LLaVA-Phi: The Next Generation Vision Language Assistant Powered by Phi-2
In recent years, the field of artificial intelligence has witnessed significant advancements in language models and their application to various tasks. One such remarkable development is the introduction of LLaVA-Phi, a vision language assistant developed using the compact language model Phi-2. This innovative research, conducted by Midea Group and East China Normal University, combines the power of Phi-2 with a multimodal model to create a high-performing vision language assistant. In this article, we will explore the capabilities of LLaVA-Phi and its potential impact on the AI landscape.
The Rise of Language Models in AI
Language models have become a cornerstone in natural language processing and understanding. They are designed to generate coherent and contextually relevant text based on a given input prompt. These models have shown remarkable progress in various language-related tasks, such as text generation, translation, and sentiment analysis.
Large language models like GPT-4V and Gemini have gained attention for their ability to execute instructions, engage in multi-turn conversations, and answer image-based questions [1]. However, the development of open-source vision language models, such as LLaMA and Vicuna, has further accelerated progress in the field, particularly in improving visual understanding by integrating language models with vision encoders.
Introducing LLaVA-Phi: A Vision Language Assistant
LLaVA-Phi is a groundbreaking research project that combines the power of the Phi-2 language model with the LLaVA-1.5 multimodal model to create a vision language assistant. The researchers utilized LLaVA’s high-quality visual instruction tuning data in a two-stage training pipeline to train LLaVA-Phi.
One of the notable aspects of LLaVA-Phi is its compact size. Despite having only three billion parameters, it performs on par with or even better than larger multimodal models that have several times more parameters [1]. The combination of Phi-2 and LLaVA-1.5 has proven to be highly effective in answering questions based on visual cues.
Evaluation and Performance
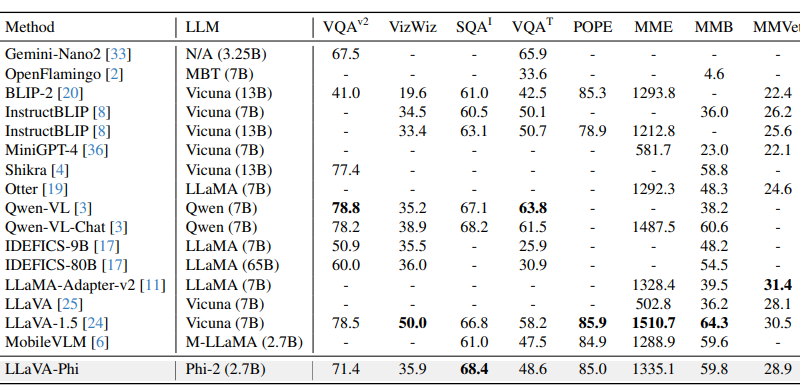
To thoroughly evaluate the capabilities of LLaVA-Phi, the research team employed a wide range of academic standards developed for multimodal models. These included tests like VQA-v2, VizWizQA, ScienceQA, and TextQA for general question-answering, as well as specialized assessments like POPE for object hallucination and MME, MMBench, and MMVet for comprehensive evaluations of multimodal abilities.
Remarkably, LLaVA-Phi outperformed larger multimodal models, including those relying on 7B-parameter or greater language models like IDEFICS [1]. The model’s performance on ScienceQA, specifically in answering math-based questions, was exceptional, thanks to the training on mathematical corpora and code production [1]. In the extensive multimodal benchmark of MMBench, LLaVA-Phi surpassed numerous prior art vision-language models based on 7B-language models.

The Potential Impact of LLaVA-Phi
LLaVA-Phi’s compact size and impressive performance hold great promise for a wide range of applications. One notable area is autonomous driving, where real-time interaction and faster inference speeds are crucial. The ability of LLaVA-Phi to effectively process visual cues and provide accurate answers makes it a valuable asset in enhancing the safety and efficiency of autonomous vehicles.
Robotics is another field where LLaVA-Phi can make a significant impact. With its multimodal capabilities and efficient language model, LLaVA-Phi can assist robots in understanding and responding to human instructions. This opens up new possibilities for collaborative and interactive robotic systems, leading to advancements in areas like industrial automation and healthcare.
Additionally, LLaVA-Phi’s compact size makes it suitable for mobile devices, allowing users to have a vision language assistant readily available on their smartphones or tablets. This accessibility further extends the potential reach and impact of LLaVA-Phi in various domains.
Future Improvements and Research Directions
The researchers behind LLaVA-Phi acknowledge that there is room for further improvements. While the model’s performance is impressive, it has not been fine-tuned to process multilingual instructions. The current architecture of LLaVA-Phi using the codegenmono tokenizer limits its ability to handle languages other than English. The research team aims to address this limitation in future iterations of the model by improving training procedures for small language models and exploring the impact of visual encoder size [1].
In conclusion, LLaVA-Phi represents a significant step forward in the development of vision language assistants. Powered by the compact language model Phi-2 and the LLaVA-1.5 multimodal model, it showcases impressive performance while maintaining a smaller parameter size. With its potential applications in autonomous driving, robotics, and mobile devices, LLaVA-Phi paves the way for more efficient and interactive AI systems. The ongoing research and improvements in small language models and visual encoders will undoubtedly shape the future of vision language assistants, bringing us closer to seamless human-machine interactions.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Pingback: Phi-3 Compact LM Microsoft’s New Release – AI Toolhouse Blog