RAGEval: A New Approach to Evaluating Retrieval-Augmented Generation Systems
Large Language Models (LLMs) have significantly advanced natural language processing, but they still struggle with accuracy, often generating incorrect information. To tackle this issue, researchers are turning to Retrieval-Augmented Generation (RAG) systems, which combine retrieval methods with generation models to produce more accurate results.
Challenges with Current Evaluation Methods
Existing benchmarks for evaluating RAG systems focus primarily on general knowledge and simple question-answering tasks. These methods fall short when assessing how well a RAG system performs in specific fields like finance, healthcare, and law, where precision is crucial. Evaluating RAG systems across different specialized domains remains a challenge due to the complexity and privacy concerns associated with domain-specific data.
RAGEval Framework
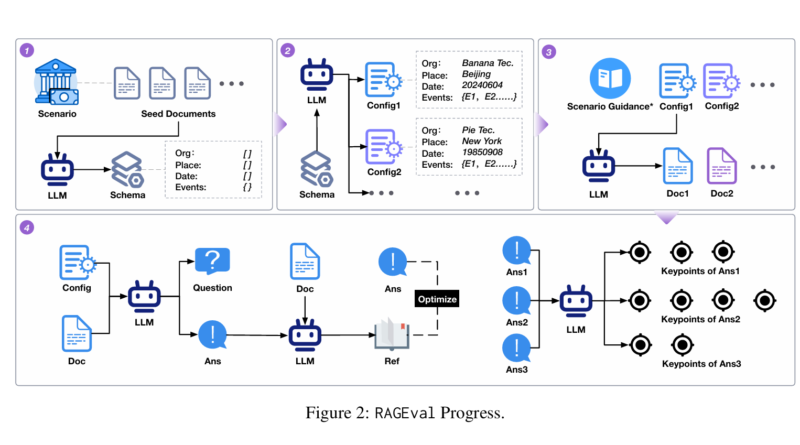
RAGEval is a new framework designed to address these challenges by automatically generating scenario-specific evaluation datasets for RAG systems. Here’s how it works:
- Schema Summary: RAGEval starts by creating a schema from a small set of domain-specific documents. This schema serves as a blueprint for generating new content.
- Document Generation: Using the schema, RAGEval creates various configurations that reflect different scenarios within the domain. These configurations are then used to generate new documents that mimic real-world data.
- Question-Answer Pair Generation: Finally, RAGEval creates question-answer pairs based on the generated documents and configurations. These pairs are used to test the accuracy of RAG systems.
New Evaluation Metrics
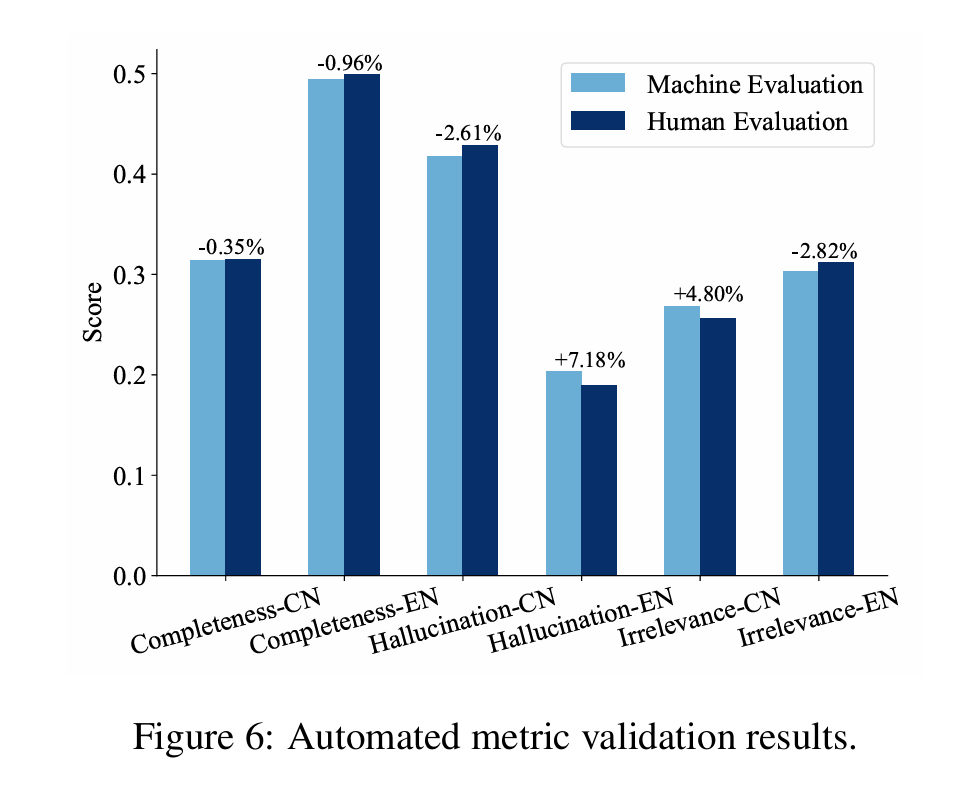
RAGEval introduces three new metrics to evaluate RAG systems more effectively:
- Completeness: Measures how well the generated answers cover the key information from the source material.
- Hallucination: Identifies instances where the generated content contradicts the key information.
- Irrelevance: Assesses the proportion of key information that is missing or ignored in the generated answers.
DRAGONBall Dataset
Using the RAGEval framework, the DRAGONBall dataset was created, covering finance, law, and medical domains. This dataset includes documents in both Chinese and English and provides a robust resource for evaluating RAG systems across multiple languages and specialized fields.
Conclusion
RAGEval offers a more accurate and comprehensive way to evaluate RAG systems, particularly in specialized domains where precision is critical. This framework and its associated metrics represent a significant step forward in improving the reliability of LLMs when combined with retrieval methods.
Got an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.
Explore 3600+ latest AI tools at AI Toolhouse 🚀. Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰