Meet CompAgent: A Training-Free AI Approach for Compositional Text-to-Image Generation with a Large Language Model (LLM) Agent as its Core
Text-to-image generation is a rapidly evolving field within computer vision and artificial intelligence. It involves creating visual images from textual descriptions and blending natural language processing and graphic visualization domains. This interdisciplinary approach has significant implications for various applications, including digital art, design, and virtual reality.
Large language models (LLMs) like GPT-4 and Llama have capabilities in natural language processing and are being adopted as agents for complex tasks. However, they must improve when dealing with complex scenarios involving multiple objects and their intricate relationships. This limitation highlights the need for a more sophisticated approach to accurately interpreting and visualizing elaborate textual descriptions.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Introducing CompAgent
Researchers from Tsinghua University, the University of Hong Kong, and Noah’s Ark Lab have introduced CompAgent, a training-free AI approach for compositional text-to-image generation with a large language model (LLM) agent as its core [1]. CompAgent leverages the power of LLMs to generate detailed and contextually relevant images based on textual descriptions.
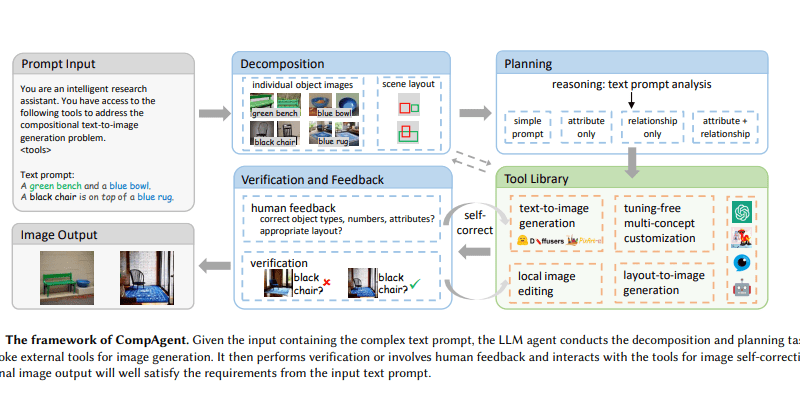
One of the standout features of CompAgent is its adoption of a divide-and-conquer strategy. By breaking down complex textual descriptions into smaller, more manageable components, CompAgent enhances the controllability and accuracy of image synthesis. This approach allows for better representation of multiple objects and their relationships within a scene.
How CompAgent Works
CompAgent utilizes a multi-concept customization tool, a layout-to-image generation tool, and a local image editing tool to generate images based on textual descriptions. These tools work in conjunction with the LLM agent to ensure accurate and contextually relevant image outputs.
The multi-concept customization tool allows CompAgent to customize images based on existing object images and input prompts. By combining and modifying existing object images, CompAgent can create unique and realistic images that align with the given textual descriptions.
The layout-to-image generation tool is responsible for managing object relationships within a scene. It ensures that the spatial arrangement of objects accurately reflects their textual descriptions. This tool plays a crucial role in generating coherent and visually appealing images.
The local image editing tool allows for precise attribute correction using segmentation masks and cross-attention editing. This tool is particularly useful when fine-tuning specific attributes of objects or adjusting scene layouts. It ensures that the generated images meet the desired criteria and maintain consistency with the given textual descriptions.
Enhancing Text-to-Image Generation
CompAgent’s divide-and-conquer strategy, combined with its comprehensive set of tools, enhances the capability of text-to-image generation. By breaking down complex textual descriptions and utilizing specialized tools for customization, layout generation, and image editing, CompAgent achieves exceptional performance in generating accurate and contextually relevant images.
In fact, CompAgent has demonstrated remarkable results in comparison to previous methods. It achieves a 48.63% 3-in-1 metric, surpassing previous methods by more than 7%. Additionally, it has achieved over 10% improvement in compositional text-to-image generation on T2I-CompBench, a benchmark for open-world compositional text-to-image generation. These results highlight the effectiveness of CompAgent in addressing the challenges of object type, quantity, attribute binding, and relationship representation in image generation.
The Implications of CompAgent
CompAgent represents a significant achievement in text-to-image generation. It solves the problem of generating images from complex textual descriptions and opens new avenues for creative and practical applications.
The ability of CompAgent to accurately render multiple objects with their attributes and relationships in a single image is a testament to the advancements in AI-driven image synthesis. It addresses existing challenges in the field and paves the way for new possibilities in digital imagery and AI integration.
With further advancements in LLM technology and the adoption of strategies like CompAgent, text-to-image generation will continue to evolve. The ability to generate realistic and contextually relevant images from textual descriptions has immense potential in fields such as virtual reality, design, and digital art.
In conclusion, CompAgent is a training-free AI approach that leverages a large language model (LLM) agent to generate compositional text-to-image generation. By adopting a divide-and-conquer strategy and utilizing specialized tools, CompAgent enhances the accuracy and controllability of image synthesis. Its exceptional performance in generating accurate and contextually relevant images demonstrates its effectiveness in addressing complex textual descriptions. CompAgent represents a significant advancement in text-to-image generation and opens new possibilities for creative and practical applications.
Don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰