Layerwise Importance Sampled AdamW (LISA): A Machine Learning Optimization Algorithm that Randomly Freezes Layers of LLM Based on a Given Probability
In the field of machine learning, fine-tuning large language models (LLMs) has become a common practice to improve their performance on specific tasks. However, fine-tuning LLMs can be computationally expensive and memory-intensive. To address this challenge, researchers have developed various parameter-efficient fine-tuning (PEFT) methods. One such method is Layerwise Importance Sampled AdamW (LISA), which introduces a novel optimization algorithm that randomly freezes layers of LLM based on a given probability. In this article, we will explore LISA and its advantages over other PEFT techniques.
The Need for Parameter-Efficient Fine-Tuning
LLMs, such as OpenAI’s GPT-3, have demonstrated remarkable capabilities in natural language processing tasks. These models are typically pre-trained on a large corpus of text data and then fine-tuned for specific downstream applications. Fine-tuning allows the model to adapt to the nuances and requirements of the target task.
Explore 3600+ latest AI tools at AI Toolhouse 🚀
However, fine-tuning LLMs can be resource-intensive. These models have billions of parameters, requiring substantial computational power and memory to train effectively. This poses challenges for researchers and organizations that want to leverage LLMs but have limited resources. Parameter-efficient fine-tuning methods aim to address this issue by reducing the computational and memory requirements while maintaining or improving performance.
The Limitations of Existing Parameter-Efficient Fine-Tuning Techniques
Several PEFT techniques have been proposed to minimize the number of trainable parameters and lower the cost of fine-tuning LLMs. These techniques include adapter weights, prompt weights, and LoRA (Layerwise Relevance Adaptive Fine-Tuning). While these methods have shown promise, they still have limitations that hinder their effectiveness.
LoRA, for example, allows the adapter to be merged back to the base model parameters. However, it has been observed that LoRA’s efficacy on large-scale datasets is limited. Continuous pre-training with LoRA often fails due to its reduced representational capacity compared to full-parameter fine-tuning. This limitation motivated researchers to investigate the training statistics of LoRA in each layer to bridge the gap between LoRA and full-parameter fine-tuning.
Introducing Layerwise Importance Sampled AdamW (LISA)
Researchers from the Hong Kong University of Science and Technology and the University of Illinois proposed a novel approach to address the limitations of LoRA. They discovered that LoRA’s layerwise weight norms are skewed, with most of the weights assigned to the bottom or top layer during updates. This observation suggested that different layers have varying importance in the fine-tuning process.
Motivated by the concept of importance sampling, the researchers introduced Layerwise Importance Sampled AdamW (LISA). LISA is an optimization algorithm that randomly freezes layers of LLM based on a given probability. By selectively updating only the essential LLM layers, LISA allows for the training of large-scale language models with the same or less memory consumption as LoRA.
Advantages of LISA over Other PEFT Techniques
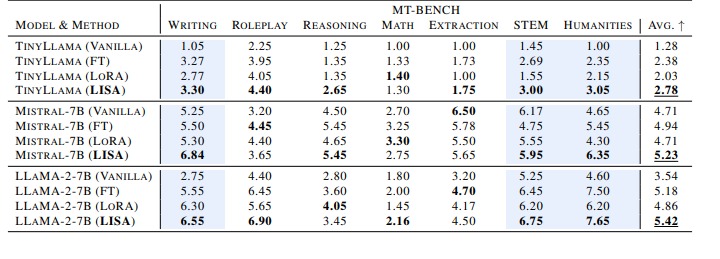
LISA has demonstrated superior performance compared to both LoRA and traditional full-parameter fine-tuning methods. In experiments on downstream tasks, LISA outperformed LoRA by 8–36% on MT-Bench, a benchmark dataset for machine translation. This significant performance gap highlights LISA’s potential as a promising alternative to LoRA for large-scale language model training.
Furthermore, LISA’s performance is not limited to specific tasks or model sizes. It consistently delivers improved results across various activities, including instruction following, medical QA, and math problems, for models ranging from 7 billion to 70 billion parameters in size. This versatility makes LISA a compelling choice for fine-tuning tasks using current LLMs.
Limitations of LISA and Future Research
Despite its advantages, LISA shares a common drawback with LoRA – memory consumption during the optimization forward pass. The model still needs to be stored in memory, which can be a limiting factor for resource-constrained environments. However, the researchers behind LISA aim to address this limitation through future trials and the exploration of other techniques like QLoRA (Quantization-based LoRA).
Conclusion
The development of Layerwise Importance Sampled AdamW (LISA) has paved the way for more efficient and cost-effective fine-tuning of large language models. By randomly freezing layers of LLM based on a given probability, LISA reduces memory consumption while maintaining or improving performance compared to other PEFT techniques like LoRA. LISA’s versatility and superior performance make it a promising alternative for fine-tuning tasks using current LLMs. As further research and advancements are made, LISA and similar approaches will continue to contribute to the advancement of machine learning optimization algorithms.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰