Salesforce AI Unveils ‘ThinK’: Revolutionary AI Technique Leveraging Extensive Redundancy in KV Cache Channel Dimension
Artificial Intelligence (AI) is transforming numerous sectors by enhancing efficiency, automating tasks, and providing tailored experiences. Salesforce, a prominent CRM provider, continues to innovate with its Einstein AI technologies. The latest development from Salesforce AI Research is ‘ThinK,’ an advanced AI technique that leverages significant redundancy within the channel dimension of the KV cache. This article delves into the importance of ThinK, its advantages, and its influence on optimizing AI.
Table of Content
- Understanding the Challenge
- Existing Approaches to LLM Optimization
- Introducing ThinK: A Breakthrough in AI Optimization
- How ThinK Works
- The Effectiveness of ThinK
- The Future of ThinK and AI Optimization
Understanding the Challenge
To appreciate the significance of ThinK, we must first understand the challenges faced by Large Language Models (LLMs), which have become increasingly popular in natural language processing tasks. LLMs demonstrate remarkable performance across various applications, but they come with significant cost and efficiency concerns.
The cost of generating LLMs increases with model size and sequence length. Both the training and inference stages incur substantial expenses, making it essential to develop efficient architectures. Additionally, managing long sequences presents computational burdens due to the quadratic complexity of the transformer attention mechanism.
Existing Approaches to LLM Optimization
Researchers have already pursued various approaches to address the computational challenges of LLMs, particularly in long-context scenarios. Some of these methods include:
- KV Cache Eviction Methods: StreamingLLM, H2O, SnapKV, and FastGen aim to reduce memory usage by selectively retaining or discarding tokens based on their importance.
- KV Cache Quantization Techniques: Methods like SmoothQuant and Q-Hitter compress the cache while minimizing performance loss.
- Structured Pruning: This approach focuses on removing unimportant layers, heads, and hidden dimensions of LLMs. However, these methods often result in significant performance degradation or fail to exploit potential optimizations fully.
While these existing approaches have made progress in addressing LLM optimization challenges, further advancements are necessary to achieve optimal memory usage and preserve model performance.
Introducing ThinK: A Breakthrough in AI Optimization
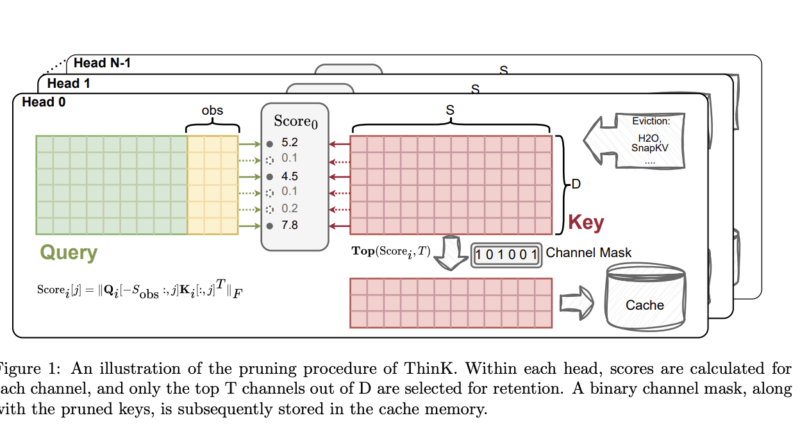
Researchers from Salesforce AI Research and The Chinese University of Hong Kong have introduced ThinK, a novel KV cache pruning method that leverages the channel dimension of the key cache. ThinK approaches the pruning task as an optimization problem, aiming to minimize attention weight loss from pruning. This method introduces a query-dependent criterion for assessing channel importance and selects critical channels greedily. By doing so, ThinK effectively reduces memory consumption while preserving model performance.


ThinK is built on key observations from LLaMA3-8B model visualizations, where key cache channels demonstrate varying magnitudes of significance, while the value cache lacks clear patterns. The singular value decomposition of attention matrices reveals that only a few singular values carry high energy, indicating the attention mechanism’s low-rank nature. These insights suggest that the key cache can be approximated effectively using low-dimensional vectors.
How ThinK Works
The ThinK method optimizes the KV cache in LLMs by pruning the channel dimension of the key cache. It formulates the pruning task as an optimization problem, aiming to minimize the difference between original and pruned attention weights. Here is an overview of how ThinK works:
- Query-Driven Pruning Criterion: ThinK introduces a query-driven pruning criterion to evaluate channel importance based on the interaction between the query and key vectors. This criterion helps identify the most relevant channels for preserving the primary information flow in the attention computation.
- Greedy Channel Selection: Using a greedy algorithm, ThinK selects the most important channels for the key cache, ensuring that crucial information is retained while reducing memory consumption.
- Observation Window: ThinK focuses on long-context scenarios and employs an observation window to reduce computational costs. This window enables efficient computation by considering a limited context instead of the entire input.
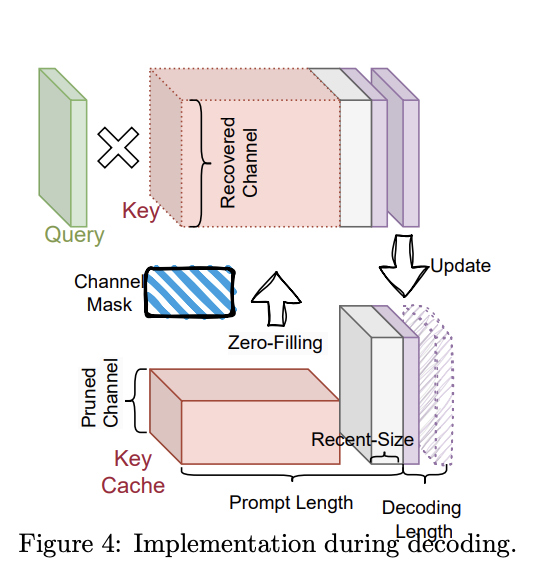
- Dual Key Categories: ThinK maintains two categories of keys in the KV cache: pruned keys with a reduced channel size and unpruned keys at the original size. A binary mask tracks the pruned channels.
During decoding, pruned keys are zero-filled and concatenated with unpruned keys, or the query is pruned before multiplication with the corresponding keys. ThinK can be integrated with optimization techniques like FlashAttention, potentially offering improved computational efficiency while maintaining model performance.
The Effectiveness of ThinK
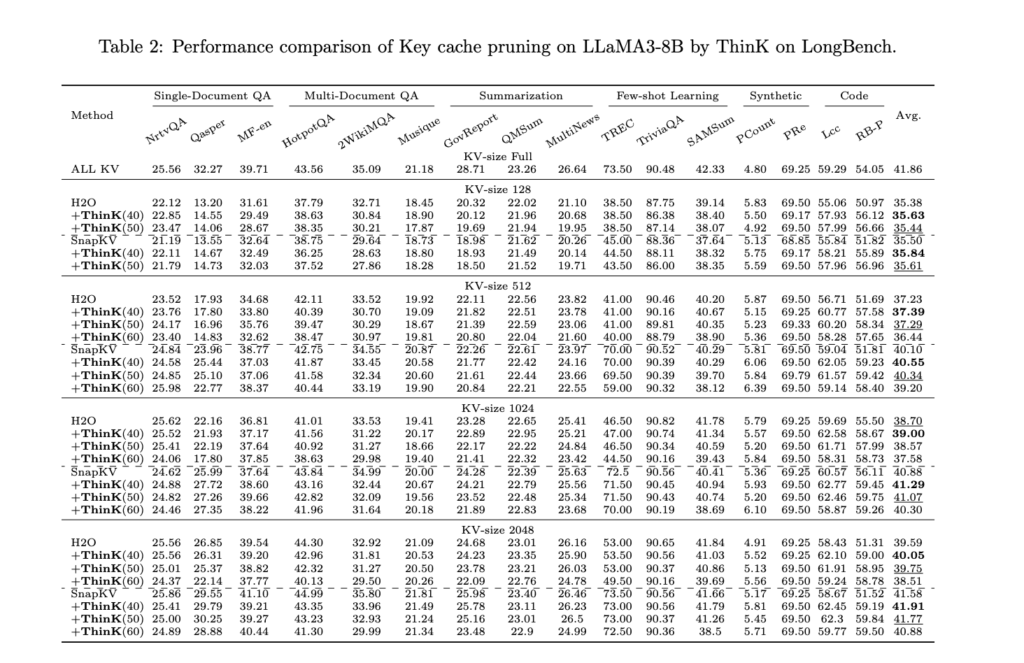
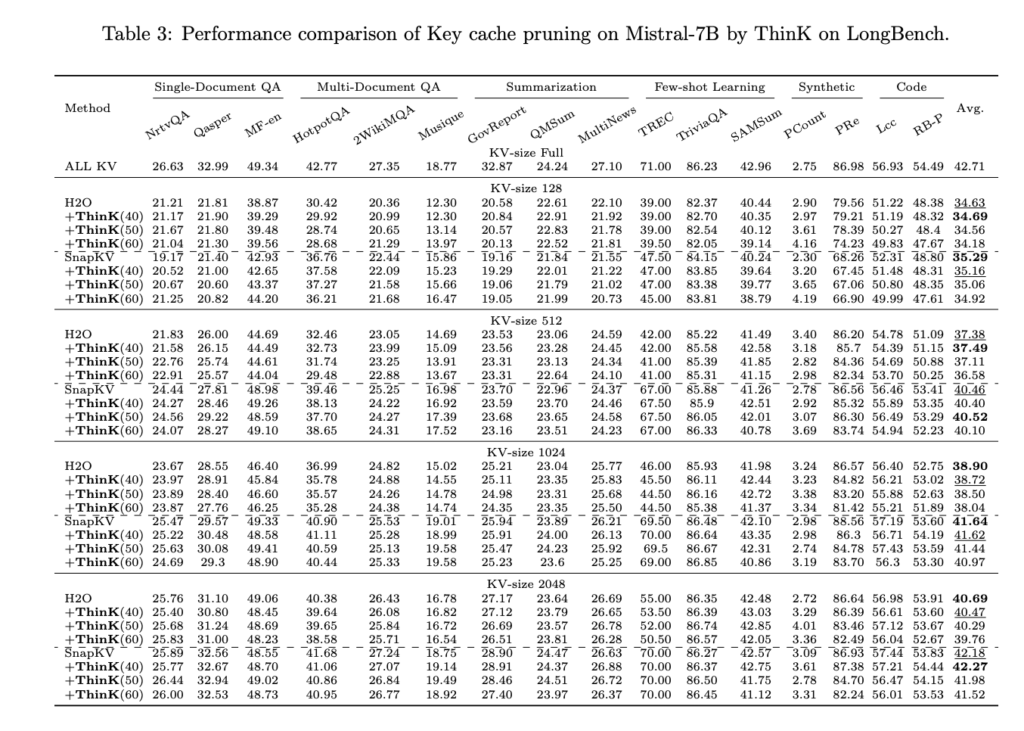
Experimental results demonstrate the effectiveness of ThinK in optimizing LLMs for long-context scenarios. ThinK achieves a significant reduction in cache size while maintaining or even improving performance on major benchmarks such as LongBench and Needle-in-a-Haystack tests. The key findings include:
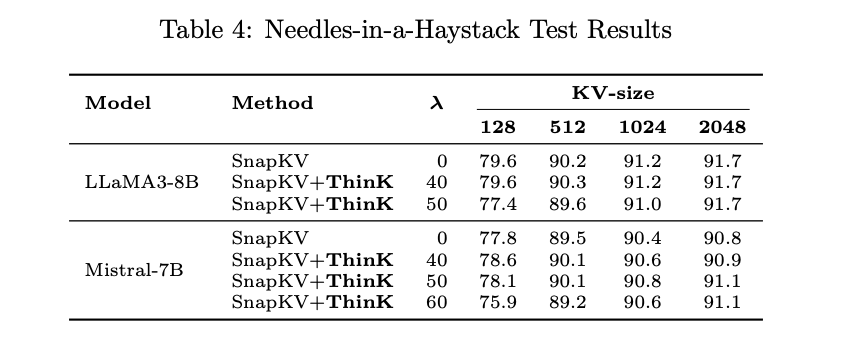
- Cache Size Reduction: ThinK achieves up to 40% reduction in cache size without sacrificing performance.
- Improved Memory Efficiency: ThinK’s unique key cache pruning method enhances memory efficiency, making it an effective solution for managing computational resources in LLMs.
These results highlight ThinK’s compatibility with existing optimization techniques and its robust performance across various benchmarks, underscoring its effectiveness and versatility.
The Future of ThinK and AI Optimization
ThinK emerges as a promising advancement in optimizing Large Language Models for long-context scenarios. By introducing query-dependent channel pruning for the key cache, this innovative method substantially reduces cache size while maintaining or improving performance. ThinK’s compatibility with existing optimization techniques and its ability to deliver robust results across various benchmarks underscore its effectiveness and versatility.
As the field of natural language processing continues to evolve, ThinK’s approach to balancing efficiency and performance addresses critical challenges in managing computational resources for LLMs. This method enhances the capabilities of current models and paves the way for more efficient and powerful AI systems in the future, potentially revolutionizing how we approach long-context processing in language models.
In conclusion, Salesforce AI’s introduction of ‘ThinK’ represents a significant breakthrough in AI optimization. By exploiting substantial redundancy across the channel dimension of the KV cache, ThinK offers a practical solution to reduce memory consumption while preserving model performance. This innovative method holds promise for enhancing the efficiency and effectiveness of Large Language Models, opening doors to new possibilities in the world of AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Got an incredible AI tool or app? Let’s make it shine! Contact us now to get featured and reach a wider audience.