Questioning the Value of Machine Learning Techniques: Is Reinforcement Learning with AI Feedback All It’s Cracked Up to Be?
Machine learning techniques have revolutionized the field of artificial intelligence (AI) and have paved the way for significant advancements in various domains. One such technique, reinforcement learning with AI feedback (RLAIF), has gained considerable attention in recent years. However, a research paper by Stanford University and the Toyota Research Institute raises thought-provoking questions about the value and effectiveness of this approach.
Understanding Reinforcement Learning with AI Feedback
Before delving into the insights from the research paper, let’s first grasp the concept of reinforcement learning with AI feedback. Reinforcement learning is a machine learning technique in which an agent learns to make decisions based on the feedback it receives from its environment. The agent takes actions, observes the results, and adjusts its behavior accordingly to maximize the rewards or minimize the penalties it receives.
In the context of AI models, reinforcement learning can be used to fine-tune and enhance their capabilities. Reinforcement learning with AI feedback involves a two-step process. The first step, called Supervised Fine-Tuning (SFT), utilizes a teacher model’s demonstrations to train the AI model. The second step employs reinforcement learning, where a critic model’s feedback is used to further fine-tune the AI model.
The Research Findings
The research paper questions the necessity and efficacy of the reinforcement learning step in the RLAIF paradigm, particularly concerning instruction-following enhancements for large language models (LLMs). The researchers propose a straightforward yet effective alternative approach, which involves using a single strong teacher model, such as GPT-4, for both SFT and AI feedback.
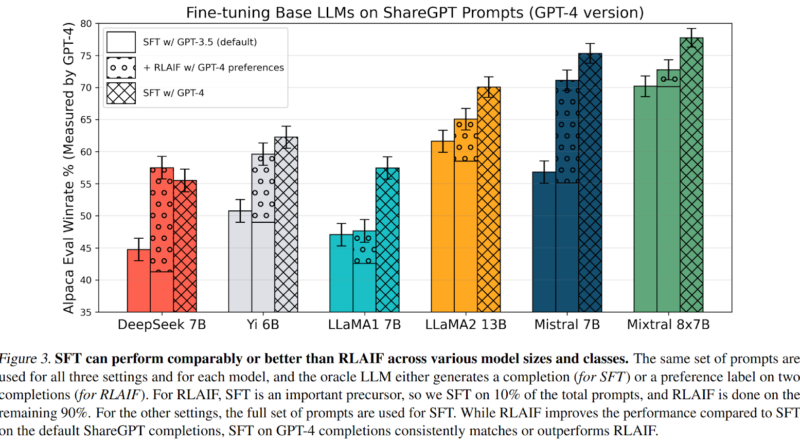
To compare the traditional RLAIF pipeline with the proposed approach, the researchers conducted experiments using different combinations of teacher and critic models. The results were intriguing. When a weaker teacher model (GPT-3.5) was used for SFT and a stronger critic model (GPT-4) for AI feedback, the traditional RLAIF process improved instruction-following capabilities. However, when GPT-4 was used for both SFT and AI feedback, the performance gains attributed to the RL step significantly diminished. This indicates that the improvements achieved through the RL step could primarily be a result of using a stronger critic model for AI feedback generation.
The findings of the research challenge the conventional belief in the indispensability of the RL step in the RLAIF paradigm. Instead, it suggests that employing a strong teacher model for SFT can simplify the process and yield superior or equivalent model performance compared to the traditional approach. The quality of the teacher model used in the SFT phase appears to play a crucial role in achieving desirable outcomes, calling into question the necessity of the subsequent RL phase.
Implications and Future Research
The research paper’s findings have significant implications for the field of machine learning and AI. By highlighting the varying effectiveness of RLAIF across different base model families, evaluation protocols, and critic models, the study emphasizes the critical role of the initial SFT phase and the choice of teacher model. It suggests that a simpler approach of using a strong teacher model for both SFT and AI feedback can lead to comparable or even superior results, simplifying the alignment process for LLMs.
The research paper opens up new avenues for future investigations into the most effective strategies for LLM alignment. It encourages researchers to explore the potential of utilizing strong teacher models and optimizing AI feedback to advance LLMs without relying heavily on the RL step. This shift in perspective can lead to the development of more streamlined and efficient approaches for harnessing the full capabilities of AI feedback in enhancing instruction-following abilities of AI models.
Conclusion
The research paper by Stanford University and the Toyota Research Institute challenges the prevailing belief in the indispensability of reinforcement learning with AI feedback in the context of instruction-following enhancements for LLMs. The study suggests that using a strong teacher model for both Supervised Fine-Tuning and AI feedback can yield comparable or better results than the traditional RLAIF pipeline. It highlights the critical role of the choice of teacher model and calls for a reevaluation of current LLM alignment techniques.
While further research is needed to validate and explore the findings of this study, it provides valuable insights for improving the efficiency and effectiveness of machine learning techniques. By simplifying the alignment process and optimizing AI feedback, researchers can unlock the full potential of AI models in various domains, leading to more responsive and accurate AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰