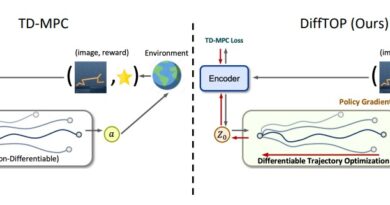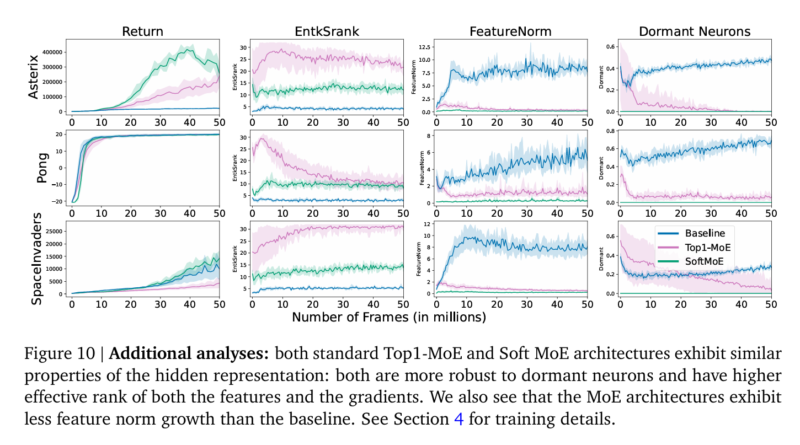
Parameter Scaling for Deep Reinforcement Learning with Mixture-of-Expert Modules: Insights from Google DeepMind Researchers
Deep reinforcement learning (RL) is a field that focuses on training agents to learn and make decisions in complex environments. These agents are trained using algorithms that balance exploration and exploitation to maximize cumulative rewards. However, scaling the parameters of deep RL models has proven to be a challenge. While increasing the size of a neural network often leads to better performance in supervised learning tasks, this is not always the case in RL. In fact, larger networks can sometimes degrade performance instead of improving it.
To address the parameter scaling challenge in deep RL, researchers from Google DeepMind, Mila – Québec AI Institute, Université de Montréal, the University of Oxford, and McGill University have proposed the use of Mixture-of-Expert (MoE) modules. These modules, specifically Soft MoEs, have shown promising results in enhancing parameter efficiency and performance across various sizes and training conditions.
The Challenge of Parameter Scaling in Deep Reinforcement Learning
In deep RL, the scaling of model parameters is crucial for achieving optimal performance. Increasing the size of a neural network allows it to capture more complex patterns and make better predictions. However, simply scaling up the parameters of a deep RL model does not always lead to improved performance. In fact, it can sometimes result in a degradation of performance.
The reason behind this challenge lies like RL algorithms. Unlike supervised learning tasks, RL agents learn through trial and error. They interact with an environment, receive feedback in the form of rewards, and use this feedback to update their policies. The exploration-exploitation trade-off is a fundamental aspect of RL, and scaling the parameters of a model can disrupt this delicate balance.
Mixture-of-Expert Modules: A Solution for Parameter Scaling
To overcome the challenge of parameter scaling in deep RL, the researchers propose the use of Mixture-of-Expert (MoE) modules. MoEs are a type of neural network architecture that combines the predictions of multiple experts to make a final decision. Each expert specializes in a different aspect of the problem and contributes its expertise to the final prediction.
In the context of deep RL, the researchers integrate MoE modules, specifically Soft MoEs, into value-based networks. By doing so, they aim to improve the parameter efficiency and performance of deep RL models. These MoE modules allow the models to better utilize their parameters, leading to more effective learning and improved performance.
Experimental Evaluation and Results
To evaluate the effectiveness of MoE modules in deep RL, the researchers conducted experiments using the Dopamine library and the standard Arcade Learning Environment (ALE) benchmark. They compared the performance of Deep Q-Network (DQN) and Rainbow algorithms with and without MoE modules.
The results of the experiments were promising. The researchers found that incorporating MoEs in deep RL networks improved performance across various training regimes and model sizes. In particular, they observed a 20% performance uplift in the Rainbow algorithm when scaling the number of experts from 1 to 8. This demonstrates the scalability and efficiency of Soft MoEs in deep RL.
Furthermore, the researchers found that Soft MoE modules achieved an optimal balance between accuracy and computational cost. They outperformed other methods and showed promise in diverse training settings, including low-data and offline RL tasks. These findings were supported by robust statistical evaluation methods, such as interquartile mean (IQM) and stratified bootstrap confidence intervals.
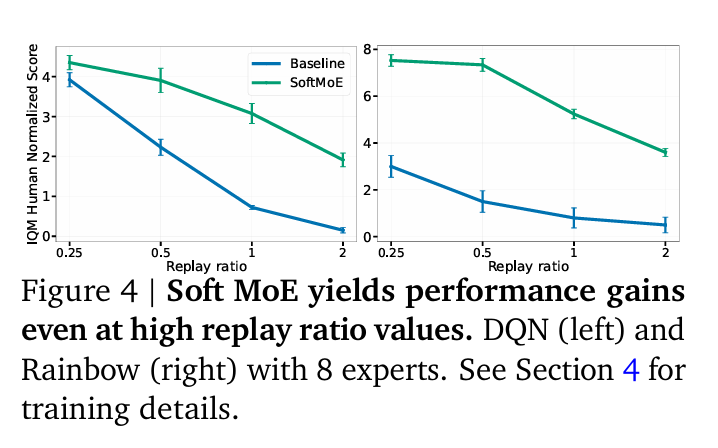


Implications and Future Directions
The research conducted by Google DeepMind researchers and their collaborators sheds light on the importance of parameter scaling in deep RL. By introducing the use of MoE modules, specifically Soft MoEs, they provide valuable insights into improving parameter efficiency and performance in RL networks.
The findings of this research have significant implications for the development of scaling laws in RL. Understanding how to effectively scale the parameters of deep RL models is crucial for advancing the capabilities of RL agents. The use of MoE modules opens up new possibilities for developing more sophisticated and efficient RL models.
Looking ahead, further investigation into the effects of MoEs across various RL algorithms and their combination with other architectural innovations presents a promising avenue for research. Exploring the mechanisms behind the success of MoEs in RL could lead to even more significant advancements in the field.
In conclusion, the research conducted by Google DeepMind researchers and their collaborators provides valuable insights into parameter scaling for deep reinforcement learning. Through the use of Mixture-of-Expert (MoE) modules, specifically Soft MoEs, they demonstrate the potential to improve parameter efficiency and enhance performance in RL networks. These findings pave the way for further advancements in RL agent capabilities and the development of scaling laws in RL.