefully consider the specific requirements of their task and the available resources. The model size, pretraining data size, and the selection of PET techniques should be chosen based on these factors. Experimentation and iterative refinement are crucial in finding the right balance and achieving optimal performance.
Conclusion
Understanding the impact of scaling factors on LLM finetuning is essential for unlocking the full potential of these powerful language models. The insights gained from bilingual translation and summarization tasks shed light on the intricate relationship between scaling factors and LLM performance.
By systematically analyzing the effectiveness of different scaling factors, researchers have provided valuable guidelines for selecting and optimizing fine-tuning methods. This work advances our understanding of the finetuning process and opens up new avenues for making LLMs more adaptable and efficient for diverse NLP applications.
So, the next time you’re working with LLMs, keep in mind the impact of scaling factors and make informed decisions to unleash their true potential.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰
Excellent web site. Plenty of useful information here. I am sending it to a few friends ans also sharing in delicious. And naturally, thanks for your sweat!