DiffTOP: Enhancing Deep Reinforcement Learning and Imitation Learning with Differentiable Trajectory Optimization
Deep reinforcement learning and imitation learning have made significant strides in recent years, enabling machines to learn complex tasks through trial and error and by imitating expert demonstrations. However, these approaches often face challenges when it comes to generating effective policy actions based on the input data. To address this issue, researchers from Carnegie Mellon University (CMU) and Peking University have introduced a novel technique called DiffTOP (Differentiable Trajectory Optimization). DiffTOP leverages the power of trajectory optimization and differentiable programming to generate high-quality policy actions for both deep reinforcement learning and imitation learning tasks.
The Importance of Policy Representation
The representation of a policy plays a crucial role in the learning performance of an agent. In previous research, various policy representations, such as feed-forward neural networks, energy-based models, and diffusion, have been explored. Each of these representations has its strengths and weaknesses, and finding the most suitable representation for a specific task is a challenging task in itself.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
However, researchers from CMU and Peking University propose a new policy class called DiffTOP, which combines differentiable trajectory optimization with deep reinforcement and imitation learning. By using high-dimensional sensory data, such as images or point clouds, as input, DiffTOP aims to optimize the trajectory of actions through differentiable programming, resulting in more effective policy actions.
Understanding DiffTOP: Differentiable Trajectory Optimization
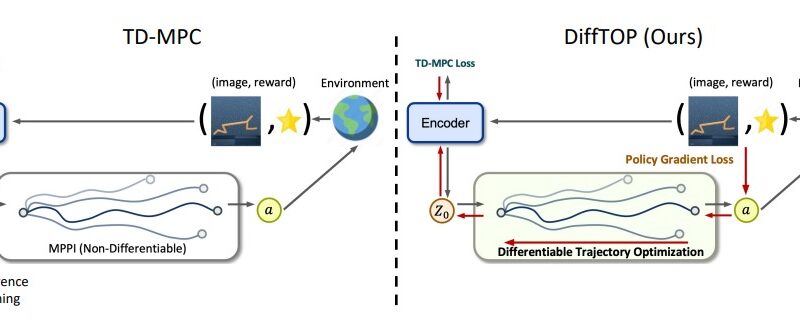
DiffTOP employs differentiable trajectory optimization as a policy representation to generate actions for deep reinforcement learning and imitation learning tasks. The core idea behind DiffTOP is to make trajectory optimization differentiable, enabling back-propagation within the optimization process. This allows the optimization to be guided by the policy gradient loss, resulting in improved learning performance.
In traditional trajectory optimization, a cost function and a dynamics function define the optimization problem. These functions capture the desired behavior of the system and the constraints it needs to satisfy. DiffTOP utilizes neural networks to represent both the cost function and the dynamics function. By learning these functions from input data, DiffTOP can generate actions that optimize task performance.
DiffTOP introduces a hybrid approach that combines deep model-based reinforcement learning algorithms with differentiable trajectory optimization. By leveraging the power of differentiable programming, the researchers can learn the dynamics and cost functions to optimize the reward by computing the policy gradient loss on the generated actions. This approach overcomes the “objective mismatch” problem often encountered in model-based reinforcement learning algorithms, where models that perform well during training may not perform optimally during control tasks.
Advantages of DiffTOP
DiffTOP offers several advantages over traditional approaches in deep reinforcement learning and imitation learning:
1. Improved Learning Performance
By incorporating differentiable trajectory optimization into the policy representation, DiffTOP enables more effective action generation. The back-propagation of the policy gradient loss during optimization allows for the optimization of both the latent dynamics and the reward models, leading to improved learning performance.
2. High-Dimensional Sensory Data Support
DiffTOP is designed to handle high-dimensional sensory data, such as images or point clouds, as input. This makes it suitable for tasks that require processing complex visual or spatial information, opening up new possibilities for applications in computer vision, robotics, and autonomous systems.
3. Compatibility with Existing Algorithms
DiffTOP can be seamlessly integrated into existing deep reinforcement learning and imitation learning algorithms. Its differentiable nature allows for straightforward incorporation into the training pipeline, making it accessible and adaptable for researchers and practitioners.
Experimental Results and Applications
The researchers conducted comprehensive experiments to evaluate the performance of DiffTOP in both model-based reinforcement learning and imitation learning tasks. The experiments included various benchmarking tasks with high-dimensional sensory observations, including Robomimic tasks using images as inputs and Maniskill challenges using point clouds as inputs.
The results demonstrated that DiffTOP outperformed previous state-of-the-art methods in terms of task performance in both reinforcement learning and imitation learning scenarios. DiffTOP showed superior performance in 15 model-based RL tasks and 13 imitation learning tasks, showcasing its effectiveness across different domains and applications.
Furthermore, DiffTOP was compared to feed-forward policy classes, energy-based models (EBM), and diffusion approaches. The evaluation on common robotic manipulation task suites using high-dimensional sensory data revealed that DiffTOP offered improved performance compared to EBM and diffusion-based alternatives. DiffTOP’s training procedure, which leverages differentiable trajectory optimization, resulted in enhanced stability and better control performance.
Conclusion
DiffTOP introduces a promising approach to enhancing deep reinforcement learning and imitation learning tasks by utilizing differentiable trajectory optimization as a policy representation. By optimizing the trajectory and back-propagating the policy gradient loss, DiffTOP enables more effective action generation and improved learning performance. Its compatibility with existing algorithms and support for high-dimensional sensory data make it a versatile and powerful technique for various applications in computer vision, robotics, and autonomous systems.
The research conducted by CMU and Peking University sheds light on the potential of differentiable trajectory optimization and sets the stage for future advancements in policy representation and optimization methods. As the field of deep reinforcement learning and imitation learning continues to evolve, DiffTOP provides a valuable tool for researchers and practitioners to tackle complex learning tasks and achieve higher levels of performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi there colleagues, good paragraph and nice urging commented here,
I am truly enjoying by these.