Streamlining Neural Networks with MambaOut for Superior Image Classification
In the field of computer vision, significant advancements have been made in recent years through the use of advanced neural network architectures. These architectures, such as Transformers and Convolutional Neural Networks (CNNs), have revolutionized image classification, object detection, and semantic segmentation tasks, leading to improved accuracy and efficiency in various applications like autonomous driving and medical imaging.
However, one of the key challenges in computer vision lies in the quadratic complexity of the attention mechanism used in Transformers. This complexity becomes particularly problematic when dealing with long sequences, such as high-resolution images or videos, as it consumes excessive computational resources and processing time. To address this challenge, researchers from the National University of Singapore have introduced MambaOut, a novel architecture that aims to streamline visual models while maintaining or even improving their performance.
The Challenge of Attention Mechanism in Transformers
The attention mechanism in Transformers plays a crucial role in capturing the contextual relationships between different elements of a sequence. It allows the model to assign different weights to different parts of the input, enabling it to focus on the most relevant information for the task at hand. However, the quadratic complexity of this mechanism poses computational challenges, especially when dealing with long sequences.
To overcome this challenge, various token mixers with linear complexity have been proposed, including dynamic convolution, Linformer, Longformer, and Performer. These models aim to reduce the computational burden of the attention mechanism while maintaining its effectiveness. Additionally, RNN-like models such as RWKV and Mamba have been developed to efficiently handle long sequences. These models leverage structured state space models (SSM) to improve performance in visual recognition tasks.
Introducing MambaOut: A Simplified Architecture
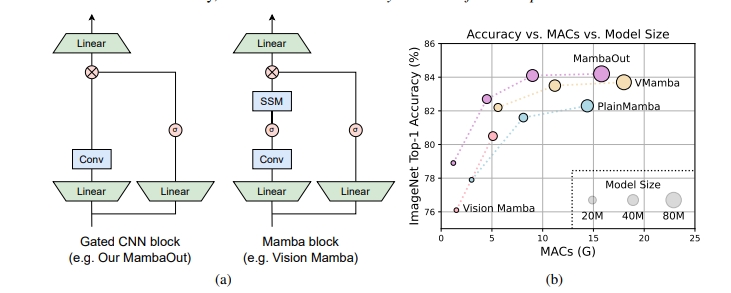
MambaOut, introduced by the researchers from the National University of Singapore, is an architecture derived from the Gated CNN block. Its primary objective is to evaluate the necessity of Mamba, a state space model, for vision tasks. Unlike traditional Mamba models, MambaOut removes the SSM component, simplifying the architecture while aiming to maintain the performance.


The MambaOut architecture leverages Gated CNN blocks and integrates token mixing through depthwise convolution. This approach allows MambaOut to achieve a lower computational complexity compared to traditional Mamba models. By stacking these blocks, MambaOut constructs a hierarchical model similar to ResNet, enabling efficient handling of various visual recognition tasks.
Achieving Improved Accuracy with MambaOut
To assess the performance of MambaOut, the researchers implemented the architecture using PyTorch and timm libraries. The models were trained on TPU v3 with a batch size of 4096 and an initial learning rate of 0.004. The training scheme followed DeiT without distillation and incorporated data augmentation techniques such as random resized crop, horizontal flip, as well as regularization techniques like weight decay and stochastic depth.
Empirical results demonstrate that MambaOut surpasses all visual Mamba models in ImageNet image classification. Specifically, MambaOut achieves a top-1 accuracy of 84.1%, outperforming LocalVMamba-S by 0.4% while utilizing only 79% of the Multiply-Accumulate Operations (MACs). Even the smaller variant of MambaOut, MambaOut-Small, achieves an accuracy of 84.1%, which is 0.4% higher than LocalVMamba-S, while requiring only 79% of the MACs.
However, it is important to note that MambaOut still lags behind state-of-the-art models like VMamba and LocalVMamba in terms of detection and segmentation tasks. In object detection and instance segmentation on COCO, MambaOut falls short by 1.4 APb and 1.1 APm, respectively. These results suggest that while MambaOut simplifies the architecture for image classification, the strengths of the Mamba model lie in handling long-sequence tasks such as object detection and segmentation.
Implications and Future Research
The introduction of MambaOut and its superior performance in image classification tasks highlight the potential of Mamba for specific visual recognition tasks. While MambaOut streamlines the architecture, it also reveals that the complexities introduced by Mamba are indeed necessary for achieving high performance in tasks with long-sequence characteristics.
The findings from this research encourage further exploration of Mamba’s application in long-sequence visual tasks. Optimizing vision models by leveraging the strengths of Mamba has the potential to enhance both accuracy and efficiency. Future research could focus on incorporating Mamba into more advanced architectures, exploring its potential in areas such as video understanding and multi-modal tasks.
In conclusion, MambaOut presents a promising avenue for improving visual models by streamlining their architectures. While MambaOut excels in image classification, the study emphasizes the importance of Mamba for tasks involving long sequences. This research contributes to the ongoing efforts in the field of computer vision, guiding future research directions towards optimizing vision models for improved accuracy and efficiency.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰