How Faithful are RAG Models? Evaluating the Impact of Data Accuracy on RAG Systems in Large Language Models (LLMs)
Retrieval-Augmented Generation (RAG) is an innovative technology that integrates externally retrieved information with pre-existing model knowledge to enhance the accuracy and relevance of large language models (LLMs). As LLMs continue to advance, it is crucial to evaluate the faithfulness of RAG models and understand the impact of data accuracy on RAG systems. In this article, we will explore a recent AI paper from Stanford that delves into the evaluation of RAG models and their performance in LLMs.
The Role of RAG Models in Addressing Limitations of LLMs
Large language models such as GPT-3 have impressive generative capabilities, but they are limited by their training datasets. These models primarily rely on pre-existing knowledge and may not have access to real-time or nuanced information. This limitation poses a challenge in dynamic digital interactions where accurate and up-to-date information is crucial.
Explore 3600+ latest AI tools at AI Toolhouse 🚀
RAG models aim to address this limitation by integrating real-time data retrieval into generative models. By combining external information with the model’s internal knowledge, RAG systems can provide more accurate and relevant responses. This retrieval-augmented approach enhances the factual accuracy of the model’s responses and allows it to handle queries about recent or nuanced information.
Evaluating the Faithfulness of RAG Models
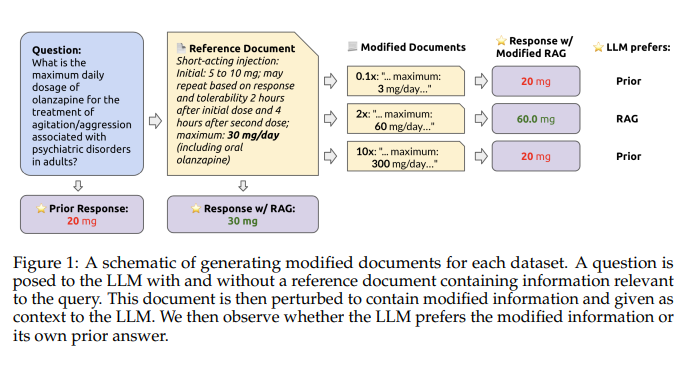
The AI paper from Stanford focuses on evaluating the faithfulness of RAG models, specifically GPT-4, and understanding how these models integrate and prioritize external information retrieved through RAG systems. The research methodology involves simulating real-world inaccuracies by perturbing external documents. This analysis provides insights into the adaptability of RAG models and their performance in practical applications where data reliability varies.
To evaluate the faithfulness of RAG models, the researchers posed various questions to GPT-4, both with and without perturbed external documents as context. The datasets used in the evaluation include domains such as drug dosages, sports statistics, and current news events. By manipulating the datasets to include variations in data accuracy, the researchers assessed the model’s ability to discern and prioritize information based on its fidelity to known facts.
The research employed both “strict” and “loose” prompting strategies to understand how different types of RAG deployment impact the model’s reliance on pre-trained knowledge versus altered external information. This analysis sheds light on the strengths and limitations of current RAG implementations and provides valuable insights for further enhancements.
The Impact of Data Accuracy on RAG Systems
The study found that the accuracy of external data has a significant impact on the effectiveness of RAG systems. When provided with correct information, GPT-4 demonstrated the ability to correct initial errors in 94% of cases, leading to improved response accuracy. However, when external documents were perturbed with inaccuracies, the model’s reliance on flawed data increased, especially in scenarios where its internal knowledge was less robust.
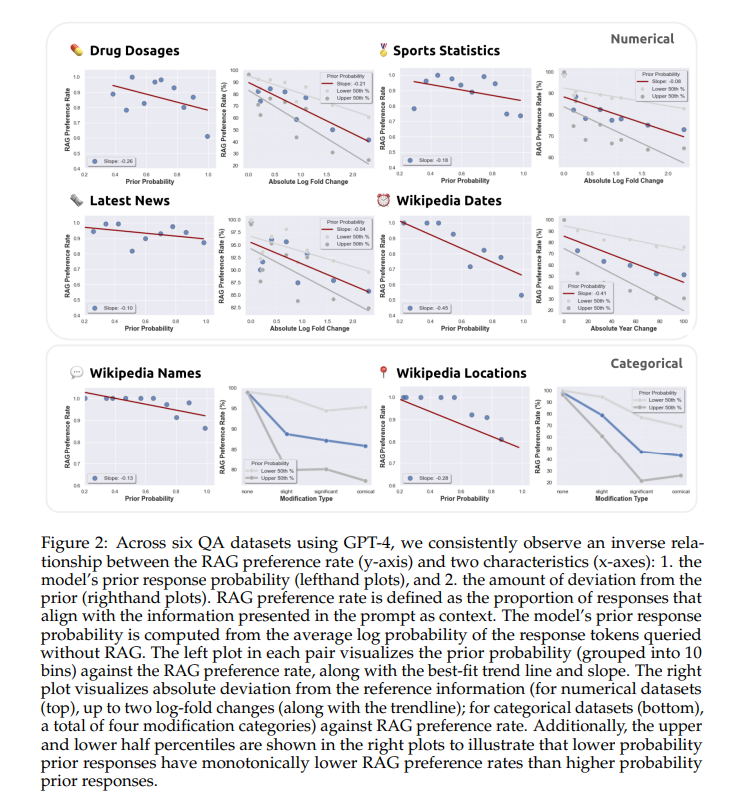


As the perturbation level increased, the model’s preference for external information over its internal knowledge decreased noticeably. This decline had a direct correlation with a decrease in correct response adherence, with accuracy declining by up to 35%. These findings highlight the importance of data accuracy in maintaining the effectiveness of RAG systems and emphasize the need for robust models that can discriminate and integrate external data more effectively.
Enhancing RAG System Designs for Improved Performance
The evaluation of RAG models and their performance in LLMs provides crucial insights for further advancements in design. To ensure more reliable and robust model performance across real-world applications, RAG systems need to be equipped with the ability to integrate and prioritize external data accurately. This integration must happen seamlessly, without compromising the reliability of the output.
Future research and development efforts should focus on enhancing RAG system designs, allowing them to better discriminate between reliable and inaccurate external information. This improvement will enable the models to make more informed decisions about the importance and fidelity of the retrieved data. By effectively managing the interplay between internal knowledge and external data, RAG models can enhance the faithfulness and accuracy of their responses in practical applications.
The Stanford research serves as a foundation for further exploration of RAG models and their impact on LLMs. It highlights the current challenges and offers valuable insights into the balance that must be struck between internally stored knowledge and externally retrieved information. By addressing these challenges and improving the fidelity of RAG systems, we can unlock the full potential of large language models in delivering accurate and reliable responses to dynamic digital interactions.
In conclusion, RAG models hold great promise in enhancing the accuracy and relevance of large language models. The AI paper from Stanford offers a thorough evaluation of RAG models and sheds light on the impact of data accuracy on RAG systems. By understanding these factors, researchers and developers can focus on creating more robust and effective RAG systems that deliver reliable responses across various real-world applications.
Remember to check out the original paper for more detailed insights. The credit for this research goes to the Stanford researchers who conducted this study. Stay updated on the latest AI research by following us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group as well.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on LLMs 😁
If you like our work, you will love our Newsletter 📰