Reinforcement Learning: Training AI Agents Through Rewards and Penalties
Reinforcement learning (RL) is a fascinating field of AI that focuses on training agents to make decisions by interacting with an environment and learning from rewards and penalties. Unlike supervised learning, which relies on a static dataset, RL involves active engagement and learning through trial and error. In this article, we will delve into the core principles of RL and explore its applications in various domains.
The Core Principles of Reinforcement Learning
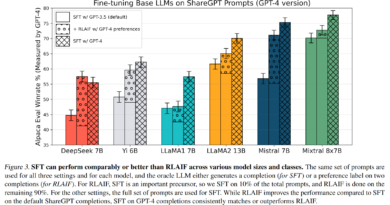
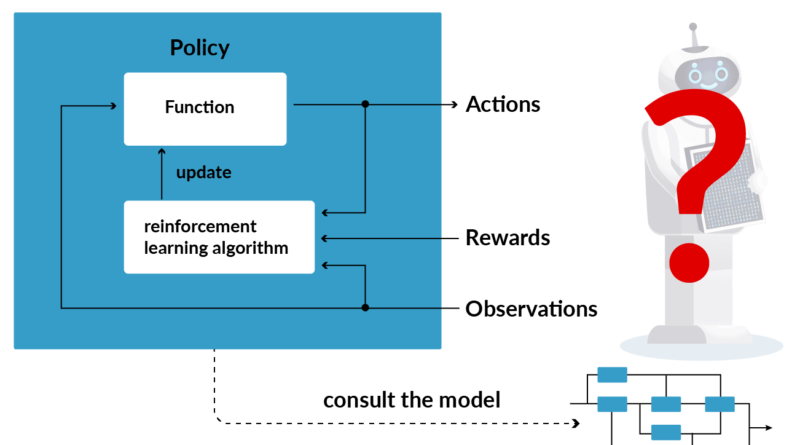
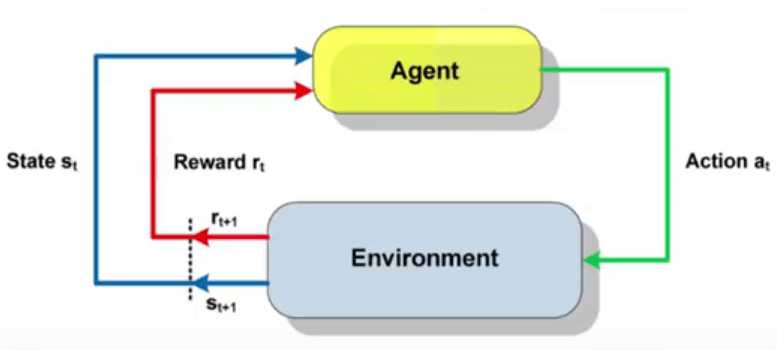
At the heart of RL lies the concept of an agent, which is an entity capable of making decisions and taking actions. The agent interacts with an environment, receiving feedback in the form of rewards or penalties based on its actions. The goal of the agent is to learn the optimal behavior that maximizes the cumulative reward over time.
Rewards and Penalties
In RL, rewards and penalties play a crucial role in shaping the agent’s behavior. Rewards are positive signals given to the agent when it takes desirable actions, while penalties (also known as punishments) are negative signals given for undesirable actions. By associating rewards and penalties with specific actions, the agent learns to differentiate between good and bad behavior.
Exploration and Exploitation
RL algorithms strike a balance between exploration and exploitation. During the exploration phase, the agent tries out different actions to gather information about the environment and learn which actions lead to higher rewards. In the exploitation phase, the agent exploits the knowledge it has gained to select actions that are expected to yield the highest rewards.
Temporal Difference Learning
Temporal Difference (TD) learning is a popular RL technique that involves updating action-value estimates based on the difference between predicted and observed rewards. TD learning enables agents to learn from sequential experiences by propagating reward information back in time. Q-learning and SARSA are well-known TD learning algorithms that have been successfully applied in various domains.
Applications of Reinforcement Learning
Game Playing
RL has demonstrated its potential in game playing by developing AI agents that outperform human champions in various games. Algorithms like Q-learning and Deep Q-Networks (DQN) enable agents to learn optimal strategies through millions of iterations.
One notable example is DeepMind’s AlphaGo, which famously defeated the world champion in the game of Go. AlphaGo combined supervised learning and RL to learn effective strategies. OpenAI’s Dota 2 bots are another remarkable example, as they learned to play the complex multiplayer online game Dota 2 by training in simulated environments using techniques like Proximal Policy Optimization (PPO).
Robotics
RL plays a crucial role in enabling robots to learn and adapt to their environments. Algorithms like Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) train agents to perform tasks such as walking, picking up objects, and flying drones.
Boston Dynamics’ Spot robot dog utilizes RL to navigate complex terrains and perform challenging maneuvers. By training in simulated environments like Mujoco, agents can safely explore different actions before applying them in the real world. This approach allows robots to gain experience in simulation, refining their skills through thousands of simulated trials before being deployed in real-world applications.
Resource Management
RL is increasingly being used in resource management scenarios to optimize the allocation of limited resources. In cloud computing, RL algorithms help optimize scheduling to minimize costs and latency by dynamically allocating resources based on workload demand. Microsoft Research’s Project PAIE is an example of using RL to optimize resource management.
In energy management, RL can optimize power distribution in smart grids. By learning consumption patterns, these algorithms enable grids to distribute energy more efficiently, reduce waste, and stabilize the power supply.
Popular RL Algorithms
Several popular RL algorithms have been developed to tackle different types of problems. Let’s take a look at a few of them:
- Q-Learning: Q-learning is a model-free RL algorithm that learns an action-value function called Q-function. It iteratively updates the Q-values based on the observed rewards and the maximum expected future rewards.
- Deep Q-Networks (DQN): DQN is an extension of Q-learning that uses deep neural networks to approximate the Q-function. It has been successfully applied to challenging tasks, such as playing Atari games.
- Proximal Policy Optimization (PPO): PPO is a policy optimization algorithm that alternates between sampling data from the environment and taking multiple steps of stochastic gradient ascent to update the policy. It has been widely used in robotics and game playing.
- Soft Actor-Critic (SAC): SAC is an off-policy RL algorithm that learns a stochastic policy. It maximizes the expected cumulative reward while also maximizing entropy, which encourages exploration.
Conclusion
Reinforcement learning offers a unique approach to training AI agents by allowing them to learn optimal behaviors through rewards and penalties. Its applications range from game playing, where RL agents can outperform human champions, to robotics, where RL enables robots to learn and adapt to their environments. RL also finds applications in resource management, optimizing the allocation of limited resources.
As RL algorithms continue to evolve and computational capabilities expand, the potential to apply RL in more complex, real-world scenarios will only grow. The combination of rewards and penalties as feedback mechanisms empowers AI agents to learn and make decisions in dynamic and uncertain environments.
Sources
- https://deepmind.com/research/case-studies/alphago-the-story-so-far
- https://www.bostondynamics.com/spot
- https://openai.com/research/openai-five
- https://en.wikipedia.org/wiki/AlphaGo
- http://www.mujoco.org/
- https://www.microsoft.com/en-us/research/project/paie/
- https://ai.googleblog.com/2019/01/soft-actor-critic-algorithm-for.html
- https://www.microsoft.com/en-us/research/project/learned-resource-management-systems/
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰