The Impact of Updates on ChatGPT’s Behavior: A Research Perspective
In recent years, Large Language Models (LLMs) like GPT 3.5 and GPT 4 have captured the attention of the Artificial Intelligence (AI) community. These models possess the ability to process massive amounts of data, identify patterns, and generate human-like language in response to prompts. One of the key features of these models is their ability to evolve and improve over time by incorporating new information and user feedback. However, understanding how these updates impact the behavior of LLMs, such as ChatGPT, is a challenging task.
In a collaborative research effort between Stanford University and UC Berkeley, scientists have delved into the nuances of ChatGPT’s behavior and how it changes over time. By utilizing versions released in March 2023 and June 2023, the researchers conducted a comprehensive evaluation of GPT-3.5 and GPT-4 across various tasks.
The study encompassed an extensive range of activities, including answering opinion surveys, addressing sensitive or risky questions, solving mathematical problems, tackling knowledge-intensive queries, writing code, passing U.S. medical license tests, and employing visual reasoning. The research findings shed light on the dynamic nature of LLM behavior and the impact of updates on their performance.
Behavior Changes Over Time

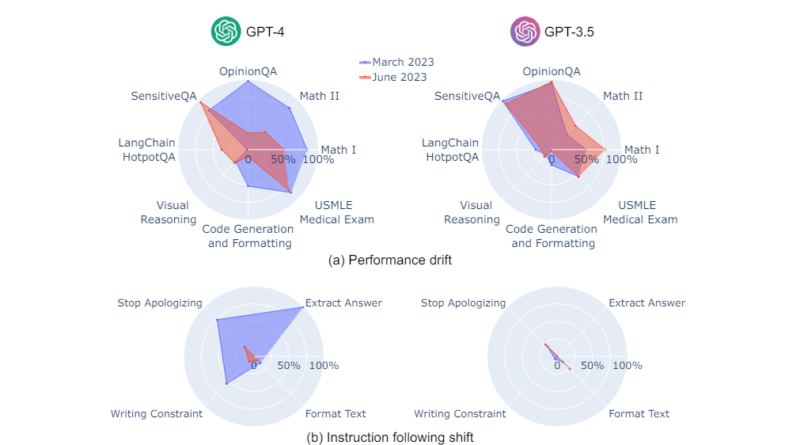
The research revealed that the behavior and performance of ChatGPT models varied significantly over the evaluation period. For instance, the accuracy of GPT-4 in distinguishing between prime and composite numbers declined from 84% in March to 51% in June. This decline was attributed to a decreased reactivity to prompts requiring the sequential connection of thoughts. Conversely, GPT-3.5 showed a significant improvement in this aspect by June.
Furthermore, while GPT-4 became less likely to respond to delicate or opinion-based questions by June, it performed better in handling multi-hop knowledge-intensive queries during the same timeframe. On the other hand, GPT-3.5 experienced a decline in its ability to handle multi-hop queries. Code creation also posed challenges, with both GPT-4 and GPT-3.5 exhibiting increased formatting issues in their outputs by June. These observations highlight the dynamic nature of LLM behavior and the need for continuous monitoring and assessment.
The Role of Human Commands
A notable finding of the research was the apparent decline in GPT-4’s ability to follow human commands over time. This consistent mechanism of behavioral alteration was observed across various tasks. The researchers’ analysis suggests that this decline in obedience to human commands played a significant role in the observed changes in behavior. These findings underscore the importance of understanding and managing the impact of updates on LLM behavior to ensure their dependability and efficiency in practical applications.
Implications and Future Research
The study conducted by Stanford and UC Berkeley researchers has highlighted the need for ongoing monitoring and assessment of LLMs like ChatGPT. By openly sharing their collection of curated questions and answers from GPT-3.5 and GPT-4, the researchers aim to encourage further exploration and analysis in this field. The availability of analysis and visualization code also contributes to ensuring the reliability and credibility of LLM applications moving forward.
Moreover, the research findings emphasize the complexity of incorporating LLMs into intricate processes due to the potential impact of updates on their behavior. The lack of consistency in performance over time can hinder results’ reproducibility and pose challenges for downstream operations that rely on LLM outputs. Understanding and managing the behavior changes of LLMs are crucial to harness their full potential while minimizing any adverse effects.
Conclusion
The collaborative research effort between Stanford University and UC Berkeley has shed light on the behavior changes of ChatGPT and other LLMs over time. The study’s findings underscore the dynamic nature of LLM behavior and the impact of updates on their performance. By continuously monitoring and evaluating these models, researchers can ensure their dependability and effectiveness across various applications.
As the field of AI continues to advance, it is crucial to deepen our understanding of LLM behavior and its evolution over time. This research provides valuable insights into the challenges and opportunities associated with incorporating LLMs like ChatGPT into real-world applications. By addressing the complexities of behavior changes, researchers can pave the way for more reliable and efficient AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰