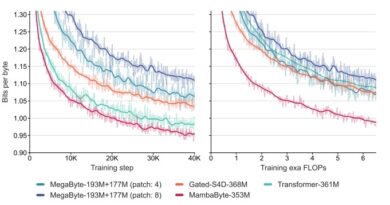
FastGen: Cutting GPU Memory Costs Without Compromising on LLM Quality
Autoregressive language models (ALMs) have revolutionized various natural language processing tasks, such as machine translation, text generation, and more. These models, however, come with their own set of challenges, including computational complexity and GPU memory usage. As the size and complexity of language models increase, managing GPU memory becomes crucial to ensure efficient and cost-effective inference.
One specific area of concern in large language models (LLMs) is the memory usage of the Key-Value (KV) cache mechanism used for generative inference. The KV cache enhances generation speed by storing contextual information. However, as the model size and generation length increase, so does the memory footprint of the KV cache. When the memory usage exceeds GPU capacity, the generative inference of LLMs suffers, often resulting in offloading or degraded performance.
To address these challenges, researchers from the University of Illinois Urbana-Champaign and Microsoft have proposed a highly effective technique called FastGen. FastGen aims to enhance the inference efficiency of LLMs without compromising on visible quality. It achieves this through lightweight model profiling and adaptive key-value caching.
The core idea behind FastGen is to evict long-range contexts on attention heads by constructing the KV cache in an adaptive manner. This adaptive approach ensures that only the most relevant information is stored in the cache, reducing the overall memory requirements. FastGen leverages lightweight attention profiling to guide the construction of the adaptive KV cache without the need for resource-intensive fine-tuning or re-training.
By implementing FastGen, GPU memory usage can be significantly reduced without sacrificing the quality of generated outputs. The adaptive KV cache compression technique plays a crucial role in achieving this goal. It effectively reduces the memory footprint of generative inference for LLMs, leading to more efficient GPU utilization.

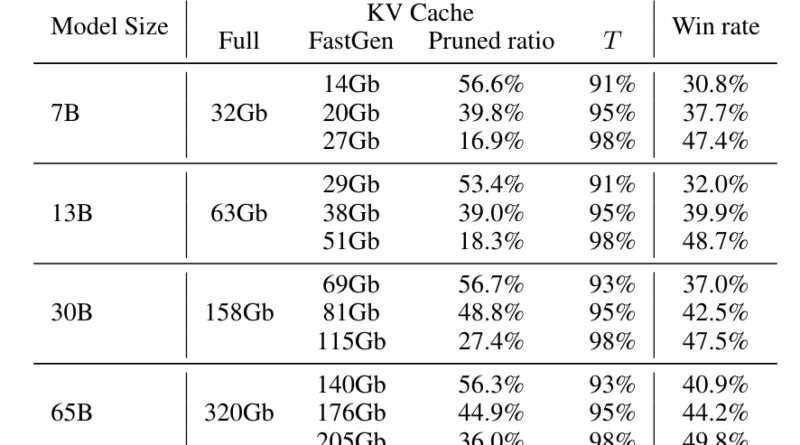
In practice, FastGen outperforms other non-adaptive KV compression methods, especially for large models. For example, on the Llama 1-65B model, FastGen achieves a remarkable 44.9% pruned ratio compared to a 16.9% pruned ratio on the Llama 1-7B model. This 45% win rate demonstrates the effectiveness of FastGen in reducing memory usage while maintaining generation quality.
Additionally, FastGen has undergone sensitivity analysis by experimenting with different hyper-parameters. The results show that even with variations in hyper-parameters, the model consistently maintains a win rate of 45%. This indicates that FastGen has minimal visible impact on generation quality, making it a reliable technique for LLMs.
The impact of FastGen extends beyond memory reduction. It also opens up possibilities for integrating with other model compression approaches, such as quantization and distillation, as well as grouped-query attention. These future directions hold the potential to further optimize LLMs’ memory usage and inference efficiency.
In conclusion, FastGen is a cutting-edge technique developed by researchers from the University of Illinois Urbana-Champaign and Microsoft to enhance the inference efficiency of large language models. By leveraging lightweight model profiling and adaptive key-value caching, FastGen successfully reduces GPU memory costs without compromising on the quality of generated outputs. This technique, combined with adaptive KV cache compression, significantly reduces the memory footprint of generative inference. FastGen’s effectiveness in maintaining generation quality while optimizing resource utilization makes it a valuable advancement in the field of autoregressive language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰