Cornell Researchers Unveil MambaByte: A Game-Changing Language Model Outperforming MegaByte
Language models have played a vital role in natural language processing, allowing machines to understand and generate human-like text. These models have evolved over time, with researchers continuously striving to improve their efficiency and performance. One such groundbreaking development is the MambaByte language model, developed by Cornell University researchers, which has outperformed the MegaByte model in various aspects. In this article, we will explore the capabilities of MambaByte and its impact on the field of language modeling.
The Challenge of Managing Lengthy Data Sequences
Traditional language models, especially those operating at the byte level, have faced challenges in efficiently processing lengthy data sequences. These models often rely on subword or character-level tokenization, breaking down text into smaller fragments. While this approach has been useful, it also has limitations, particularly in handling extensive sequences and linguistic complexities.
Introducing MambaByte: A Revolution in Language Modeling
MambaByte is a byte-level language model developed by Cornell University researchers. It is built upon the Mamba architecture, a state space model specifically designed for sequence modeling. Unlike traditional models, MambaByte operates directly on byte sequences, eliminating the need for tokenization.
The key advantage of MambaByte lies in its ability to effectively manage lengthy byte sequences. Leveraging the linear-time capabilities of the Mamba architecture, this innovative approach significantly reduces computational demands compared to conventional models. This enhanced efficiency makes MambaByte a practical choice for extensive language modeling tasks.
Unparalleled Performance: MambaByte vs. MegaByte
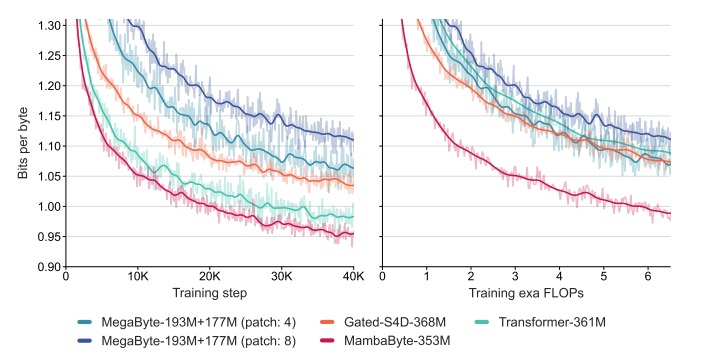
MambaByte has demonstrated exceptional performance compared to the MegaByte model across various datasets. Despite not being trained for the full 80B bytes due to monetary constraints, MambaByte outperformed MegaByte with 0.63× less compute and training data 1. This remarkable achievement highlights MambaByte’s superior efficiency and its ability to achieve better results with fewer computational resources and training data.
Furthermore, MambaByte-353M surpasses byte-level Transformer and PerceiverAR models, further cementing its position as a game-changing language model 1. MambaByte’s performance superiority opens up new possibilities for more efficient and powerful natural language processing tools.
The Future of Token-Free Language Modeling
MambaByte’s success in processing long-byte sequences without relying on tokenization marks a significant breakthrough in language modeling. Traditional tokenization techniques often struggle with linguistic and morphological complexities, limiting their flexibility. MambaByte’s token-free approach paves the way for more adaptable language models that can handle a wide range of linguistic structures.
The implications of MambaByte extend beyond just improved performance. With its ability to process byte sequences directly, MambaByte opens up new avenues for large-scale applications. By reducing computational demands, MambaByte makes language modeling more accessible for a wide range of use cases.
Conclusion
The unveiling of MambaByte by Cornell University researchers has introduced a game-changing language model that outperforms the MegaByte model. By operating directly on byte sequences and eliminating the need for tokenization, MambaByte offers superior efficiency and performance. Its ability to handle lengthy data sequences more effectively, with fewer computational resources, marks a significant advancement in language modeling.
MambaByte’s success showcases the potential of token-free language modeling and its impact on various applications, from translation to conversational interfaces. As researchers continue to refine and expand upon this groundbreaking model, we can expect further advancements in natural language processing tools and techniques.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰

Thanks for sharing. I read many of your blog posts, cool, your blog is very good.