Guiding AI with Human Values: Upstage AI’s sDPO Method Enhances Language Models for Ethical Alignment
Have you ever wished for an AI assistant who possesses immense knowledge and understands and respects your values, ethics, and preferences? Imagine having an AI companion that operates with the same moral compass as you, never lying, misleading, or acting against your interests. This may sound like a fantasy, but researchers at Upstage AI have developed an innovative technique called “stepwise Direct Preference Optimization” (sDPO) that brings us closer to achieving this harmony between artificial and human intelligence.
The Challenge of Aligning Language Models with Human Values
Large language models (LLMs) are the driving force behind AI assistants like ChatGPT. They are incredibly capable but sometimes respond in ways that seem at odds with what a human would prefer. This misalignment between the AI model and human values poses several challenges.
Explore 3600+ latest AI tools at AI Toolhouse 🚀
Firstly, it can lead to AI-generated outputs that may be factually incorrect, biased, or insensitive. For example, an AI assistant might provide medical advice that contradicts established scientific knowledge or promote harmful stereotypes. These issues highlight the need for aligning AI models with human values to ensure ethical and responsible AI deployment.
Secondly, an AI model that doesn’t align with human values may not be trusted or accepted by users. If the AI assistant frequently provides responses that go against the user’s preferences or values, it can lead to frustration, distrust, and disengagement.
Introducing Upstage AI’s sDPO Approach
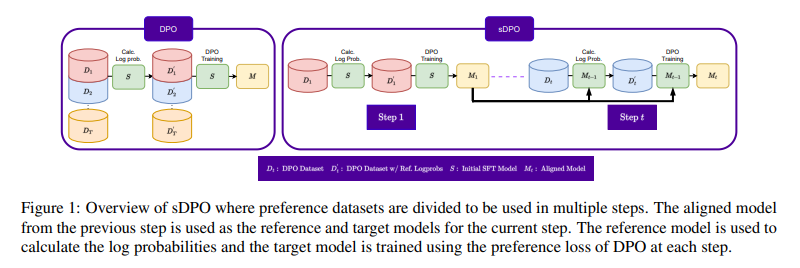
Upstage AI’s sDPO approach addresses the challenge of aligning language models with human values. It leverages a curriculum-style learning process to gradually instill human preferences into the model. Let’s dive into the key steps involved in sDPO:
- Collecting preference data: The researchers start by collecting data that captures human preferences on what constitutes good versus bad responses to questions. This data serves as a basis for training the AI model.
- Chunking the preference data: The collected preference data is split into manageable chunks. This allows the AI model to learn incrementally and fine-tune its alignment with human values.
- Stepwise fine-tuning: In the first phase, the AI model is trained on the first chunk of preference data while using its original, unrefined self as a reference point. This enables the model to become slightly more aligned with human preferences than before. In the next phase, this more aligned version of the model becomes the new reference point and is trained on the second chunk of preference data, pushing it further toward alignment. This stepwise process continues until all the preference data has been consumed.
By following this iterative approach, the AI model is nudged higher and higher, climbing towards better harmony with human values and ethics. Each step in the process refines the model’s understanding of human preferences and aligns it more closely with our values.
Impressive Results and Superior Performance
The results of the sDPO experiments conducted by Upstage AI are truly remarkable. By fine-tuning the SOLAR language model, which has 10.7 billion parameters, using sDPO and leveraging preference datasets like OpenOrca and Ultrafeedback Cleaned, the researchers achieved outstanding performance.
On the HuggingFace Open LLM Leaderboard, a benchmark for evaluating LLM performance, the sDPO-aligned SOLAR model achieved an average score of 74.31 across multiple tasks, outperforming even larger models like Mixtral 8x7B-Instruct-v0.1. This demonstrates the effectiveness of sDPO in aligning language models with human values and preferences.
Notably, the sDPO-aligned SOLAR model excelled in the TruthfulQA task, scoring an impressive 72.45. This showcases the model’s unwavering commitment to truthfulness, a core human value. It’s crucial to have AI models that prioritize truth and accuracy, as they play a significant role in providing reliable information to users.
The Path to Aligning AI with Human Values
While sDPO has shown promising results, the journey to aligning AI with human values is ongoing. Researchers must continue to deepen their understanding of dataset characteristics and their impact on performance. This ongoing research will pave the way for further advancements in aligning language models with human values and ethics.
Upstage AI’s sDPO approach serves as a testament to the potential of effective alignment tuning. It shows that even smaller language models can achieve superior performance when equipped with the ability to refine their understanding of human values. This opens up possibilities for creating AI systems that not only possess remarkable capabilities but also embody the very values and principles that define our humanity.
Imagine a future where AI systems are not only knowledgeable but also reflect our aspirations, hopes, and desires. With groundbreaking techniques like sDPO, that future may be closer than we think. Upstage AI’s commitment to aligning language models with human values brings us one step closer to a world where AI and human intelligence coexist harmoniously, making AI assistants trusted companions in our everyday lives.
In conclusion, Upstage AI’s sDPO approach represents a significant milestone in aligning language models with human values and preferences. By gradually instilling human preferences into AI models, sDPO enables them to respond in ways that are more aligned with our values and ethics. As research in this field progresses, we can look forward to even more sophisticated AI systems that not only possess immense knowledge but also embody the principles that matter most to us.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰