OLMoASR Explained: Architecture, Benchmarks, and How It Stands Against Whisper
Introduction
In recent years, automatic speech recognition (ASR) has evolved rapidly, thanks to advances in deep learning and the emergence of massive datasets. Yet, the field remains dominated by proprietary black-box solutions from big tech companies such as OpenAI, Google, and Amazon. Enter OLMoASR, a fully open, high-performance ASR suite developed by the Allen Institute for AI (AI2) that directly challenges the status quo.



This article takes a deep dive into OLMoASR, comparing it to OpenAI’s Whisper, one of the most widely adopted ASR models today. We’ll examine the architecture, datasets, benchmarks, and implications of transparency in ASR model development—offering researchers and developers a comprehensive view of how these systems stack up.
What is OLMoASR?
OLMoASR (Open Language Models for Automatic Speech Recognition) is a family of fully open-source ASR models released by the Allen Institute for AI. Unlike most commercial ASR systems that offer only API-based access, OLMoASR includes:
- Pretrained model weights
- Training data identifiers
- Filtering steps
- Full training recipes
- Benchmarking scripts
This holistic openness enables reproducibility, fine-tuning, and deeper scientific exploration, setting it apart from competitors like Whisper and Google’s Speech-to-Text API.
Why Does Openness Matter in ASR?
The majority of high-performing ASR systems today are closed by design. Their training data is proprietary, model internals are not disclosed, and usage is limited to paid APIs. This lack of transparency leads to several limitations:
- Reproducibility issues in academic research
- Bias auditing becomes difficult
- No access to fine-tuning or domain adaptation
- Vendor lock-in for commercial users
OLMoASR counters these limitations by making everything—models, data, scripts—open and accessible, encouraging innovation across industry and academia.
Model Architecture: How OLMoASR and Whisper Compare
Both OLMoASR and Whisper follow the transformer-based encoder-decoder architecture, which is now the dominant paradigm in ASR.
| Feature | OLMoASR | OpenAI Whisper |
|---|---|---|
| Architecture | Transformer encoder-decoder | Transformer encoder-decoder |
| Pretraining | From scratch | From scratch |
| Open Weights | Yes | No |
| Training Code | Yes | No |
| Fine-tuning Support | Yes (recipes provided) | Not available |
| Languages | English | Multilingual (96 languages) |
While Whisper supports multilingual transcription, OLMoASR is currently English-only, but it compensates with openness, modularity, and extensibility.
Model Sizes and Flexibility
OLMoASR offers six English-only models with varying parameter sizes, optimized for different use-cases:
- tiny.en – 39M parameters (lightweight, fast inference)
- base.en – 74M
- small.en – 244M
- medium.en – 769M
- large.en-v1 – 1.5B (trained on 440K hours)
- large.en-v2 – 1.5B (trained on 680K hours)
OpenAI’s Whisper provides similar scaled models (tiny to large), but without fine-tuning support or open training data. The presence of smaller models in OLMoASR allows developers to balance between compute cost and accuracy, making it suitable for both edge devices and research environments.
Training Datasets: Transparency vs. Mystery
OLMoASR’s Datasets
OLMoASR’s training datasets are fully documented and released:
- OLMoASR-Pool (~3M hours): A massive, weakly supervised web-scraped dataset.
- OLMoASR-Mix (~1M hours): A filtered subset with:
- Alignment heuristics
- Deduplication
- Transcript cleaning
This two-tiered strategy (noisy + filtered data) follows best practices seen in LLM pretraining, enabling both scale and quality.
Whisper’s Dataset
Whisper was trained on 680,000 hours of multilingual and multitask data, but the dataset has not been released, and details remain vague. This black-box nature limits transparency and replicability.
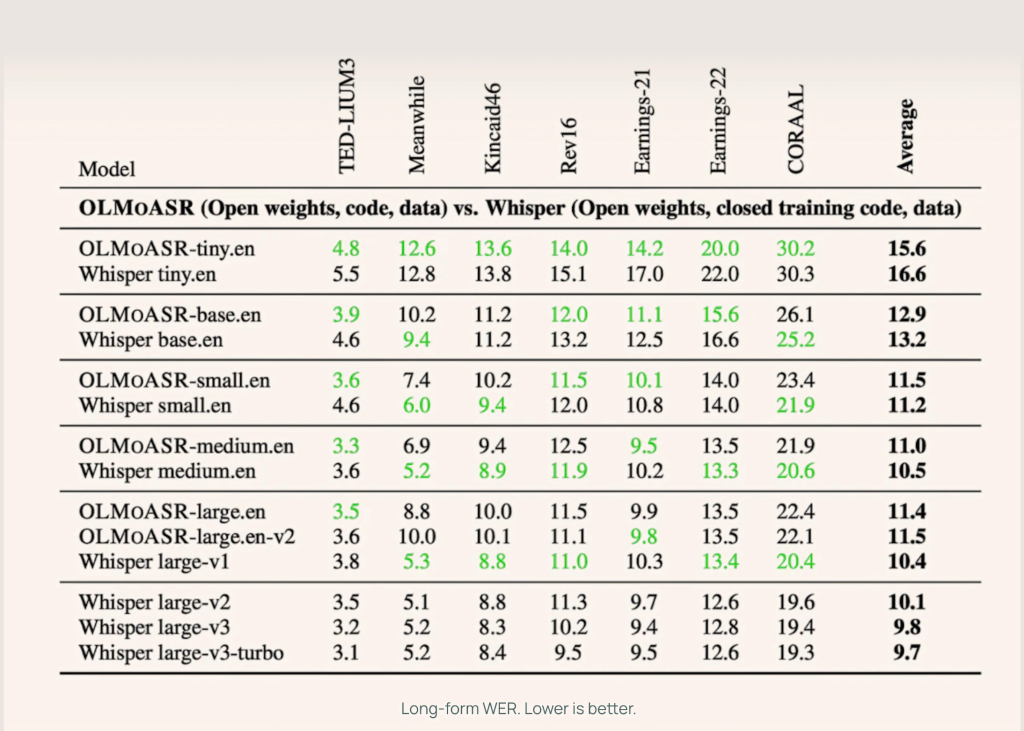
Performance Benchmarks: WER Comparisons
OLMoASR has been rigorously benchmarked against Whisper on a variety of standard datasets like LibriSpeech, TED-LIUM3, Switchboard, AMI, and VoxPopuli.
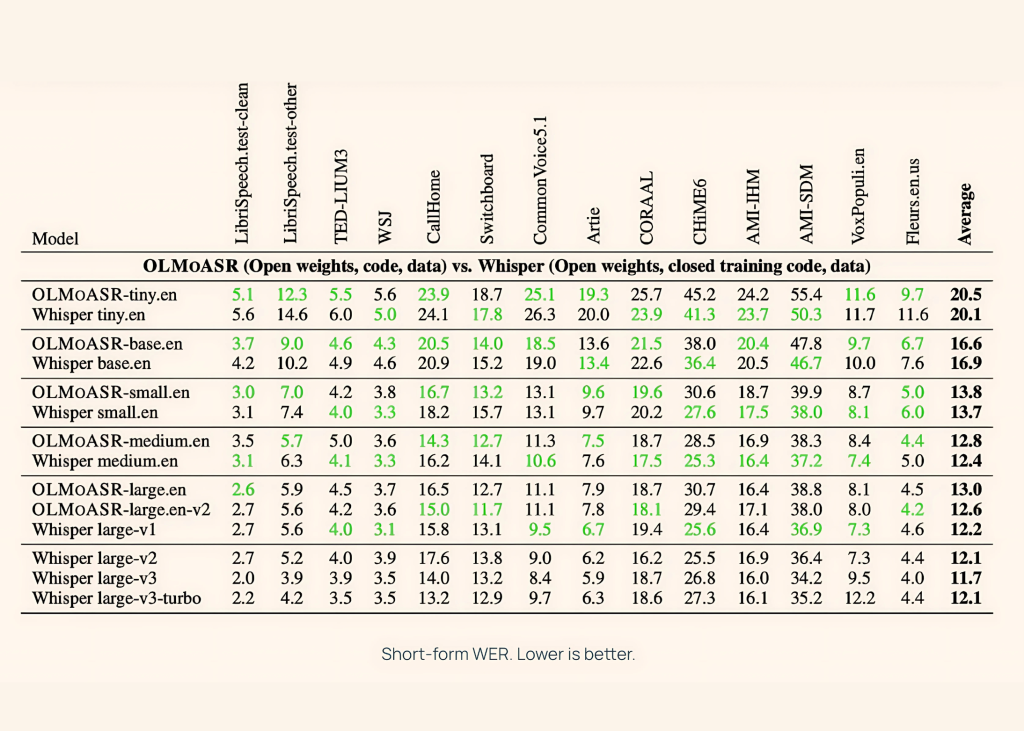
Medium Models (769M)
| Metric | OLMoASR-Medium | Whisper-Medium |
|---|---|---|
| Short-form WER | 12.8% | 12.4% |
| Long-form WER | 11.0% | 10.5% |
Large Models (1.5B)
| Metric | OLMoASR Large-v2 | Whisper-Large |
|---|---|---|
| Short-form WER | 12.6% | 12.2% |
| Long-form WER | ~10.8% | 10.5% |
These numbers show that OLMoASR is on par with Whisper, especially in the larger variants.
Code Integration and Usability
Using OLMoASR is simple and lightweight:
import olmoasr
model = olmoasr.load_model("medium", inference=True)
result = model.transcribe("audio.mp3") print(result)The model returns:
- Transcribed text
- Time-aligned segments (for captioning and diarization)
Whisper also supports time-aligned transcription, but OLMoASR allows full control over the inference pipeline.
Fine-Tuning and Domain Adaptation
A standout feature of OLMoASR is its support for domain-specific fine-tuning, made possible by the open-source training recipes.
Use Cases for Fine-Tuning
- Healthcare: Train on doctor-patient conversations
- Legal Tech: Adapt to courtroom audio or legal jargon
- Accents and Dialects: Improve recognition for regional speech patterns
Whisper does not provide any fine-tuning capability as of now.
Applications Across Industry and Academia
OLMoASR’s flexibility makes it suitable for a wide range of applications:
Academic Research
- Study model scaling
- Benchmark filtering techniques
- Evaluate reproducibility in ASR
Commercial Use
- Build private, on-prem ASR pipelines
- Avoid vendor lock-in
- Enhance accessibility tools
Multimodal Systems
- Combine with LLMs for voice assistants
- Integrate with video captioning pipelines
- Enable real-time translation workflows
Limitations of OLMoASR
While powerful, OLMoASR has some limitations:
- Currently English-only
- Lack of built-in speaker diarization
- Large models require high compute for training
- No ready-to-use mobile deployment toolkit
That said, these are solvable as the community around OLMoASR grows.
Conclusion
OLMoASR represents a major milestone in open speech recognition. It combines state-of-the-art performance with full transparency, making it a compelling alternative to commercial black-box systems like OpenAI’s Whisper. While Whisper still holds an edge in multilingual support and production maturity, OLMoASR’s openness allows developers and researchers to build, audit, and innovate in ways that were previously impossible.
For organizations looking to develop speech-based applications with full control, or for researchers aiming to advance ASR scientifically, OLMoASR is not just an alternative—it is the new open standard.
Check out the MODEL on Hugging Face, GitHub Page and TECHNICAL DETAILS. All credit for this research goes to the researchers of this project. Explore one of the largest MCP directories created by AI Toolhouse containing over 4500+ MCP Servers: AI Toolhouse MCP Servers Directory