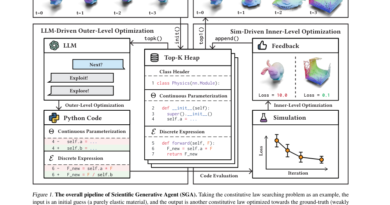
FAMO: A Fast Optimization Method for Multitask Learning (MTL) that Mitigates the Conflicting Gradients using O(1) Space and Time
Multitask learning (MTL) is a powerful approach that involves training a single model to perform multiple tasks simultaneously. By leveraging shared information and capturing task dependencies, MTL can enhance the performance of individual tasks. However, optimizing across tasks in MTL can be challenging, especially when the tasks progress unevenly or have conflicting gradients. In such cases, traditional optimization methods may lead to suboptimal performance.
To address the under-optimization problem in MTL, researchers from The University of Texas at Austin, Salesforce AI Research, and Sony AI have introduced a new optimization method called Fast Adaptive Multitask Optimization (FAMO). FAMO is designed to mitigate the conflicting gradients and achieve balanced loss decrease across tasks while maintaining computational efficiency.
The Challenge of Under-Optimization in Multitask Learning
In multitask learning, the goal is to optimize a model that performs well on multiple tasks simultaneously. However, traditional optimization methods that optimize the average loss across tasks may not work well when tasks progress at different rates or have conflicting gradients.
Explore 3600+ latest AI tools at AI Toolhouse 🚀
When tasks progress unevenly, optimizing the average loss may lead to some tasks being under-optimized, resulting in suboptimal performance. This becomes more pronounced when the tasks have conflicting gradients, where the optimization process for one task negatively affects the optimization of other tasks.
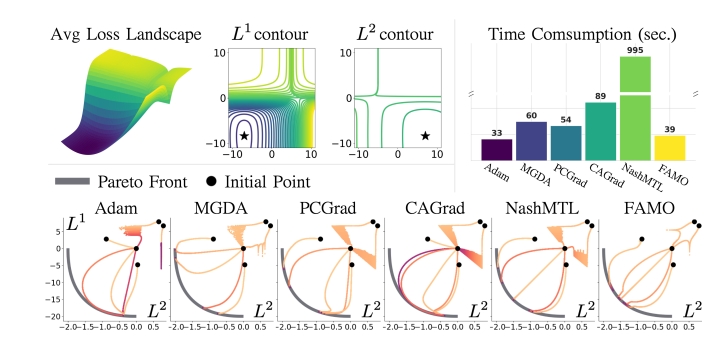
Existing solutions to mitigate the under-optimization problem involve gradient manipulation techniques. These methods compute a new update vector to the average loss, ensuring that all task losses decrease more evenly. However, these approaches can become computationally expensive as the number of tasks and model size increase. This is due to the need to compute and store all task gradients at each iteration, resulting in significant space and time complexities.
Introducing FAMO: A Fast Optimization Method for Multitask Learning
FAMO, the Fast Adaptive Multitask Optimization method, addresses the under-optimization problem in MTL without the computational burden associated with existing gradient manipulation techniques. FAMO achieves a balanced loss decrease across tasks using only O(1) space and time per iteration.
The key idea behind FAMO is to dynamically adjust task weights based on the observed losses, instead of computing all task gradients. By leveraging loss history, FAMO ensures that all tasks progress at a similar rate, mitigating the under-optimization problem. This dynamic adjustment of task weights allows FAMO to achieve a balanced loss decrease across tasks, enhancing the overall performance of the MTL model.
To achieve computational efficiency, FAMO amortizes computation over time. Instead of computing all task gradients at each iteration, FAMO only requires the computation of the average gradient, which is more efficient and requires less computational overhead. This significantly reduces the space and time complexities associated with gradient manipulation techniques, making FAMO a computationally efficient optimization method for MTL.
Benefits and Performance of FAMO
The introduction of FAMO brings several benefits to the field of multitask learning. By dynamically adjusting task weights and achieving a balanced loss decrease, FAMO improves the overall performance of MTL models. Additionally, FAMO offers significant computational efficiency improvements compared to existing gradient manipulation techniques.
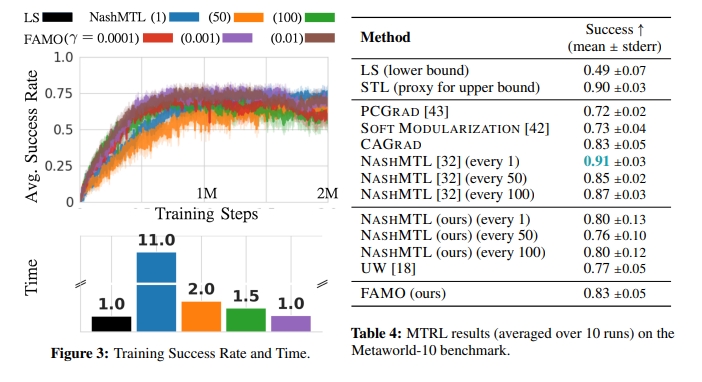
Empirical experiments conducted to evaluate FAMO across various MTL benchmarks have shown its comparable or superior performance to existing methods. FAMO consistently performs well in supervised and reinforcement learning benchmarks, showcasing its effectiveness and efficiency. Compared to state-of-the-art methods like NASHMTL, FAMO demonstrates significant improvements in training time and efficiency.
Furthermore, FAMO’s robustness has been highlighted through an ablation study on the regularization coefficient γ. The study shows that FAMO performs well across different settings, except for specific cases where tuning γ could stabilize performance. This demonstrates FAMO’s adaptability and effectiveness across diverse MTL scenarios.
Conclusion
FAMO, the Fast Adaptive Multitask Optimization method, addresses the challenges of under-optimization in multitask learning. By dynamically adjusting task weights and achieving a balanced loss decrease across tasks, FAMO improves the overall performance of MTL models. Moreover, FAMO offers significant computational efficiency improvements, making it a valuable contribution to the field of multitask learning.
With its ability to mitigate conflicting gradients and optimize across tasks using O(1) space and time, FAMO paves the way for more scalable and effective machine learning models. As researchers continue to explore and refine MTL techniques, FAMO stands out as a fast optimization method that enhances the performance of multitask learning models while maintaining computational efficiency.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰