Researchers at Cornell University Introduced HiQA: An Advanced Artificial Intelligence Framework for Multi-Document Question-Answering (MDQA)
Artificial Intelligence (AI) has revolutionized the way we interact with computers and process information. It has enabled machines to understand and respond to human language, leading to advancements in various applications such as chatbots, virtual assistants, and question-answering systems. Researchers at Cornell University have recently introduced HiQA, an advanced AI framework for Multi-Document Question-Answering (MDQA), which addresses the challenges posed by extensive collections of structurally similar documents.
The Challenge of Multi-Document Question-Answering
Traditional question-answering systems in Natural Language Processing (NLP) often struggle when faced with scenarios involving vast amounts of homogeneous data. In the case of multi-document QA (MDQA) tasks, where the system needs to integrate information from multiple documents to formulate coherent answers, the precision and relevance of responses can be compromised. This is where HiQA steps in to overcome these challenges and provide more accurate and relevant answers.
Retrieval-Augmented Generation (RAG) and HiQA
To tackle the challenges of MDQA, researchers have turned to Retrieval-Augmented Generation (RAG) techniques. RAG combines retrieval and generation models to extract critical information from unstructured texts. This approach has shown effectiveness across diverse NLP tasks and can be extended to multimodal tasks, such as image generation, using pre-trained models like CLIP for retrieval. Integrating reasoning capabilities of Language Models (LLMs) into RAG allows for the evaluation of the need for retrieval and the relevance of context.
HiQA builds upon the foundations of RAG and introduces a novel framework that enhances retrieval accuracy and coherence within multi-document environments. The framework incorporates cascading metadata and a multi-route retrieval mechanism to optimize knowledge retrieval.
The Components of HiQA
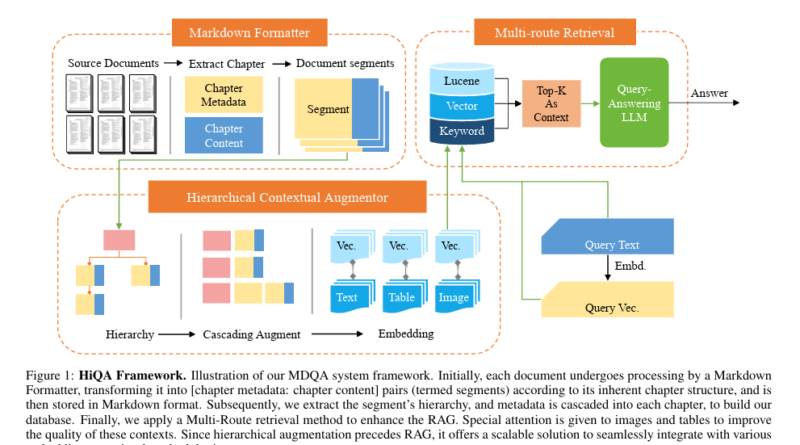
HiQA comprises three core components: a Markdown Formatter (MF), a Hierarchical Contextual Augmentor (HCA), and a Multi-Route Retriever (MRR). Each component plays a crucial role in improving the performance and accuracy of the MDQA system.
1. Markdown Formatter (MF)
The MF component of HiQA is responsible for parsing the source documents into markdown files. It divides the documents into distinct chapters or sections, which enables better organization and retrieval of relevant information.
2. Hierarchical Contextual Augmentor (HCA)
The HCA component enriches document segments with hierarchical metadata, optimizing the information structure for retrieval. By adding contextual information to each segment, HCA enhances the coherence and relevance of the retrieved knowledge. This hierarchical approach helps the MDQA system understand the relationships between different documents and extract valuable insights.
3. Multi-Route Retriever (MRR)
The MRR component of HiQA employs a sophisticated approach to retrieve the most relevant segments from the multi-document environment. It leverages vector similarity, Elastic search, and keyword matching to meticulously select the segments that best address the given question. By combining multiple retrieval routes, the MRR enhances the accuracy and precision of the MDQA system.
Evaluating HiQA’s Performance
To evaluate the effectiveness of HiQA, the researchers introduced the MasQA dataset, which consists of technical manuals, a college textbook, and public financial reports. This dataset encompasses various types of questions, including single and multiple-choice, descriptive, comparative, table, and calculation questions.
To measure the performance of the Retrieval-Augmented Generation (RAG) algorithm in document ranking, the researchers proposed the Log-Rank Index as a novel evaluation metric. This metric helps assess how well the algorithm ranks the relevance of documents.
Additionally, Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (tSNE) visualizations were used to demonstrate the impact of the Hierarchical Contextual Augmentor (HCA) on the distribution of document segments in the embedding space. These visualizations showed that HCA leads to a more compact distribution, indicating a focused retrieval of relevant information.
The Significance of HiQA
The introduction of HiQA represents a groundbreaking advancement in MDQA, addressing the critical challenge of efficiently processing and retrieving information from large-scale indistinguishable documents. By using a soft partitioning approach and enhancing retrieval mechanisms, HiQA outperforms traditional methods in terms of accuracy and relevance.
HiQA’s innovative framework has both theoretical and practical implications. It contributes to the theoretical understanding of document segment distribution in the embedding space, shedding light on how knowledge is organized within vast collections of documents. Furthermore, HiQA’s practical implications extend to various applications that require accurate and efficient retrieval of information.
Conclusion
Researchers at Cornell University have introduced HiQA, an advanced Artificial Intelligence framework for Multi-Document Question-Answering (MDQA). HiQA addresses the challenges posed by extensive collections of structurally similar documents by incorporating cascading metadata and a multi-route retrieval mechanism. By leveraging these components, HiQA offers more accurate and relevant answers to MDQA tasks.
This groundbreaking framework paves the way for future innovations in the field of question-answering systems. The development and validation of HiQA contribute to both the theoretical understanding of document segment distribution and the practical implications for a wide range of applications. With HiQA, the accessibility and precision of information retrieval in multi-document environments are greatly enhanced.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hey very interesting blog!
I’m truly enjoying the design and layout of
your website. It’s a very easy on the eyes which makes it much
more enjoyable for me to come here and visit more often. Did you hire out a developer to create your theme?
Great work!
Thank you for some other informative site. Where else may just I get that kind of
information written in such a perfect way?
I have a challenge that I am simply now working on, and I have been on the glance out for such information.
I just like the valuable information you provide
to your articles. I will bookmark your weblog and test again right here regularly.
I’m moderately certain I will be told many new stuff proper
right here! Best of luck for the following!
Howdy! I could have sworn I’ve been to this site before but after looking at a few of the articles I realized it’s new to me.
Anyhow, I’m definitely delighted I stumbled upon it and I’ll be
bookmarking it and checking back often!
Hi there to all, the contents present at this web page are actually remarkable for
people experience, well, keep up the good work fellows.
Hello great website! Does running a blog similar to this require
a lot of work? I have virtually no knowledge
of computer programming but I had been hoping to start my own blog in the near
future. Anyways, should you have any suggestions or techniques for new blog owners please share.
I understand this is off subject nevertheless I just needed to ask.
Many thanks!
Hi friends, how is the whole thing, and what you wish
for to say on the topic of this post, in my view its really remarkable
for me.
Hello i am kavin, its my first time to commenting anyplace, when i read this post i thought i
could also make comment due to this good post.
Normally I don’t read article on blogs, but I wish to say that
this write-up very compelled me to check out and do
it! Your writing taste has been amazed me. Thank you,
quite nice article.
I’m extremely pleased to uncover this page. I want to to thank you for ones time just for this fantastic read!!
I definitely liked every part of it and i also have you bookmarked to
check out new information in your site.
Good site you’ve got here.. It’s hard to find high
quality writing like yours nowadays. I really appreciate individuals like you!
Take care!!
Hi there, the whole thing is going sound here and ofcourse
every one is sharing facts, that’s actually excellent, keep up writing.