Can We Drastically Reduce AI Training Costs? This AI Paper from MIT, Princeton, and Together AI Unveils How BitDelta Achieves Groundbreaking Efficiency in Machine Learning
Artificial Intelligence (AI) has revolutionized numerous industries, from healthcare to finance and everything in between. However, one major challenge in AI development is the high cost associated with training models. The computational resources required for training large-scale AI models can be extensive, leading to significant expenses. But can we drastically reduce AI training costs? A recent AI paper from MIT, Princeton, and Together AI unveils how BitDelta achieves groundbreaking efficiency in machine learning, providing a potential solution to this problem.
The Challenge of AI Training Costs
Training AI models involves two main phases: pre-training and fine-tuning. Pre-training requires substantial computational resources to train models on vast datasets, while fine-tuning adds specific task-related information to the pre-trained model. While pre-training is computationally expensive, fine-tuning is relatively less resource-intensive, as it builds on the existing knowledge of the pre-trained model.
Researchers have been exploring various techniques to reduce the cost of AI training. Quantization methods, such as rescaling activations and decomposing matrix multiplications, aim to reduce memory usage and latency in large language models (LLMs). Pruning methods, on the other hand, induce sparsity by zeroing certain parameter values, leading to more efficient models. Parameter-efficient fine-tuning (PEFT) approaches, like adapter layers and Low-Rank Adaptation (LoRA), reduce trainable parameters during fine-tuning, improving efficiency without compromising accuracy.
BitDelta: A Breakthrough in AI Training Efficiency
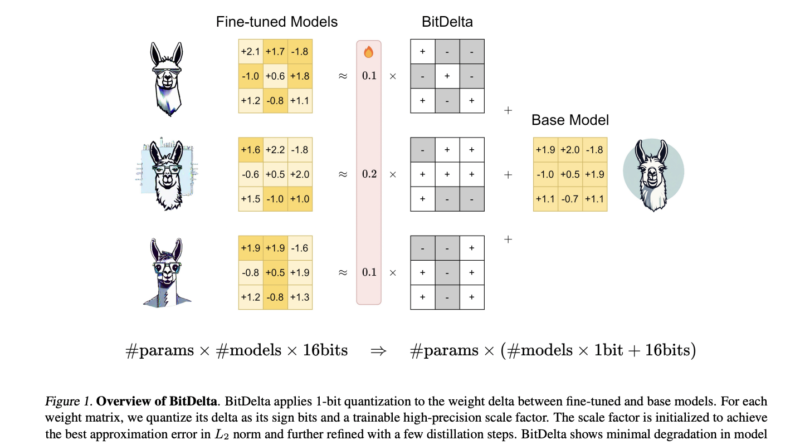
In a recent AI paper from MIT, Princeton, and Together AI, researchers propose BitDelta, a method that achieves groundbreaking efficiency in machine learning training. BitDelta effectively quantizes fine-tuning deltas to 1 bit without sacrificing performance, suggesting potential redundancy in fine-tuning information and offering implications for multi-tenant serving and storage efficiency.


The process employed by BitDelta involves a two-stage quantization of fine-tuning deltas in LLMs. Firstly, each weight matrix delta is quantized into a binary matrix multiplied by a scaling factor, initialized as the average absolute value of the delta. Secondly, scaling factors are calibrated via model distillation over a small dataset, while keeping the binary matrices frozen. This approach significantly reduces GPU memory requirements by over 10 times, thereby enhancing generation latency in multi-tenant environments.
Evaluation and Performance of BitDelta
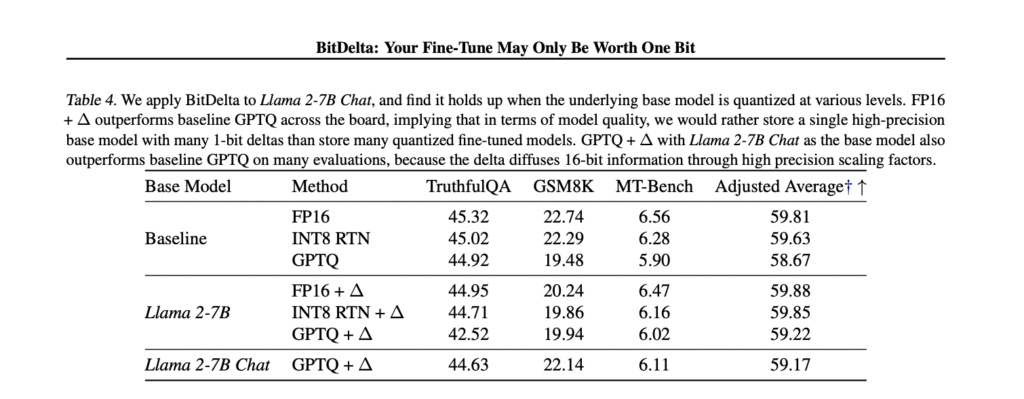
BitDelta is evaluated against original uncompressed models, as well as 8-bit RTN and 4-bit GPTQ quantization methods. The evaluation covers Llama-2 and Mistral model families, and BitDelta consistently performs well on high-margin metrics, often outperforming the baselines [^1]. It accurately preserves fine-tuned information, even surpassing GPTQ when applied to quantized base models, showcasing its effectiveness and versatility across different model sizes and fine-tuning techniques.
Implications and Benefits of BitDelta
The efficiency achieved by BitDelta has significant implications for AI model deployment and resource utilization. By compressing multiple fine-tuned models into one base model and multiple deltas, BitDelta reduces the need for extensive storage and computational resources. This allows for shared server usage and significantly reduces GPU memory consumption and inference latency.
With the reduction in AI training costs, organizations can allocate resources more efficiently and potentially develop more specialized models tailored to specific requirements. This opens up new possibilities in various industries, including healthcare, finance, and autonomous systems, where AI plays a crucial role.
Conclusion
Reducing AI training costs has been a longstanding challenge in the field of machine learning. However, the recent breakthrough achieved by BitDelta, as unveiled in the AI paper from MIT, Princeton, and Together AI, offers a promising solution. By effectively quantizing fine-tuning deltas to 1 bit without sacrificing performance, BitDelta significantly reduces GPU memory requirements and improves generation latency in multi-tenant environments. This approach paves the way for more efficient model deployment and resource utilization in machine learning applications.
As AI continues to advance and become more integral to various industries, innovations like BitDelta bring us closer to a future where AI training costs are drastically reduced, enabling organizations to harness the power of AI more effectively and efficiently.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰