Google Demonstrates Method to Scale Language Model to Infinitely Long Inputs
In the ever-evolving landscape of artificial intelligence (AI) and machine learning (ML), the ability to process and comprehend lengthy sequences of text has long been a challenge. Traditional models, including Transformer-based Large Language Models (LLMs), have struggled with efficiently handling infinitely long inputs due to memory and computational constraints. However, recent advancements from Google AI have introduced a groundbreaking method that promises to scale LLMs to handle such inputs with remarkable efficiency and effectiveness.
Explore 3600+ latest AI tools at AI Toolhouse 🚀
Understanding the Challenge
Memory and computation are pivotal aspects of any intelligent system, enabling the retention and application of past information to current tasks. Conventional Transformer models, including LLMs, employ attention mechanisms to manage contextual memory. However, these mechanisms suffer from quadratic complexity in both memory consumption and computation time, posing significant limitations when dealing with lengthy inputs.
Introducing Infini-attention: A Game-Changing Approach
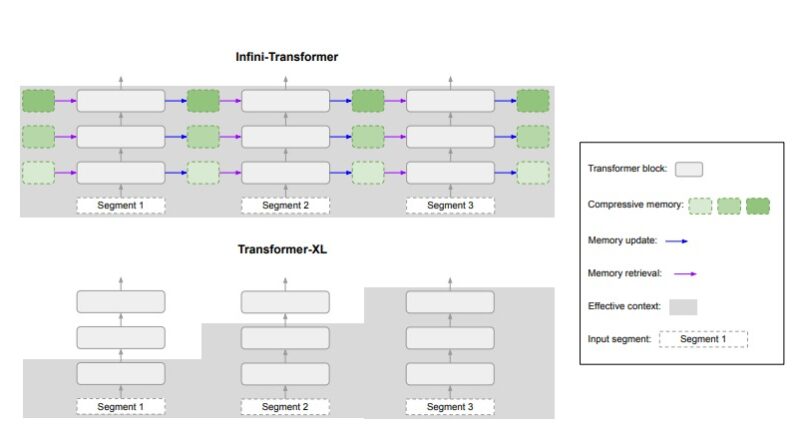
To address these challenges, Google AI researchers have devised a novel solution known as Infini-attention. This approach revolutionizes how LLMs handle memory and computation for infinitely long inputs. At its core, Infini-attention combines long-term linear attention with masked local attention within a single Transformer block, integrating compressive memory into the conventional attention process.
Key Features and Benefits
Infini-attention offers several key features and benefits that set it apart from traditional attention mechanisms:
- Efficient Memory Management: By leveraging compressive memory, Infini-attention maintains a fixed set of parameters for storing and retrieving information, eliminating the need for memory expansion with input sequence length. This results in controlled memory consumption and computational costs.
- Scalability: The proposed method enables LLMs to handle arbitrarily long inputs without compromising performance or requiring excessive computational resources. This scalability is essential for processing extensive textual data in real-world applications.
- Plug-and-Play Integration: Infini-attention seamlessly integrates with existing Transformer structures, requiring minimal modifications to the standard scaled dot-product attention mechanism. This facilitates continuous pre-training, long-context adaptation, and straightforward incorporation into various ML models.
Real-World Applications and Performance
The efficacy of Infini-attention has been demonstrated across various tasks and benchmarks. Google AI researchers have successfully applied this method to tasks such as book summarization, passkey context block retrieval, and long-context language modeling, utilizing LLMs ranging from 1 billion to 8 billion parameters. Notably, the model excelled in handling input sequences of up to 1 million tokens in length.
Conclusion
Infini-attention represents a paradigm shift in the field of language modeling, offering a solution to the longstanding challenge of handling infinitely long inputs. With its efficient memory management, scalability, and seamless integration capabilities, this method paves the way for enhanced performance and usability of Transformer-based LLMs in diverse domains. As AI continues to advance, innovations like Infini-attention play a crucial role in unlocking the full potential of machine learning models for natural language understanding and generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰