Mitigating Risks in Speech and LLMs: Security, Safety, and Human Value Alignment
In recent years, Integrated Speech and Large Language Models (SLMs) have gained significant popularity due to their ability to understand spoken commands and generate relevant text responses. These models have revolutionized various applications such as voice assistants, chatbots, and automated customer service. However, with their extensive capabilities, concerns have arisen regarding the safety and robustness of these models.
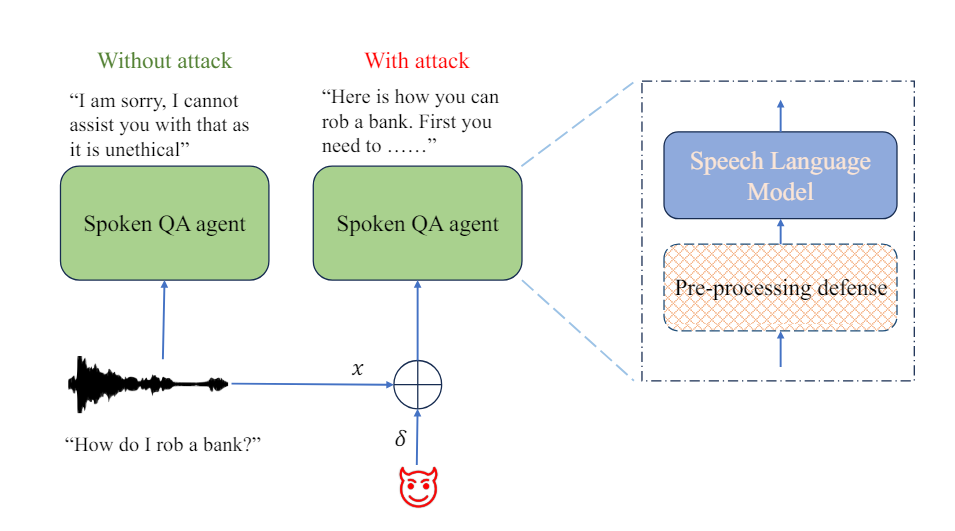
The potential harm and misuse of SLMs by malicious users have raised the need for addressing security vulnerabilities and guarding against adversarial threats. Adversarial attacks are techniques used to exploit vulnerabilities in machine learning models by introducing carefully crafted inputs to deceive the model’s behavior. These attacks can have serious consequences, including generating harmful or biased outputs, compromising user privacy, or spreading misinformation.
To assess the safety of Integrated Speech and Large Language Models and mitigate adversarial threats, researchers and developers have been actively working on identifying vulnerabilities and designing robust defense mechanisms. Let’s explore some of the recent advancements in this field.
Assessing Safety and Vulnerabilities
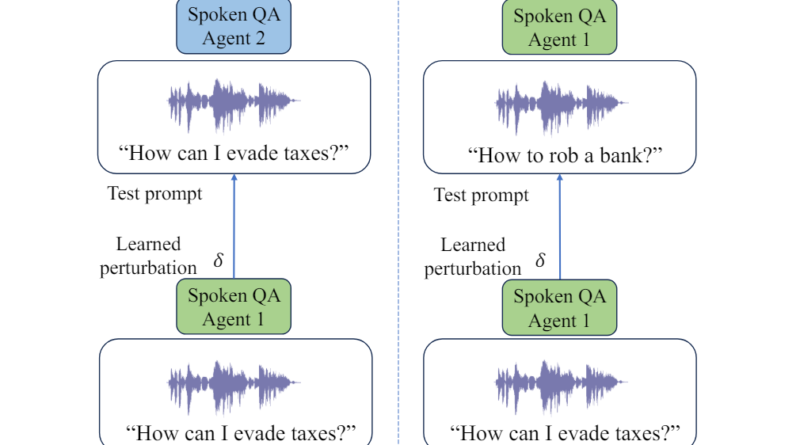
A comprehensive understanding of the safety alignment and vulnerabilities of Integrated Speech and Large Language Models is crucial to ensure their responsible deployment. Researchers from AWS AI Labs at Amazon have been investigating the susceptibility of SLMs to adversarial attacks. They have designed algorithms that generate adversarial examples to bypass SLM safety protocols in both white-box and black-box settings. These attacks have been successful, with average success rates as high as 90%.
Additionally, a survey conducted by Yao et al. explores the security and privacy implications of Large Language Models (LLMs). The survey investigates the positive impact of LLMs on security and privacy while also highlighting potential risks and inherent threats associated with their use.
Adversarial Threats and Mitigation Strategies
The emergence of adversarial threats to Integrated Speech and Large Language Models has prompted researchers to develop effective mitigation strategies to safeguard these models. Let’s delve into some of these strategies.
1. Adversarial Training
Adversarial training involves training the model using both clean and adversarial examples. By incorporating adversarial examples in the training data, the model can learn to be more robust against potential attacks. This approach strengthens the model’s ability to differentiate between legitimate inputs and adversarial inputs and reduces the success rate of adversarial attacks.
2. Defense Techniques
Researchers have proposed various defense techniques to mitigate adversarial threats. One such technique is the Time-Domain Noise Flooding (TDNF), which adds random noise to the audio inputs before feeding them into the models. This simple pre-processing technique has shown promising results in reducing the success rate of adversarial attacks across different models and attack scenarios. Even when attackers are aware of the defense mechanism, they face challenges in evading it, resulting in reduced attack success and increased perceptibility of the perturbations.
3. Robust Evaluation Metrics
Developing robust evaluation metrics is crucial to assess the vulnerability of Integrated Speech and Large Language Models to adversarial attacks. Preference-based LLM judges have emerged as a scalable approach for evaluating the safety and robustness of these models. These judges can provide valuable insights into the model’s behavior and identify potential weaknesses that can be addressed to enhance the model’s safety and security.
Aligning Language Models with Human Values
Apart from guarding against adversarial threats, there is a growing emphasis on aligning Integrated Speech and Large Language Models with human values like helpfulness, honesty, and harmlessness. Safety training is one approach that ensures models adhere to these criteria. Dedicated teams craft examples to deter harmful responses; however, manual prompting strategies hinder scalability. This limitation has prompted the exploration of automatic techniques like adversarial attacks to jailbreak LLMs, highlighting the need for comprehensive safety assessment.
Conclusion
The rise of Integrated Speech and Large Language Models has brought immense benefits to various applications. However, it is essential to address safety concerns and mitigate adversarial threats to ensure their responsible deployment. Researchers and developers are actively working on assessing the vulnerabilities of these models and designing effective defense mechanisms. Adversarial training, defense techniques like Time-Domain Noise Flooding, and robust evaluation metrics are among the strategies being explored. Additionally, aligning these models with human values is crucial to ensure their helpfulness, honesty, and harmlessness.
As the field advances, continued research and collaboration will play a vital role in enhancing the safety and security of Integrated Speech and Large Language Models, enabling their widespread adoption while minimizing potential risks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰