Introducing Arena-Hard: A Dynamic and User-Centric Benchmark for Language Models
The world of large language models (LLMs) presents a significant challenge when it comes to accurately measuring and comparing the capabilities of different chatbot models.
Developers and researchers require a benchmark that can provide an accurate reflection of real-world usage, differentiate between models, and incorporate new data in a regular and unbiased manner.
Traditional benchmarks for LLMs, such as multiple-choice question-answering systems, have been static and fail to capture real-world application nuances.
These benchmarks do not update frequently and may not effectively demonstrate the differences between closely performing models.
This limitation hinders developers aiming to improve their systems and push the boundaries of language understanding and generation.
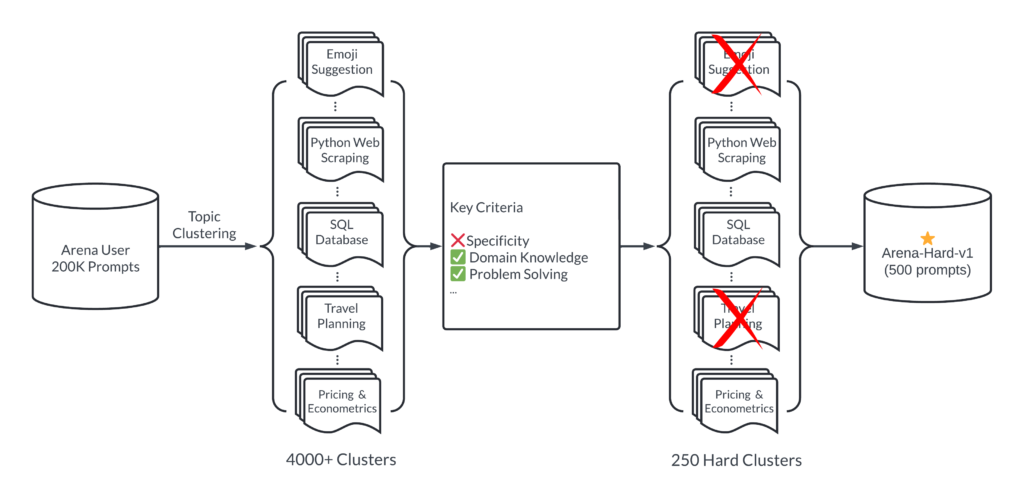
To address these limitations, LMSys Org has introduced Arena-Hard, a data pipeline that builds high-quality benchmarks from live data in the Chatbot Arena.
The Chatbot Arena is a crowd-sourced platform developed by LMSys Org for LLM evaluations.
The Need for Dynamic and Relevant Benchmarks
Static benchmarks lack the ability to adapt and evolve over time, resulting in outdated evaluations that are not representative of real-world scenarios.
Furthermore, these benchmarks may not fully capture the complexities of natural language understanding and generation, limiting their usefulness for developers.
Arena-Hard tackles these challenges by leveraging live data collected from the Chatbot Arena platform, where users continuously evaluate large language models.
This approach ensures that the benchmarks are always up-to-date and rooted in real user interactions, providing a more dynamic and relevant evaluation tool.
The use of live data brings several advantages to the benchmarking process. It allows for the inclusion of the latest user interactions, covering a wide range of topics and nuances.
It also ensures that the benchmark remains unbiased by incorporating a diverse set of user preferences. With this approach, Arena-Hard provides developers with a more accurate and reliable evaluation tool for their language models.
Measuring the Effectiveness of Arena-Hard
The effectiveness of Arena-Hard is measured by two primary metrics:
- Its ability to agree with human preferences and
- Its capacity to separate different models based on their performance.
Compared to existing benchmarks, Arena-Hard has shown significantly better performance in both metrics.
By incorporating live user data, Arena-Hard aligns with human preferences at a high agreement rate.
This means that the benchmark reflects what users consider to be good or high-quality responses, ultimately providing a more user-centric evaluation.
Additionally, Arena-Hard demonstrates its capability to distinguish between top-performing models by providing precise, non-overlapping confidence intervals for a notable percentage of model comparisons.
This ability to separate models effectively allows developers to identify subtle differences in model performance, enabling them to refine their language models and deliver enhanced user experiences.
Advantages of Arena-Hard for Language Model Developers
The introduction of Arena-Hard brings several advantages to language model developers:
1. Accuracy and Reliability:
By incorporating live data from real user interactions, Arena-Hard provides benchmarks that accurately reflect real-world usage.
This enables developers to evaluate the performance of their language models in scenarios that closely resemble actual user applications.
2. Relevance and Freshness:
The use of live data ensures that the benchmarks are always up-to-date.
Language models built and evaluated using Arena-Hard can adapt to evolving user needs and changing language usage patterns.
3. Nuanced Evaluation:
Traditional static benchmarks may not effectively differentiate between closely performing models.
Arena-Hard addresses this limitation by providing precise confidence intervals and clear separability of model capabilities.
This enables developers to make informed decisions about the strengths and weaknesses of their models and focus on areas that require improvement.
4. User-Centric Evaluation:
With its high agreement rate with human preferences, Arena-Hard provides a user-centric evaluation of language models.
Developers can assess their models’ ability to respond to user queries and understand user intent accurately.
5. Open and Crowdsourced Platform:
The Chatbot Arena, the platform from which Arena-Hard derives its live data, is open and crowdsourced.
This facilitates collaboration and knowledge sharing among researchers and developers, benefiting the entire language model community.
Conclusion
Arena-Hard represents a significant advancement in benchmarking language model chatbots.
By leveraging live user data and focusing on metrics that reflect both human preferences and clear separability of model capabilities, this new benchmark provides a more accurate, reliable, and relevant tool for developers.
With Arena-Hard, language model developers can evaluate and improve their models with confidence, ensuring they are equipped to deliver enhanced user experiences across various applications.
The combination of accuracy, relevance, and user-centric evaluation offered by Arena-Hard establishes it as an invaluable resource in the field of large language models.
Through the continuous refining and evolution of benchmarks like Arena-Hard, the language model community can drive innovation and push the boundaries of natural language understanding and generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰