Meet VLM-CaR: A New Machine Learning Framework Empowering Reinforcement Learning with Vision-Language Models
Reinforcement learning (RL) has emerged as a powerful technique for training intelligent agents to perform complex tasks. RL agents learn by interacting with their environment, receiving rewards for desired behaviors and punishments for undesired ones. However, designing effective reward functions that accurately capture the desired behavior can be challenging and time-consuming. To address this challenge, researchers from Google DeepMind, Mila, and McGill University have proposed a new machine learning framework called VLM-CaR (Code as Reward).
The Challenge of Reward Function Design
Reward functions play a crucial role in reinforcement learning, as they define the goals and objectives that the RL agent should strive to achieve. Traditionally, designing reward functions has been a manual and labor-intensive process that often requires domain expertise. Environment designers have to carefully define the rewards based on their understanding of the task, which can be subjective and prone to biases.
Moreover, in complex tasks where the desired behaviors are not easily quantifiable or explicitly defined, manually defining reward functions becomes even more challenging. In such cases, the lack of clear reward signals can lead to slow and inefficient learning, or even failure to learn at all.
Leveraging Vision-Language Models (VLMs)
To automate the process of generating reward functions, the researchers proposed leveraging Vision-Language Models (VLMs). VLMs are deep learning models that combine visual perception and natural language understanding, enabling them to process both visual inputs and textual descriptions.
By utilizing VLMs, the researchers aimed to generate dense reward functions automatically, without the need for manual intervention. This approach eliminates the labor-intensive process of defining reward functions and allows RL agents to learn directly from visual inputs.
Introducing VLM-CaR (Code as Reward) Framework
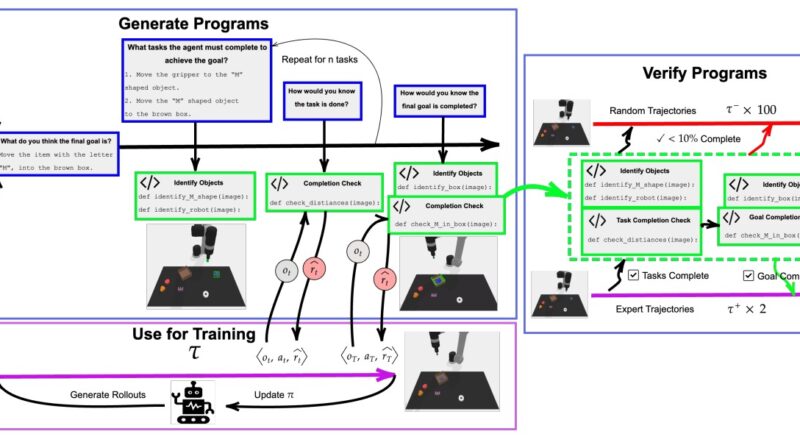
The VLM-CaR framework introduces a novel approach to reward function generation by utilizing pre-trained VLMs. Unlike direct querying of VLMs for rewards, which can be computationally expensive and unreliable, VLM-CaR generates reward functions through code generation. This significantly reduces the computational burden and ensures accurate and interpretable rewards for RL agents.
VLM-CaR operates in three stages: generating programs, verifying programs, and RL training. In the first stage, pre-trained VLMs are prompted to describe tasks and sub-tasks based on initial and goal images of an environment. These descriptions are then used to produce executable computer programs for each sub-task.
To ensure the correctness of the generated programs, a verification step is performed. Expert and random trajectories are used to verify the programs, ensuring that they correctly capture the desired behavior. Once the programs are verified, they act as reward functions for training RL agents.
Using the generated reward function, VLM-CaR is trained for RL policies. This empowers RL agents to learn efficiently even in environments with sparse or unavailable rewards. The use of VLMs allows RL agents to generalize their learning from visual inputs and natural language descriptions, making them more adaptable and capable of handling complex tasks.
Advantages of VLM-CaR
The VLM-CaR framework offers several advantages over traditional methods of reward function design:
- Automation: VLM-CaR automates the process of generating reward functions, eliminating the need for manual intervention. This saves time and effort for environment designers and allows RL agents to learn directly from visual inputs.
- Interpretability: The reward functions generated by VLM-CaR are interpretable, as they are derived from visual observations. This allows environment designers and researchers to understand and analyze the behavior of RL agents more effectively.
- Improved Training Efficiency: By leveraging VLMs, VLM-CaR enables RL agents to learn efficiently even in environments with sparse or unavailable rewards. This improves the training efficiency and performance of RL agents in complex tasks.
- Generalization: VLM-CaR allows RL agents to generalize their learning from visual inputs and natural language descriptions. This makes them more adaptable, capable of handling complex tasks, and less reliant on handcrafted reward functions.
Future Implications and Research Directions
The VLM-CaR framework opens up new possibilities for reinforcement learning and artificial intelligence research. By leveraging the power of Vision-Language Models, RL agents can learn directly from visual inputs, reducing the need for manual intervention and domain expertise.
However, there are still challenges to overcome and avenues for further research. The performance and scalability of VLM-CaR need to be thoroughly evaluated across various domains and tasks. Additionally, the integration of VLM-CaR with other RL techniques and algorithms could lead to even more powerful and efficient learning systems.
In conclusion, VLM-CaR (Code as Reward) is a promising machine learning framework that empowers reinforcement learning with Vision-Language Models. By automating the process of reward function generation and leveraging the power of VLMs, RL agents can learn efficiently and effectively from visual inputs. This opens up new possibilities for training intelligent agents in complex and diverse environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰