SWE-Perf: TikTok’s Groundbreaking Benchmark for Repository-Level Code Performance Optimization
Introduction
As AI models increasingly integrate into the software development workflow, a new frontier emerges: performance optimisation at the repository level. Traditional benchmarks have focused on code correctness, bug fixing, or single-function improvements. However, optimizing large-scale, real-world codebases for performance remains a largely uncharted challenge for large language models (LLMs). Addressing this gap, researchers from TikTok have introduced SWE-Perf, the first benchmark explicitly designed to evaluate how well LLMs can optimize code performance across entire repositories.
Unlike prior efforts that target small-scale transformations, SWE-Perf aims to systematically evaluate LLMs on complex, multi-file, context-rich tasks, bringing us closer to a future where AI agents contribute meaningfully to production-grade software performance improvements.
Why Performance Optimization Needs a New Benchmark
While recent years have seen major breakthroughs in code generation, bug fixing, and refactoring thanks to LLMs, performance optimization remains a harder nut to crack, especially in large, modular repositories. Optimizing performance isn’t about isolated syntax improvements; it demands a deep understanding of:
- Cross-function dependencies
- Systemic bottlenecks
- Data access patterns
- Computational complexity
Most benchmarks today (such as SWE-Bench, CodeContests, or HumanEval) assess correctness or function-level improvements, which only partially reflect the true demands of software performance optimization in real-world development environments.
SWE-Perf fills this gap by shifting the evaluation to the repository level, introducing tests that assess how well models can detect, reason about, and fix performance bottlenecks in a complex system.
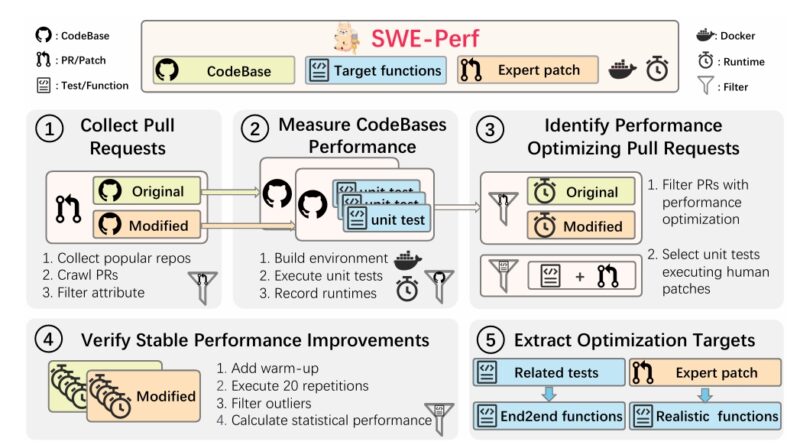
How SWE-Perf Is Built: A Closer Look at the Dataset
The SWE-Perf benchmark is constructed from over 100,000 GitHub pull requests, filtered to identify real-world patches that resulted in statistically significant performance improvements. After rigorous vetting and validation, the final dataset includes:
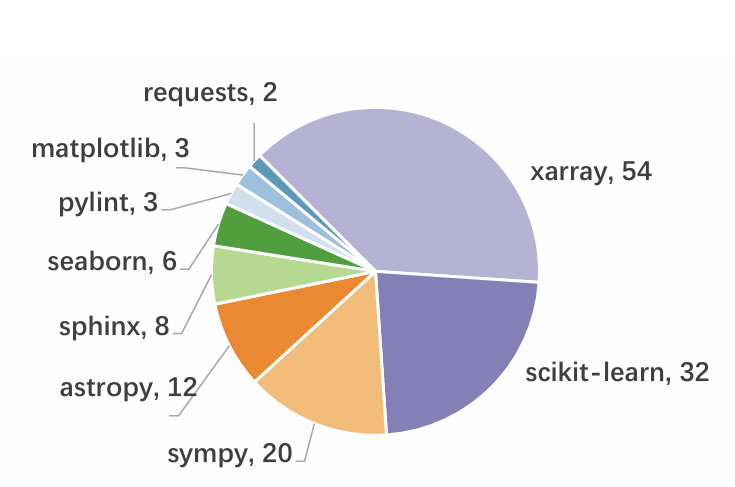
- 140 curated optimization examples across 9 open-source repositories
- Both pre- and post-optimization codebases
- Oracle-level and repo-level target function annotations
- Verified unit tests for functionality validation
- Dockerized environments for reproducible benchmarks
Key Design Principles
- Expert-Verified Patches: Each optimization instance is backed by human-authored patches validated for performance improvement using statistical testing (Mann–Whitney U test, p < 0.1).
- Reproducibility: Every instance includes test harnesses and Docker environments, allowing researchers and developers to measure performance gains consistently.
- Dual Settings
SWE-Perf supports two key evaluation paradigms:- Oracle Setting: Provides only the performance-critical function and file to the LLM.
- Realistic Setting: Provides the entire repository and leaves identification and optimization to the model—more aligned with real-world workflows.
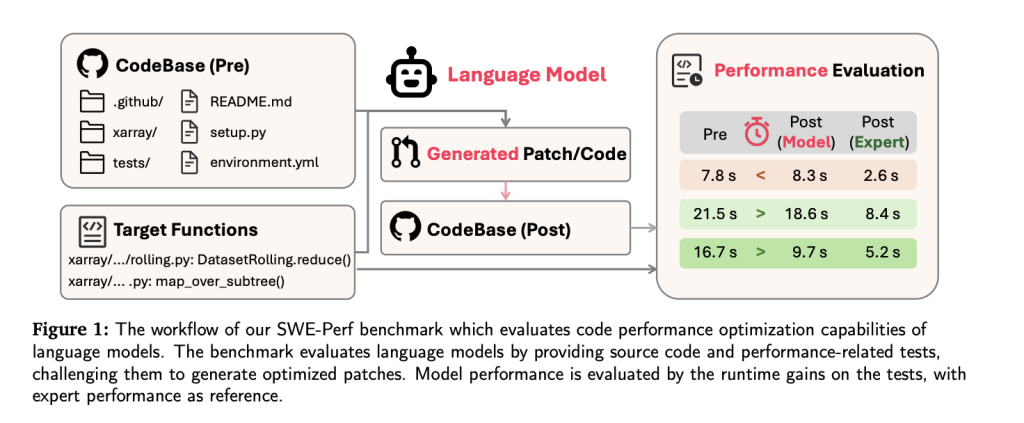
Evaluation Framework: More Than Just Accuracy
SWE-Perf defines a three-part evaluation to assess LLM performance holistically:
| Metric | What It Measures |
|---|---|
| Apply | Can the model-generated patch be applied cleanly? |
| Correctness | Do all unit tests pass after applying the patch? |
| Performance | Does the patch deliver statistically measurable speedup? |
Unlike benchmarks that reduce everything to a single score, SWE-Perf reports each metric independently, offering granular insights into where models succeed or struggle.
Benchmarking Results: How Do Current Models Perform?
The SWE-Perf team evaluated a range of top-performing LLMs, including GPT-4o, Claude 3.7, Gemini 2.5 Pro, and human-authored patches as a baseline.
| Model | Setting | Performance Gain (%) |
|---|---|---|
| Claude-4-opus | Oracle | 1.28% |
| GPT-4o | Oracle | 0.60% |
| Gemini-2.5-Pro | Oracle | 1.48% |
| Claude-3.7 (Agentless) | Realistic | 0.41% |
| Claude-3.7 (OpenHands) | Realistic | 2.26% |
| Human Expert (Baseline) | — | 10.85% |
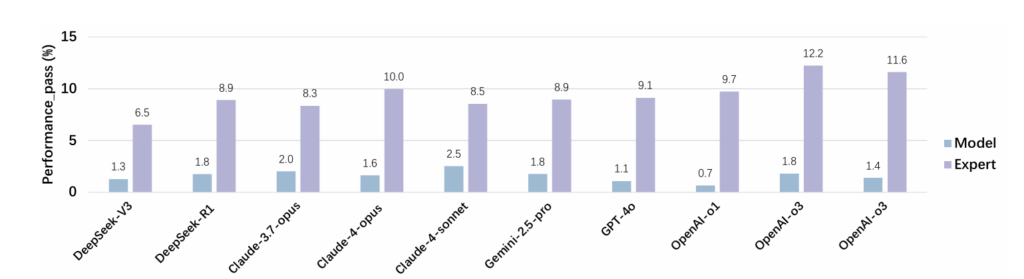
Key Takeaways:
- Human developers still outperform all LLMs by a significant margin.
- Agent-based systems (like OpenHands, based on Claude 3.7-sonnet) outperform prompt-based or pipeline approaches in realistic settings.
- Model performance degrades in long-runtime or multi-function scenarios, exposing limitations in scalability and contextual reasoning.
- LLMs often rely on surface-level changes, such as tweaking imports or adding cache layers, whereas human experts address deep semantic bottlenecks involving data structures, algorithms, and execution order.
Why SWE-Perf Is a Landmark Contribution
1. Repository-Scale Focus
SWE-Perf goes beyond individual file or function benchmarks, capturing the multi-level complexity of real-world software development.
2. Grounded in Real-World Performance
By requiring statistically significant speedups, SWE-Perf filters out placebo patches and ensures that evaluated changes have measurable impact on runtime.
3. Encourages Agentic AI Research
The results show that autonomous agents, capable of tool use, search, planning, and self-evaluation, are better equipped to handle performance optimization tasks, highlighting new directions for LLM system design.
4. Benchmark Transparency
By keeping evaluation metrics disaggregated, SWE-Perf allows researchers to make more informed tradeoffs—for example, prioritizing correctness over performance, or vice versa.
Future Directions
SWE-Perf opens the door to a range of research questions and engineering applications:
- How can agent-based systems scale to larger codebases without performance drops?
- Can LLMs be trained or fine-tuned explicitly for repository-level performance optimization?
- How might IDE integrations and code profilers guide LLM-based optimizations more effectively?
- What role do hybrid workflows (AI + human) play in achieving state-of-the-art performance improvements?
As performance optimization becomes a critical concern in enterprise software systems, tools and benchmarks like SWE-Perf will shape how LLMs contribute meaningfully in production-grade environments.
Conclusion
SWE-Perf is a transformative benchmark that fills a crucial gap in the AI + software development ecosystem. By focusing on performance optimization across repositories, it challenges current LLMs and exposes their limitations, especially in high-complexity, long-context environments.
While no current LLM matches human expertise, SWE-Perf sets a clear research trajectory. It not only enables rigorous evaluation but also encourages innovation in agentic architectures, multi-step planning, and realistic optimization tasks.
As LLMs become increasingly embedded in developer workflows, SWE-Perf will serve as a foundational benchmark for measuring true productivity, beyond syntax and into performance-critical engineering.
Check out the Paper, GitHub Page and Project. All credit for this research goes to the researchers of this project. Explore one of the largest MCP directories created by AI Toolhouse containing over 4500+ MCP Servers: AI Toolhouse MCP Servers Directory